

2.10. Пример разрядно-модульного матричного процессора simd-архитектуры (параллельный процессор для обработки двухмерных изображений, передаваемых из космоса).
Процессорная матрица: 16384 ПЭ; один ПЭ имеет локальную память 1024 бит.


Разрядно-модульная матричная окмд
ПЭ связан с четырьмя соседними элементами. ПЭ однобитовые, коды поступают последовательные, все элементы настраиваются на выполнение одной команды. Переходная память для стыковки и подготовки форматов.

2.11. Особенности реализации мультимедийных алгоритмов на основе архитектур simd в современных простейших микропроцессорах
2.11.1. Pentium MMX (простейшая организация SIMD-архитектуры в микропроцессоре)
Система команд Pentium MMX имеет 57 специальных дополнительных команд, ориентированных на мультимедийные алгоритмы; введено специальное дополнение в виде устройства ММХ. Добавлено: 8 ММХ регистров, появились новые команды. Добавлены типы данных (8 упакованных байт в 64 битовом пакете, четыре 16 битовых слова, упакованные двойные слова по 32 бита (два слова) и учетверенное слово 64 бита).
Пример выполнения команды ММХ.
Выполнение умножения с накоплением четырех 16 разрядных слов на другие 4 слова, при этом используются 3 команды MMX.
На Pentium-е без использования MMX требуется 12 команд для выполнения таких действий. В Pentium-е MMX реализуется параллельно-конвейерный принцип.
Команды:
1. Загрузка операндов в ММХ регистр:
16р А3 |
16р А2 |
16р А1 |
16р А0 |
2. Умножение и сложение содержимого ММХ регистра и памяти:
А3 |
А2 |
А1 |
А0 |
ММХ регистр
В3 |
В2 |
В1 |
В0 |
const
А3*В3+А2*В2 |
А1*В1+А0*В0 |
3. Сложение результата с содержимым аккумулятора:
АСС1 |
АСС2 |
В итоге в аккумуляторе накапливаются результаты.
2.11.2. Особенности реализации SIMD в микропроцессоре PowerPC (G5)
Имеется 128-и разрядный блок векторной обработки, который параллельно функционирует с имеющимся целочисленным блоком и блоком обработки с плавающей точкой.
Данные, которые могут обрабатываться: 16 8-и битовых целых (и символы) или 8 16-и битовых целых (и символы), или 4 32-х битовых целых чисел или чисел с плавающей запятой.
В блоке векторной обработки предусматривается 32 регистра по 128 разрядов (как регистры общего назначения). Их можно использовать для хранения исходных данных.
Команды могут содержать до 3-х входных операндов и один выходной. Общее количество команд – 162, включая векторную обработку.

Могут реализовываться не только массовые скалярные операции, но и сложные векторные операции (скалярное умножение векторов, матриц) и операции, работающие с несколькими регистрами.
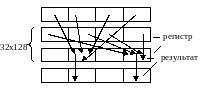
2.12. Процессоры со многими алу
Процессоры имеют гранулярность на уровне операций. АЛУ обслуживаются регистром, а не общей памятью.
Особенность системы: множество одновременно работающих АЛУ; используется многопортовый регистровый файл.

Для управления n АЛУ могут использоваться длинные микрокоманды, состоящие из n полей, и каждое поле управляет отдельным АЛУ.
АЛУ может носить как универсальный по набору команд (микроинструкций), так и специализированный характер.
Данный принцип организации лежит в основе построения операционных ядер современных микропроцессоров, в частности, суперскалярных архитектур, ядер многоядерных процессоров. В основе реализации АЛУ - конвейерный принцип, на основе которого достигается получение одного результата за один такт.
Особенности организации работы современных процессоров с многими АЛУ согласуются с методологией RISK-архитектуры.