

Малые информационные системы
По техническим характеристикам информационные системы делятся на малые, средние и крупные. Малые информационные системы имеют непродолжительный жизненный цикл, невысокую цену, для их функционирования достаточно одного персонального компьютера, у них практически отсутствуют средства обеспечения безопасности, нет средств аналитической обработки данных.
Архитектура кис состоит из нескольких уровней.
Информационно-логический уровень. Представляет собой совокупность потоков данных и центров (узлов) возникновения, потребления и модификации информации. Может быть представлен в виде модели, на основании которой разрабатываются структуры баз данных, системные соглашения и организационные правила для обеспечения взаимодействия компонентов прикладного программного обеспечения. Прикладной уровень. Представляет собой совокупность прикладных программ и программных комплексов, которые реализуют функционирование информационно-логической модели. Это могут быть:
системы документооборота;
системы контроля над исполнением заданий;
системы сетевого планирования;
автоматизированные системы управления технологическими процессами (АСУТП);
системы автоматизированного проектирования (САПР);
бухгалтерские системы;
офисные пакеты;
системы управления финансами, кадрами, логистикой, и т.д.
Системный уровень. Операционные системы и сетевые средства. Аппаратный уровень. Средства вычислительной техники. Транспортный уровень. Активное и пассивное сетевое оборудование, сетевые протоколы и технологии.
Локальная и распределенная ис.
По степени распределённости отличают:
настольные (desktop), или локальные ИС, в которых все компоненты (БД, СУБД, клиентские приложения) находятся на одном компьютере;Локальная база данных - база данных, размещенная на одном или нескольких носителях на одном компьютере.
Преимущества локальных БД:
1. Увеличение эффективности поиска инф-и за счет комплектования лок БД тематическими информационными массивами, очищенными от ненужной информации.
2. Высокая скорость и точность обмена инф-ей м/упрограммой поиска и базой данных.
3. Информация в ЛБД надежно закодирована и поэтому её хранение максимально безопасно.
4. Возможность пользователя дополнять БД своими личными собраниями документов.
распределённые (distributed) ИС, в которых компоненты распределены по нескольким компьютерам.
Распределённые ИС, в свою очередь, разделяют на:
файл-серверные ИС (ИС с архитектурой «файл-сервер»);
клиент-серверные ИС (ИС с архитектурой «клиент-сервер»).
Распределенная система
Распределенная система — это набор независимых вычислительных машин, представляющийся их пользователям единой объединенной системой.
В этом определении оговариваются два момента. Первый относится к аппаратуре: все машины автономны.
Второй касается программного обеспечения: пользователи думают, что имеют дело с единой системой. Важны оба момента. Позже в этой главе мы к ним вернемся, но сначала рассмотрим некоторые базовые вопросы, касающиеся как аппаратного, так и программного обеспечения.
Характеристики распределенных систем:
1. От пользователей скрыты различия между компьютерами и способы связи между ними. То же самое относится и к внешней организации распределенных систем.
2. Пользователи и приложения единообразно работают в распределенных системах, независимо от того, где и когда происходит их взаимодействие.
Распределенные системы должны также относительно легко поддаваться расширению, или масштабированию. Эта характеристика является прямым следствием наличия независимых компьютеров, но в то же время не указывает, каким образом эти компьютеры на самом деле объединяются в единую систему.
Распределенные системы обычно существуют постоянно, однако некоторые их части могут временно выходить из строя. Пользователи и приложения не должны уведомляться о том, что части системы заменены или починены или, что добавлены новые для поддержки дополнительных пользователей.
Для того чтобы поддержать представление системы в едином виде, организация распределенных систем часто включает в себя дополнительный уровень программного обеспечения, находящийся между верхним уровнем, на котором находятся пользователи и приложения, и нижним уровнем, состоящим из операционных систем.
