

2.18. Суперкомпьютер Gray
В основе - суперскалярная с возможностями векторной реализации операций архитектура.
Структура одного процессора:
Секция управления
программой
Буферы команд
1..4
. . .




Секция регистров

Блок выработки
команд и
управляющих
сигналов




Секция
памяти и
вв/вывода
24
канала




О
З
У
Адресные
 регистры
регистры



Скалярные
 регистры
регистры
КВВ

0 1… 7



 …
…
Векторные
 регистры
регистры

Первый Gray был создан в 1976-м году, выпущен – в 78-м году. Процессор имел объем 1м3, выполнял до 250 млн. операций/сек.
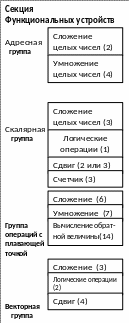
Состав Gray: 4 секции (12 устройств):
секция функциональных устройств (АЛУ);
секция регистров;
секция управления программой;
секция памяти и ввода-вывода.
4 независимые группы функциональных устройств:
адресная группа;
скалярная группа;
группа операций с плавающей запятой;
векторная группа.
АЛУ – это практически конвейерный процессор. Число сегментов в одном конвейере – до 14.
Длительность одного шага (сегмента) – 12.5 нс.
Число операций – 128. В мультипрограммном режиме могут одновременно выполняться 63 задачи. Имеется активизирующий компилятор с ФОРТРАНА, который распознает параллельные участки для векторных команд.
Большую роль играют быстрые регистры:
- адресные (А-регистры) -24-х разрядные, 8 шт.;
- скалярные (S-регистры) -64-х разр., 8 шт.;
- векторные (V-регистры) – 64 элемента*64 разр.,8 шт.
Время обращения к регистру 6 нс.
Ввод-вывод – по 24-м каналам (6*4 канала).
Gray2 – 2-х процессорный. GrayХ – MP/1 выполняет 1 млрд. операций/сек., в конфигурацию входит до 4-х процессоров. Был создан в 82-м году.
В Gary2 используется ОС типа Unix. Время реализации сегмента – 1.4нс.
2.19. Многопроцессорные системы.
В многопроцессорных системах гранулярность на уровне задач; в каждой ЭВМ свой счетчик команд. По классификации потоки-команд-потоки данных относятся к MIMD архитектурам.
Системы с общей памятью.

П – процессор, МП – модуль памяти.
Число процессоров ограничивается обстоятельствами, которые возникают при конфликтах при обращении к памяти.
От сети связи зависит эффективность всей многопроцессорной системы.
2. Системы с распределенной (индивидуальной) памятью (с коммутацией сообщений).

П – процессор, ЛП – локальная память.
В системе у каждого процессора имеется своя память и проблема конфликтов не столь актуальна.
Одна из наиболее серьезных проблем в проектировании многопроцессорных систем – необходимость использования сложных систем связи.
В идеале, для обеспечения высокой производительности и минимизации задержек при обмене информацией между процессорами и оперативным запоминающим устройством, желательно обеспечивать возможность связи в любой момент времени по принципу "каждый с каждым”, однако при построении таких систем уже при небольшом количестве процессоров сеть связи оказывается очень сложной и по оборудованию может даже превосходить другую часть системы. В случае использования сотен-тысяч процессоров нереально обеспечивать режим "каждый с каждым”. В связи с этим разработаны различные эвристические методы решения данной задачи на основе параллельно-последовательной передачи данных.
Рекомендуемая гранулярность при загрузке процессоров - на уровне задач или крупных частей задач.
Примеры способов (структур) реализации связей между процессорами.
Одношинная система.
Т аким
способом более 4-х процессоров не
подключают.
аким
способом более 4-х процессоров не
подключают.
Мультиплексная общая шина.

Матричный коммутатор.
К – сложный коммутирующий элемент.
– сложный коммутирующий элемент.
Разновидности сетей:
Полная сеть. Звездообразная сеть. Матричная сеть.



Матричная сеть типа «тор». Сеть типа «цепочка».


Кольцевая сеть.

Древовидная сеть.

Гиперкуб.
а) 22 процессоров, 2 связи на входе каждого процессора, не более двух участков для перехода от одного процессора к другому.

б) 23 вершин (процессоров). 3 связи на входе каждого процессора. Чтобы перейти из одной вершины в любую другую, нужно пройти не более 3-х участков.

В общем случае: 2L – количество процессоров, L связей на входе каждого процессора. Чтобы перейти из одной вершины в любую другую, нужно пройти не более L-х участков.
При формировании трафика связи между двумя процессорами эффективно используется особенность нумерации расположения соседних процессоров: их номера всегда отличаются только в значении одного из битов.