

1 вопрос (Базы данных как основа построения информационных систем. Определение и основные функции базы данных и системы управления базами данных. Классификация моделей данных. Основные функции систем управленя базами данных. Виды и эволюция СУБД).
Термин база данных начал применяться с 1963 г. и записывался на английском языке как database. По мере развития вычислительной техники, эти два слова были объединены в одно (database). Основной
смысл, вкладываемый в термин "база данных" – это база информационной системы. Инструмент в системе обработки данных – это ЭВМ. Информационная база или база данных представляет собой совокупность данных, предназначенных для совместного применения. Одним из разработчиков теории баз данных, Инглисом (R.Engles), в 1972 г. дано следующее рабочее определение: база данных представляет собой совокупность хранимых операционных данных, используемых прикладными системами некоторого предприятия.
На основе анализа существующих определений и истории развития данной науки в дальнейшем будем пользоваться следующими определениями:
База данных (БД) − структурированная совокупность данных. Наименьшая единица описания данных называется элементом описания. Совокупность элементов описания, объединенных отношением принадлежности к одному описываемому объекту, называется
записью. Например, код типа микросхемы, логическая функция, мощность потребления, коэффициент разветвления в совокупности составляют запись и описывают свойства конкретного объекта − микросхемы.
Система управления базами данных (СУБД) состоит из языковых и программных средств, предназначенных для создания, ведения и эксплуатации баз данных.
Банк данных (БнД) − совокупность баз данных и системы управления базами данных.
Модель данных − формализованное описание, отражающее состав и типы данных, а также взаимосвязь между ними.
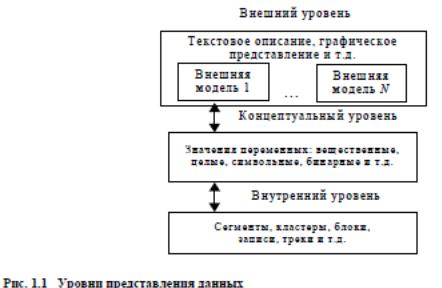
На каждом из рассмотренных на рис. 1.1 уровней присутствует своя модель данных. Это так называемый логический уровень моделей данных. По способам отражений связей между данными на логическом уровне различают модели: иерархическую, сетевую и реляционную. Модель называется сетевой, если данные и их связи имеют структуру графа. Если структура отражаемых связей представляется в виде дерева, то модель называют иерархической. Представление данных в форме таблиц соответствует реляционной модели данных. Задание модели данных в БД осуществляется на специальном языке описания данных.
Функции СУБД
− Определение данных. СУБД должна допускать определение данных в исходной форме и преобразовывать эти определения в форму соответствующих объектов.
− Обработка данных. СУБД должна уметь обрабатывать запросы пользователя по выбору, изменение или удаление существующих данных в базе данных или добавление новых данных. Программное обеспечение должно быть построено таким образом, чтобы реализовать планируемые и непланируемые запросы. К планируемым относятся запросы, необходимость которых предусмотрена заранее, непланируемым (специальные) – наоборот. Планируемые запросы обычно осуществляются из написанных заранее приложений, а непланируемые запросы по определению производятся интерактивно.
− Безопасность и целостность данных. Достигается контролем пользовательских запросов и пресечением попыток нарушения правил безопасности и целостности данных, определяемых администратором
БД.
− Восстановление и дублирование данных. Выполняется СУБД или другим программным компонентом, называемым администратором транзакций.
− Словарь данных. СУБД должна обеспечивать функцию словаря данных. Сам словарь данных является системной БД, содержащей данные о данных, например, исходные и объектные схемы внешнего и концептуального уровня, перекрестные ссылки программ или частей БД, отчеты для различных пользователей и т.д.
− Производительность. Все перечисленные функции должны выполняться с максимально возможной эффективностью.
Основные функции СУБД, рассмотренные выше, можно дополнить еще несколькими входящими в уже известные.
Для функции производительности характерно применение функции непосредственного управления данными во внешней памяти и управление буферами оперативной памяти. Первая функция включает обеспечение необходимых структур внешней памяти как для хранения непосредственных данных, так и служебных целей, например, для хранения индексов. Еще одним реальным способом увеличения скорости является буферизация данных в оперативной памяти, независимо от буферов ОС. Развитие СУБД
поддерживают собственный набор буферов ОЗУ с собственной дисциплиной их замены.