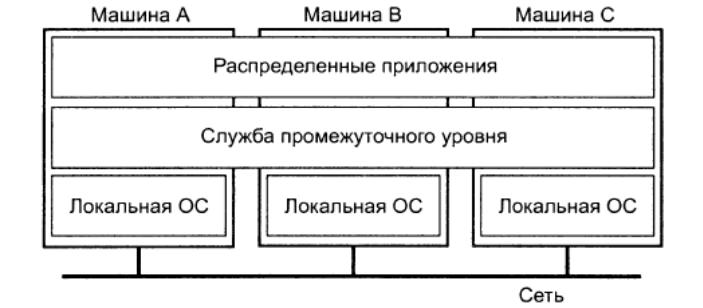
Рис. 1.1. Распределенная система организована в виде службы промежуточного уровня.
Соответственно, такая распределенная система обычно называется системой промежуточного уровня (middleware). Отметим, что промежуточный уровень распределен среди множества компьютеров.
Особенности распределенных ИС
• Ссылки
• Задержки выполнения запросов
• Активация/деактивация
• Постоянное хранение
• Параллельное исполнение
• Отказы
• Безопасность
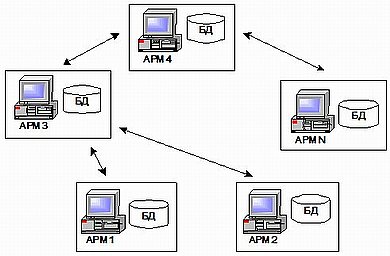
Рисунок 3.3 - Распределенная архитектура системы
Еще два-три года назад реализация такой архитектуры системы для среднего и малого бизнеса была бы не возможна из-за отсутствия соответствующих недорогих аппаратных средств. Сегодня хороший ноутбук обладает мощностью, которой несколько лет назад обладал сервер крупной корпорации, и позволял рассчитывать множество важных и судьбоносных отчетов для всех сотрудников этой корпорации.
Более 95 % данных, используемых в управлении предприятием, могут быть размещены на одном персональном компьютере, обеспечив возможность его независимой работы. Поток исправлений и дополнений, создаваемый на этом компьютере, ничтожен по сравнению с объемом данных, используемых при этом. Поэтому если хранить непрерывно используемые данные на самих компьютерах, и организовать обмен между ними исправлениями и дополнениями к хранящимся данным, то суммарный передаваемый трафик резко снизиться. Это позволяет понизить требования к каналам связи между компьютерами и чаще использовать асинхронную связь, и благодаря этому создавать надежно функционирующие распределенные информационные системы, использующие для связи отдельных элементов неустойчивую связь типа Интернета, мобильную связь, коммерческие спутниковые каналы. А минимизация трафика между элементами сделает вполне доступной стоимость эксплуатации такой связи. Конечно, реализация такой системы не элементарна, и требует решения ряда проблем, одна из которых своевременная синхронизация данных.
Каждый АРМ независим, содержит только ту информацию, с которой должен работать, а актуальность данных во всей системе обеспечивается благодаря непрерывному обмену сообщениями с другими АРМами. Обмен сообщениями между АРМами может быть реализован различными способами, от отправки данных по электронной почте до передачи данных по сетям.
Еще одним из преимуществ такой схемы эксплуатации и архитектуры системы, является обеспечение возможности персональной ответственности за сохранность данных. Так как данные, доступные на конкретном рабочем месте, находятся только на этом компьютере, при использовании средств шифрования и личных аппаратных ключей исключается доступ к данным посторонних, в том числе и IT администраторов.
Такая архитектура системы также позволяет организовать распределенные вычисления между клиентскими машинами. Например, расчет какой-либо задачи, требующей больших вычислений, можно распределить между соседними АРМами благодаря тому, что они, как правило, обладают одной информацией в своих БД и, таким образом, добиться максимальной производительности системы.
Таким образом, предложенная модель построения распределенных систем вполне способна решить и реализовать функции современного программного обеспечения для предприятий среднего и малого бизнеса. Построенные на основе данной архитектуры системы будут обладать надежностью, безопасностью информации и высокой скоростью вычислений, что от них в первую очередь и требуется.
4 вопрос(Сетевые архитектуры построения информационных систем. Архитектура информационных систем «файл-сервер» и «клиент-сервер, характеристика, преимущества и недостатки. Однозвенная, двухзвенная и трехзвенная архитектура построения ИС).
