

2.8. Вычислительные модели (системы) с управлением потоком данных (потоковые машины) и редукционные машины
Особенностью потоковых машин является то, что последовательность вычислений задается не последовательностью команд, что характерно для неймановской архитектуры, а по мере готовности данных для выполнения команд. Данные загружаются в операционное устройство, если оно свободно, и для определенной команды имеются все необходимые данные.
Принципиальным отличием от неймановских машин является то, что команды выполняются не в порядке их следования, а по готовности операндов. Как только на входе операционного блока появляются данные, соответствующая команда блока захватывает эти данные и выполняется соответствующая операция. Машины, основанные на модели с потоком данных, называются потоковыми:
- отсутствие побочного эффекта;
- эффективная реализация параллельных вычислений.
Пример. a = (b+c)*(b-c). Для отображения хода процесса используются специальные «фишки». Потоковые принципы описываются с помощью графов и сетей Петри.




Такой подход используется в параллельных системах: однородных вычислительных средах (однотипные архитектуры процессоров (процессорных элементов ПЭ), настаиваемых на выполнение определенных программ; передача данных с использованием средств коммутации.

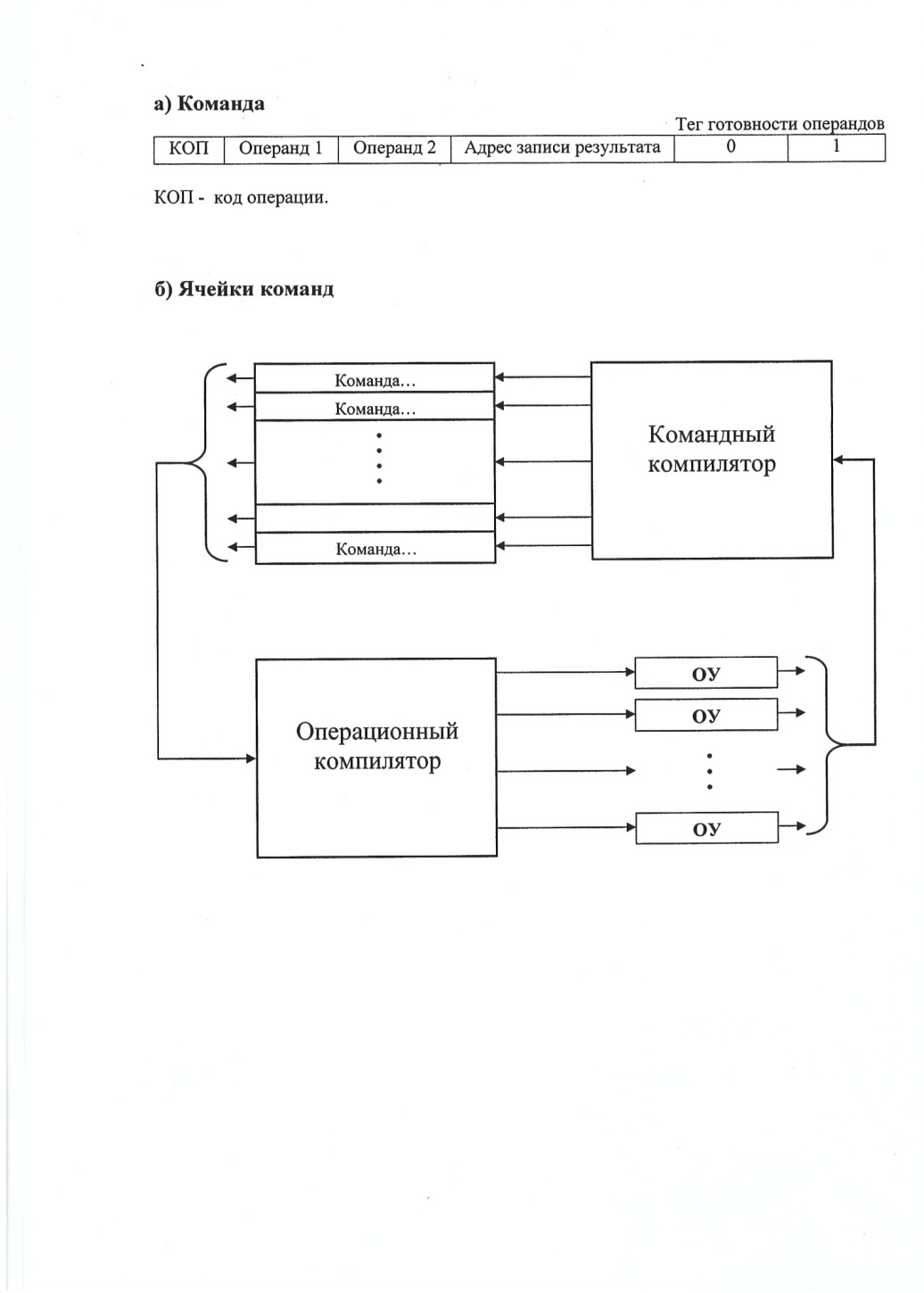
Рис.
Принцип управления вычислительным процессом на основе потока данных используется в современных микропроцессорах, в частности, в суперскалярных архитектурах (Рис.). Сущность этих процессов состоит в следующем. Команда имеет код операции, может содержать два операнда, а также имеет два разряда (теги) для идентификации наличия (готовности) операндов к вычислениям. Команды хранятся в ячейках команд. Устройство управления при обнаружении двух единиц (двух готовых операндов) в одной из команд анализирует наличие среди операционных устройств (ОУ) свободное, которое по функциональным возможностям может реализовать операцию данной команды. При наличии такого устройства код операции и коды операндов передаются через операционный компилятор в соответствующее выбранное операционное устройство. Полученный результат записывается в память по адресу, указанному в команде.
Механизм редукционных машин основан на принципе редукции, т.е. сокращения посредством перезаписи строк символов (формул) в программе или сокращения в графах.
Запуск вычислений осуществляется при необходимости получения данных.
Пример. Исходные данные: граф программы, находящийся в памяти. a = (b+c)*(b-c).
В памяти:
а )
)

b )
)
c
 )
d)
)
d)
Нет побочного эффекта. Реализуется последовательность решения математических выражений. Это направление удобно для параллельной реализации.
2.9. Матричные (векторные) процессоры (simd-архитектуры)
По классификации потоки команд - потоки данных эти архитектуры относятся к типу SIMD.
Можно выделить два основных направления:
матричный процессор с локальной памятью;
матричный процессор с общей памятью.
Матричный процессор с локальной памятью.
Имеется множество одинаковых процессорных элементов (как правило, они простые). На все процессоры одновременно поступает одна и та же команда или группа команд (SIMD). Каждый процессорный элемент использует данные из своей индивидуальной памяти (или оперативной памяти). Имеется возможность обмена данными или условиями перехода через сеть связи между процессорными элементами. Количество ПЭ – от 8-и до 16-и тысяч. Обычно ПЭ своих средств ввода-вывода не имеют.
П – память; ПЭ – процессорный элемент.

Матричный процессор с общей памятью.
МП – модуль памяти. ПЭ могут выполняться в виде отдельных процессоров, в значительной мере упрощенных; могут изготавливаться на пластине как множество ПЭ.

ПЭ-ты коммутируются сетью связи в соответствии с алгоритмом решения задачи. Каждый ПЭ настраивается на выполнение соответствующей одинаковой для всех команды или группы команд.
В современных многоядерных процессорах ПЭ являются в значительной мере высокофункциональными с развитой системой команд (например, процессоры для обработки графической информации).