С функцией обработки данных связано управление транзакциями. Транзакция – это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется и СУБД фиксирует (commit) изменения БД, произведенные ею во внешней памяти, либо ни одно изэтих изменений никак не отражается на состоянии БД. При помощи транзакций поддерживается логическая целостность БД за счет объединения элементарных операций над разными файлами в одну транзакцию.
Функции восстановления и дублирования данных в СУБД принято называть журнализацией. В результате аварийного выключения питания компьютера, сбоя в программе, выхода из строя носителяинформации происходит потеря данных в БД. В первых двух случаях (мягкий сбой) восстановить данные можно ликвидацией последствий одной транзакции, в третьем – (жесткий сбой) только копированием из архива. Соблюдение надежности системы достигается избыточностью хранимых данных иливедением журнала изменений БД. Журнал – это особая часть БД, недоступная пользователям СУБД иподдерживаемая особенно тщательно, в которую поступают записи обо всех изменениях основной части БД.
Виды и эволюция СУБД
По типу управляемой базы данных СУБД разделяются на:
Иерархические СУБД - поддерживают древовидную организацию информации. Связи между записями выражаются в виде отношений предок/потомок, а у каждой записи есть ровно одна родительская запись. Это помогает поддерживать ссылочную целостность. Когда запись удаляется из дерева, все ее потомки также должны быть удалены. Иерархические базы данных имеют централизованную структуру, т.е. безопасность данных легко контролировать. К сожалению, определенные знания о физическом порядке хранения записей все же необходимы, так как отношения предок/потомок реализуются в виде физических указателей из одной записи на другую. Это означает, что поиск записи осуществляется методом прямого обхода дерева. Записи, расположенные в одной половине дерева, ищутся быстрее, чем в другой. Отсюда следует необходимость правильно упорядочивать записи, чтобы время их поиска было минимальным. Это трудно, так как не все отношения, существующие в реальном мире, можно выразить в иерархической базе данных. Отношения "один ко многим" являются естественными, но практически невозможно описать отношения "многие ко многим" или ситуации, когда запись имеет несколько предков. До тех пор пока в приложениях будут кодироваться сведения о физической структуре данных, любые изменения этой структуры будут грозить перекомпиляцией.
Сетевые СУБД - Сетевая модель расширяет иерархическую модель СУБД, позволяя группировать связи между записями в множества. С логической точки зрения связь — это не сама запись. Связи лишь выражают отношения между записями. Как и в иерархической модели, связи ведут от родительской записи к дочерней, но на этот раз поддерживается множественное наследование. Следуя спецификации CODASYL, сетевая модель поддерживает DDL (DataDefinitionLanguage — язык определения данных) и DML (DataManipulationLanguage — язык обработки данных). Это специальные языки, предназначенные для определения структуры базы данных и составления запросов. Несмотря на их наличие программист по-прежнему должен знать структуру базы данных. В сетевой модели допускаются отношения "многие ко многим", а записи не зависят друг от друга. При удалении записи удаляются и все ее связи, но не сами связанные записи. В сетевой модели требуется, чтобы связи устанавливались между существующими записями во избежание дублирования и искажения целостности. Данные можно изолировать в соответствующих таблицах и связать с записями в других таблицах. Программисту не нужно, при проектировании СУБД, заботиться о том, как организуется физическое хранение данных на диске. Это ослабляет зависимость приложений и данных. Но в с етевой модели требуется, чтобы программист помнил структуру данных при формировании запросов. Оптимальную структуру базы данных сложно сформировать, а готовую структуру трудно менять. Если вид таблицы претерпевает изменения, все отношения с другими таблицами должны быть установлены заново, чтобы не нарушилась целостность данных. Сложность подобной задачи приводит к тому, что программисты зачастую отменяют некоторые ограничения целостности ради упрощения приложений.