Файл - серверные системы. Системы данного типа функционируют в рамках локальных вычислительных сетей (ЛВС), управляемых ОС соответствующего типа. При этом файловый сервер содержит файлы, необходимые для работы приложений и самой СУБД. Однако пользовательские приложения и сама СУБД размещены и функционируют на отдельных рабочих станциях, и обращаются к файловому серверу только по мере необходимости получения доступа к нужным им файлами - как показано на рис. 5.3. Таким образом, файловый сервер функционирует просто как совместно используемый жесткий диск.
Рис. 5.3 Архитектура с использованием файлового сервера
Очевидно, что архитектура с использованием файлового сервера обладает следующими основными недостатками:
-Большой объем сетевого трафика.
На каждой рабочей станции должна находиться полная копия СУБД.
Управление параллельностью, восстановлением и целостностью усложняется, поскольку доступ к одним и тем же файлам могут осуществлять сразу несколько экземпляров СУБД.
Клиент-серверные системы. При данном подходе предполагается существование клиентского процесса, требующего определенных ресурсов, а также серверного процесса, который эти ресурсы предоставляет. При этом совсем необязательно, чтобы они находились на одном и том же компьютере. На практике системы данного типа реализуются в рамках информационно-вычислительных сетей (не обязательно ЛВС) под управлением клиент-серверных ОС (см. рис. 5.4).
В контексте базы данных клиентская часть управляет пользовательским интерфейсом и логикой приложения, действуя как интеллектуальная рабочая станция, на которой выполняются приложения баз данных. Клиент принимает от пользователя запрос, проверяет синтаксис и генерирует запрос к базе данных на SQL или другом языке БД, который соответствует логике приложения. Затем он передает сообщение серверу, ожидает поступления ответа и форматирует полученные данные для представления их пользователю. Сервер принимает и обрабатывает запросы к базе данных, а затем передает полученные результаты обратно клиенту. Такая обработка включает проверку полномочий клиента, обеспечение требований целостности, поддержку системного каталога, а также выполнение запроса и обновление данных. По-мимо этого, поддерживается управление параллельностью и восстановлением. Выполняемые клиентом и сервером операции приведены ниже.
Рис. 5.4 Общая схема построения систем с архитектурой "клиент/сервер"
Клиент:
- Управляет пользовательским интерфейсом; - Принимает и проверяет синтаксис введенного пользователем запроса; - Выполняет приложение; - Генерирует запрос к базе данных и передает его серверу; - Отображает полученные данные пользователю.
Сервер:
- Принимает и обрабатывает запросы к базе данных со стороны клиентов; - Проверяет полномочия пользователей; - Гарантирует соблюдение ограничений целостности; - Выполняет запросы/обновления и возвращает результаты клиенту; - Поддерживает системный каталог; - Обеспечивает параллельный доступ к базе данных; - Обеспечивает управление восстановлением.
Этот тип архитектуры обладает приведенными ниже преимуществами.
Обеспечивается более широкий доступ к существующим базам данных.
Повышается общая производительность системы. Поскольку клиенты и сервер находятся на разных компьютерах, их процессоры способны выполнять приложения параллельно.
Стоимость аппаратного обеспечения снижается. Достаточно мощный компьютер с большим устройством хранения нужен только серверу - для хранения и управления базой данных.
Сокращаются коммуникационные расходы. Приложения выполняют часть операций на клиентских компьютерах и посылают через сеть только запросы к базе данных, что позволяет существенно сократить объем пересылаемых по сети данных.
Повышается уровень непротиворечивости данных. Сервер может самостоятельно управлять проверкой целостности данных, поскольку все ограничения определяются и проверяются только в одном месте.
Эта архитектура хорошо согласуется с архитектурой открытых систем.
Данная архитектура может быть использована для организации средств работы с распределенными базами данных, т.е. с набором нескольких баз данных, логически связанных и распределенных в компьютерной сети.
Под общим концептуальным названием модели «клиент/сервер» скрывается несколько вариантов архитектурного построения информационных систем, а именно архитектуры однозвенные, двухзвенные, трехзвенные и т. д. (обычно при числе звеньев более трех архитектуру называют многозвенной).
