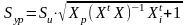Хід роботи
Для множинної лінійної регресії має місце стохастична лінійна залежність випадкового показника Y від декількох факторів X1, . X2, …, Xm, яку можна представити моделлю:
 ,
,
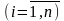
Де п кількість вимірювань, т кількість факторів,
 ,
,
 ,
,
 ,
…,
,
…,
 – параметри моделі,
– параметри моделі,
 ,
,
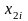 ,
…,
,
…,
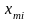 та
та
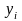 – значення факторів та показника для
деякого і-того
вимірювання,
– значення факторів та показника для
деякого і-того
вимірювання,
 випадкове
відхилення від «лінії регресії».
випадкове
відхилення від «лінії регресії».
Задача регресійного аналізу полягає у тому, щоби визначити параметри регресії
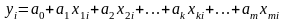 ,
,
встановити
адекватність лінійної моделі, знайти
довірчу зону регресії, обчислити
прогнозоване значення показника та
його довірчий інтервал. Таку задачу
розв’язують методом найменших квадратів
у матричній формі. Здобуті
МНК значення параметрів
 ,
,
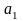 ,
,
 ,
…,
,
…,
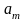 – є статистичними оцінками
справжніх невідомих параметрів моделі.
– є статистичними оцінками
справжніх невідомих параметрів моделі.
Матрична форма моделі має вид:

або
Y=XA+U
Таким чином маємо матриці:
 –
показника
–
показника 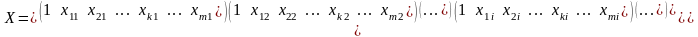 – факторів
– факторів
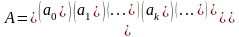 –
параметрів
регресії
–
параметрів
регресії 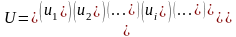 – залишків
– залишків
Матрицю факторів доповнює перший стовпчик із значеннями фіктивного фактору Х0, які завжди дорівнюють 1.
Оператор оцінювання параметрів знаходимо за формулою:
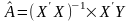
Коефіцієнт детермінації обчислюють в матричній формі:

або
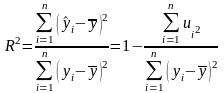
 – середнє
значення показника.
– середнє
значення показника.
Множинний коефіцієнт кореляції
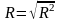
Критерієм тесту на адекватність моделі вибирають F- розподіл Фішера:

Розрахункове
значення
 порівнюють із табличним
порівнюють із табличним
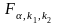 .
У випадку
.
У випадку
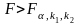 – із значимістю α модель вважають
адекватною. Тут k1=m,
та k2=n–m–1
відповідні ступені вільності.
– із значимістю α модель вважають
адекватною. Тут k1=m,
та k2=n–m–1
відповідні ступені вільності.
Для множинної регресії перевіряють параметри регресії на значущість за допомогою критерію Стьюдента
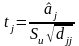
де
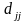 - j-й
діагональний елемент матриці похибок
- j-й
діагональний елемент матриці похибок
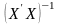 .
.
Якщо │tj│>tα,k, то можна вважати, що вплив відповідного фактора значний (α – рівень значущості, k=n–m–1)
Надійні
інтервали базисних даних обчислюють
після знаходження дисперсії
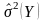 за допомогою формули дисперсії для
кожного значення вимірювання:
за допомогою формули дисперсії для
кожного значення вимірювання:

Тут
маємо:
 – рядок матриці факторів,
– рядок матриці факторів,
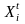 транспонований
транспонований
 ,
,
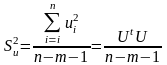 – дисперсія
залишків.
– дисперсія
залишків.
Надійні
інтервали показника знаходять як:
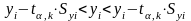 ,
де
,
де
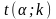 – табличне значення функції Стьюдента,
α – рівень значущості, k=n–m–1
– табличне значення функції Стьюдента,
α – рівень значущості, k=n–m–1
Дисперсію
прогнозованого значення показника, як
і для парної регресії, потрібно збільшити
на
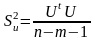 щоби врахувати відхилення прогнозу від
«лінії» регресії. Отже:
щоби врахувати відхилення прогнозу від
«лінії» регресії. Отже:
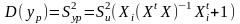 ,
а довірчий інтервал прогнозованого
значення показника:
,
а довірчий інтервал прогнозованого
значення показника:
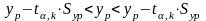 ,
де
,
де