Реляционные СУБД - В сравнении с рассмотренными выше моделями реляционная модель требует от сервера СУБД гораздо более высокого уровня сложности. В ней делается попытка избавить программиста от выполнения рутинных операций по управлению данными, столь характерных для иерархической и сетевой моделей. В реляционной модели база данных представляет собой централизованное хранилище таблиц, обеспечивающее безопасный одновременный доступ к информации со стороны многих пользователей. В строках таблиц часть полей содержит данные, относящиеся непосредственно к записи, а часть — ссылки на записи других таблиц. Таким образом, связи между записями являются неотъемлемым свойством реляционной модели. Каждая запись таблицы имеет одинаковую структуру. Например, в таблице, содержащей описания автомобилей, у всех записей будет один и тот же набор полей: производитель, модель, год выпуска, пробег и т.д. Такие таблицы легко изображать в графическом виде. В реляционной модели СУБД достигается информационная и структурная независимость. Записи не связаны между собой настолько, чтобы изменение одной из них затронуло остальные, а измененная структура СУБД, базы данных не обязательно приводит к перекомпиляции работающих с ней приложений. В реляционных СУБД применяется язык SQL, позволяющий формулировать произвольные, нерегламентированные запросы. Это язык четвертого поколения, поэтому любой пользователь может быстро научиться составлять запросы. К тому же, существует множество приложений, позволяющих строить логические схемы запросов в графическом виде. Все это происходит за счет ужесточения требований к производительности компьютеров. К счастью, современные вычислительные мощности более чем адекватны. Реляционные базы данных страдают от различий в реализации языка SQL, хотя это и не проблема реляционной модели. Каждая реляционная СУБД реализует какое-то подмножество стандарта SQL плюс набор уникальных команд, что усложняет задачу программистам, пытающимся перейти от одной СУБД к другой. Приходится делать нелегкий выбор между максимальной переносимостью и максимальной производительностью. В первом случае нужно придерживаться минимального общего набора команд, поддерживаемых в каждой СУБД. Во втором случае программист просто сосредоточивается на работе в данной конкретной СУБД, используя преимущества ее уникальных команд и функций СУБД.
Объектно-ориентированные СУБД - позволяет программистам, которые работают с языками третьего поколения, интерпретировать все свои информационные сущности как объекты, хранящиеся в оперативной памяти. Дополнительный интерфейсный уровень абстракции обеспечивает перехват запросов, обращающихся к тем частям базы данных, которые находятся в постоянном хранилище на диске. Изменения, вносимые в объекты, оптимальным образом переносятся из памяти на диск. Преимуществом ООСУБД является упрощенный код. Приложения получают возможность интерпретировать данные в контексте того языка программирования, на котором они написаны. Реляционная база данных возвращает значения всех полей в текстовом виде, а затем они приводятся к локальным типам данных. В ООБД этот этап ликвидирован. Методы манипулирования данными всегда остаются одинаковыми независимо от того, находятся данные на диске или в памяти. Данные в ООСУБД способны принять вид любой структуры, которую можно выразить на используемом языке программирования. Отношения между сущностями также могут быть произвольно сложными. ООБД управляет кэш-буфером объектов, перемещая объекты между буфером и дисковым хранилищем по мере необходимости.
С помощью ООСУБД решаются две проблемы. Во-первых, сложные информационные структуры выражаются в них лучше, чем в реляционных базах данных, а во вторых, устраняется необходимость транслировать данные из того формата, который поддерживается в СУБД. Большим недостатком объектно-ориентированных баз данных является их тесная связь с применяемым языком программирования. К данным, хранящимся в реляционной СУБД, могут обращаться любые приложения, тогда как, к примеру, Java-объект, помещенный в ООСУБД, будет представлять интерес лишь для приложений, написанных на Java.
Объектно-реляционные - Объектно-реляционные СУБД объединяют в себе черты реляционной и объектной моделей. Их возникновение объясняется тем, что реляционные базы данных хорошо работают со встроенными типами данных и гораздо хуже — с пользовательскими, нестандартными. Когда появляется новый важный тип данных, приходится либо включать его поддержку в СУБД, либо заставлять программиста самостоятельно управлять данными в приложении. Не всякую информацию имеет смысл интерпретировать в виде цепочек символов или цифр. Перестройка архитектуры СУБД с целью включения в нее поддержки нового типа данных — не лучший выход из положения. Вместо этого объектно-реляционная СУБД позволяет загружать код, предназначенный для обработки "нетипичных" данных. Таким образом, база данных сохраняет свою табличную структуру, но способ обработки некоторых полей таблиц определяется извне, т.е. программистом.
По архитектуре СУБД и организации хранения данных:
локальные СУБД (все части локальной СУБД размещаются на одном компьютере); распределенные СУБД (части СУБД могут размещаться на двух и более компьютерах).
По способу доступа СУБД к базе данных:
Файл-серверные СУБД. В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере СУБД. Ядро СУБД располагается на каждом клиентском компьютере. Доступ к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на ЦП сервера, а недостатком — высокая загрузка локальной сети.