Однозвенная архитектура вырождается в классическую архитектуру с централизованной обработкой информации. В двухзвенной архитектуре приложение разделено на две части: клиентскую и серверную. Обычно сторона клиента содержит логику представления, а логика доступа к данным (как правило СУБД) и сама база данных находятся на стороне сервера. Алгоритмы бизнес-логики могут быть размещены либо полностью на стороне сервера, либо частично или полностью на машине клиента вместе с логикой представления. В случае размещения на стороне клиента лишь части логики представления, минимально достаточной для функционирования клиента (что характерно для современных архитектур так называемых «терминальных», или «бездисковых», рабочих станций), конфигурация обычно носит наименование «сверхтонкого» клиента.
Главными недостатками двухзвенной архитектуры являются необходимость либо наличия высокопроизводительных машин-клиентов (в конфигурации «толстый клиент»), либо относительно высокие требования к производительности сервера (в конфигурации «тонкий клиент»). Размещение в последнем случае на сервере как бизнес-логики, так и логики доступа к данным приводит не только к чрезмерной нагрузке сервера, но и к снижению гибкости его работы и универсальности построения. Тем не менее двухзвенные архитектуры получили с начала 1990-х годов весьма широкое практическое распространение в распределенных системах с небольшим числом клиентов (до нескольких десятков).
Стремление повысить гибкость и масштабируемость многопользовательской распределенной системы привело к архитектурным решениям с тремя и более звеньями. В трехзвенной архитектуре появилось дополнительное звено (так называемый «сервер приложений»), целиком предназначенное для реализации бизнес-логики. Трехзвенная архитектура позволила более явно отделить прикладную логику от пользовательского интерфейса и уровня баз данных. Так как в трехзвенной архитектуре под бизнес-логику обычно выделяется отдельная машина-сервер, то это повышает гибкость распределенной системы (поскольку все три слоя отделены друг от друга, то становится возможным относительно легкое изменение либо перемещение любого из них без существенного влияния на остальные слои).
5 вопрос(Методы проектирования реляционной базы данных. Концептуальное проектирование ИС и инфологическое проектирование БД. Разработка инфологической модель данных заданной предметной области. ER-моделирование.Преобразование инфологической модели в реляционную модель данных).
Методы проектирования БД
Целью проектирования БД является адекватное отображение в базе данных сути предметной области, рассматриваемой с точки зрения решения задачи автоматизации. В теории баз данных существует ряд методов разработки моделей БД, отображающих разные уровни её архитектуры. Распространены два основных подхода к проектированию баз данных: "нисходящий" и "восходящий". Известен также подход "смешанной стратегии" — сначала «восходящий» и «нисходящий» методы используются для разных частей модели, после чего все подготовленные фрагменты собираются в единое целое.
Рассмотрим на рисунке отличие этих методов
Метод восходящего проектирования БД
При
«восходящем» подходе осуществляют
структурное проектирование снизу—вверх.
Этот процесс называют процессом синтеза,
попыткой получения целого, адекватно
отображающего описание предметной
области, на основе описания составляющих
его частей.
Этапы проектирования БД
методом «восходящего» проектирования
представлены на рисунке 2.
 ДЛМ
– даталогическая модель; НФ – нормальная
форма; ИЛМ – информационно—логическая
модель предметной области; МБД – модель
БД.
ДЛМ
– даталогическая модель; НФ – нормальная
форма; ИЛМ – информационно—логическая
модель предметной области; МБД – модель
БД.
Рисунок 2 — Этапы проектирования БД методом «восходящего» проектирования
Работа для реляционной БД начинается с определения свойств объектов (атрибутов сущностей) предметной области, которые на основе анализа существующих между ними связей группируются в реляционные отношения (таблицы), отображающие эти объекты (в том случае, если мы проектируем структуру реляционной БД). Как правило, получают 2 — 3 реляционных отношения, связанных между собой. Избыточность данных в ненормализованной схеме – повторение данных в БД. Для того чтобы полученная структура БД (ДЛМ) не обладала различными аномалиями при добавлении, обновлении или удалении данных вследствие их избыточности, необходимо осуществить проверку каждой полученной схемы отношения, как минимум, на соответствие 3НФ. Если схемы отношений не соответствуют этому условию, а они, как правило, не соответствуют, необходимо проводить процесс нормализации. Значительный объем мероприятий по нормализации схем реляционных отношений даже дал второе название методу «восходящего» проектирования. Этот метод часто называют методом «нормализации». Основы теории нормализации создал Э. Кодд.