Клиент-серверные СУБД. Такие СУБД состоят из клиентской части (которая входит в состав прикладной программы) и сервера СУБД (см. Клиент-сервер). Клиент-серверные СУБД, в отличие от файл-серверных, обеспечивают разграничение доступа между пользователями и мало загружают сеть и клиентские машины. Сервер является внешней по отношению к клиенту программой, и по надобности его можно заменить другим. Недостаток клиент-серверных СУБД в самом факте существования сервера СУБД (что плохо для локальных программ — в них удобнее встраиваемые СУБД) и больших вычислительных ресурсах, потребляемых сервером.
Встраиваемые СУБД. Встраиваемая СУБД — библиотека, которая позволяет унифицированным образом хранить большие объёмы данных на локальной машине. Доступ к данным может происходить через SQL либо через особые функции СУБД. Встраиваемые СУБД быстрее обычных клиент-серверных и не требуют установки сервера, поэтому востребованы в локальном ПО, которое имеет дело с большими объёмами данных (например, геоинформационные системы).
История развития субд
В середине 60-х годов корпорация IBM совместно с фирмой NAA (NorthAmericanAviation, в настоящее время - RockwellInternational) разработали первую СУБД - иерархическую систему IMS (InformationManagementSystem). Несмотря на то, что IMS является самой первой из всех коммерческих СУБД, она до сих пор остается основной иерархической СУБД, используемой на большинстве крупных мейнфреймов.
Другим заметным достижением середины 60-х годов было появление системы IDS (IntegratedDataStore) фирмы GeneralElectric. Развитие этой системы привело к созданию нового типа систем управления базами данных - сетевых СУБД, что оказало существенное влияние на информационные системы того поколения.
В 1970 году Э. Ф. Кодд , работавший в корпорации IBM, опубликовал статью о реляционной модели данных, позволявшей устранить недостатки прежних моделей. Вслед за этим появилось множество экспериментальных реляционных СУБД, а первые коммерческие продукты появились в конце 70-х - начале 80-х годов. Однако реляционная модель также обладает некоторыми недостатками - в частности, ограниченными возможностями моделирования. Для решения этой проблемы был выполнен большой объем исследовательской работы. В 1976 году Чен предложил модель "сущность-связь" (Entity-Relationshipmodel - ER-модель), которая в настоящее время стала основой методологии концептуального проектирования баз данных и методологии логического проектирования реляционных баз данных.
В ответ на все возрастающую сложность приложений баз данных появились две новые системы: объектно-ориентированные СУБД, или ОО СУБД (Object-Oriented DBMS - OODBMS), и объектно-реляционные СУБД, или ОР СУБД (Object-Relational DBMS - ORDBMS). Попытки реализации подобных моделей представляют собой СУБД третьего поколения.
Эпоха объектно-реляционных баз данных началась в декабре 1996 года в компании Informix, которая выпустила объектно-реляционную систему управления базами данных (ОРСУБД) InformixUniversalServer. Вслед за ней в 1997 г. на рынке появились ОРСУБД компаний Oracle (Oracle8) и IBM (DB2 UniversalDatabase). В течение примерно трех лет новая технология интенсивно обсуждалась. Многим в то время казалось, что ОРСУБД в корне изменят способы проектирования и разработки приложений баз данных. Однако постепенно шум вокруг ОРСУБД затих. До конца 1990-х гг. Informix, Oracle и IBM совершенствовали свои ОРСУБД. В 1999 г. появился стандарт SQL:1999, в котором были зафиксированы объектные расширения языка SQL. И, наконец, после выхода в 2003 г. стандарта SQL:2003, уточнившего и дополнившего SQL:1999, в сообществе баз данных окончательно перестали обсуждать объектно-реляционную технологию баз данных.
2 вопрос(Обобщенная функциональная структура СУБД. Назначение и функции составных частей СУБД. Типовая организация СУБД. Физическая и логическая независимость. Базы и банки данных. Этапы проектирования базы данных).
Структура СУБД
Организация типичной СУБД и состав ее компонентов соответствуют рассмотренному нами набору
функций.
Логически, например в реляционной СУБД можно выделить наиболее внутреннюю часть – ядро
СУБД, компилятор языка БД, подсистему поддержки времени выполнения и набор утилит (рис. 3.5). В
некоторых системах эти части выполняются явно, в других нет, но логически такое разделение можно
провести во всех СУБД.