Нормализация – это процесс проектирования в терминах реляционной модели данных методом последовательных приближений к удовлетворительному набору схем. Совокупность схем отношений называется схемой реляционной БД. Нормализация исключает избыточность и аномалии в БД.
Рассмотрим
на рисунке схему процесса нормализации

Рисунок – Схема процесса нормализации
«Восходящее» проектирование – это достаточно сложная и устаревшая методика, которая подходит для проектирования только небольших баз данных.
Нисходящее проектирование БД
При
«нисходящем» проектировании осуществляется
структурное проектирование сверху—вниз
(«нисходящее» проектирование).
Такое проектирование называют анализом
– происходит изучение целого (описания
предметной области), затем разделение
целого на составные части и затем следует
последовательное изучение этих
частей.
Этапы проектирования БД
методом «нисходящего» проектирования
представлены на рисунке.

Рисунок — Этапы проектирования БД методом «нисходящего» проектирования
Для отображения метода использованы следующие обозначения: в кругах описаны названия этапов проектирования, в прямоугольниках – результаты.
Проектирование начинается с анализа предметной области и формирования описания внешнего уровня БД, объединяющего представления всех пользователей разрабатываемой БД, выявления классов объектов (сущностей) предметной области, связей между ними.
На основе описания внешнего уровня строится концептуальная информационно—логическая модель предметной области (ИЛМ), затем на её основе получают даталогическую модель (ДЛМ) базы данных. ДЛМ является основой для следующего этапа проектирования БД – этапа формирования физической модели базы данных.
Такой подход к проектированию БД называют также концептуальным или концептуальным проектированием.
В концептуальном подходе к проектированию БД выделяют следующие три сферы: — реальный мир или объектную систему; — информационную сферу; — даталогическую сферу.
1. Основными составляющими объектной системы являются: объект (экземпляр сущности), свойство (атрибут), отношение (связь) (предметная область определена, если известны существующие в ней объекты, их свойства и отношения между ними) Объект в концептуальном подходе – это то, о чем в информационной системе должна накапливаться информация.
Объекты объединены в классы объектов (экземпляры сущностей в сущность, или ещё говорят – тип сущности). Класс объектов может состоять из одного или более объектов. Например, класс объектов ФИЗИЧЕСКОЕ ЛИЦО, отдельные объекты – Иванов, Петров, Сидоров.
Каждый класс объектов должен обладать уникальным идентификатором, который однозначно идентифицирует каждый отдельный объект (экземпляр сущности) в классе объектов. Каждый класс объектов должен обладать некоторыми свойствами (атрибутами), количество которых одинаково для каждого объекта в классе объектов, значение же каждого свойства может быть различным в разных объектах. Каждый класс объектов может обладать любым количеством связей с другими классами объектов.
2. Информационная (инфологическая) сфера представляется понятиями, с помощью которых можно формально описать и проанализировать информацию об объектной системе.
3. В даталогической сфере рассматриваются вопросы представления предметной области (описанной в информационной сфере) с помощью структур данных, определяемых выбором СУБД. В настоящее время наиболее широко для формирования даталогической сферы используются реляционные СУБД.
В основе концептуального подхода лежит идея установления последовательного соответствия между объектной системой, информационной и далее даталогической сферами. Происходит последовательное преобразование понимания объектов предметной области и связей между ними в формализованное описание логики информации предметной области и дальнейшее преобразование логики информации предметной области в описание структуры базы данных в терминах выбранных структур данных – построение логики данных. Такое последовательное преобразование позволяет понятным и простым образом осуществлять правильное отображение смысла реального мира в базе данных.