Ядро СУБД обладает собственным интерфейсом, не доступным пользователям напрямую и используемым в программах, производимых компилятором SQL (или в подсистеме поддержки выполнения

таких программ), и утилитах БД. Ядро СУБД является основной резидентной частью СУБД.
Компилятор непроцедурного языка SQL решает проблему выполнения оператора, его оптимизации и генерирования программного кода. Реальное выполнение оператора осуществляется подсистемой поддержкивремени выполнения, представляющей собой интерпретатор внутреннего языка. Утилиты программируются с использованием интерфейса ядра СУБД или с проникновением внутрь ядра.
Архитектура базы данных. Физическая и логическая независимость.
В процессе научных исследований, посвященных тому, как именно должна быть
устроена СУБД, предлагались различные способы реализации. Самым жизнеспособным из них оказалась предложенная американским комитетом по стандартизации ANSI (AmericanNationalStandardsInstitute) трехуровневая система оргашзации БД, изображенная на рис. 2.1:

1. Уровень внешних моделей — самый верхний уровень, где каждая модель имеет свое ≪видение≫ данных. Этот уровень определяет точку зрения на БД отдельных приложений. Каждое приложение видит и обрабатывает только те данные, которые необходимы именно этому приложению, Например, система распределения работ использует сведения о квалификации сотрудника, но ее не интересуют сведения об окладе, домашнем адресе и телефоне сотрудника, и наоборот, именно эти сведения используются в подсистеме отдела кадров.
2. Концептуальный уровень — центральное управляющее звено, здесь база данных представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной базой данных. Фактически концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась база данных. Как любая модель, концептуальная модель отражает только существенные, с точки зрения обработай, особенности объектов реального мира.
3. Физический уровень — собственно данные, расположенные в файлах или встраничных структурах, расположенных на внешних носителях информации.Эта архитектура позволяет обеспечить логическую (между уровнями 1 и 2) ифизическую (между уровнями 2 и 3) независимость при работе с данными. Логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с этой же базой данных. Физическая независимость, предполагает возможность переноса хранимойинформации с одних носителей на другие при сохранении работоспособностивсех приложений, работающих с данной базой данных. Это именно то, чего нехватало при использовании файловых систем.
Выделение концептуального уровня позволило разработать аппарат централизованного управления базой данных.
БАНКИ ДАННЫХ. ОБЩИЕ ТРЕБОВАНИЯ К НИМ,
ИХ ТРАДИЦИОННАЯ АРХИТЕКТУРА
Рассмотрим более полное определение банков данных. Банк данных − это система специальным образом организованных данных (баз данных), программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
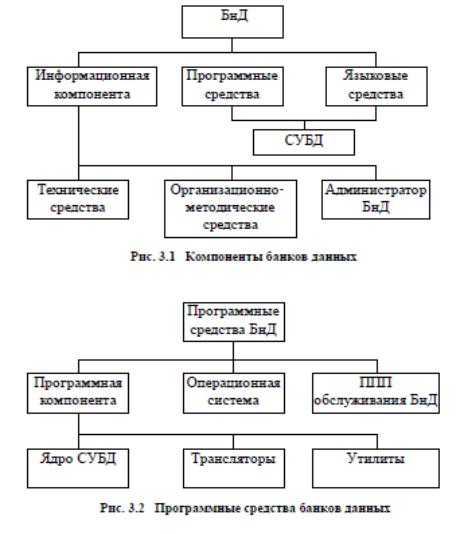
Термин "банк данных" не является общепризнанным. Наиболее близким к нему в англоязычной литературе является термин "система баз данных" (databasesystem). Система баз данных включает базу данных, СУБД, соответствующее оборудование и персонал. Понятие "система баз данных" уже, чем БнД, так как "банк" обозначает то, что хранится в нем и всю инфраструктуру, но по сути они одинаковы. БнД является сложной человеко-машинной системой, включающей в свой состав различные взаимосвязанные и взаимозависимые компоненты (рис. 3.1). Ядром БнД является база данных. Информационный компонент состоит из БД, схем БД, словарей данных. Последние играют в САПР особенно важное значение.Программные средства БнДпредставляют собой сложный комплекс, обеспечивающий взаимодействие всех частей информационной системы при ее функционировании (рис. 3.2). Основу программных средств представляет СУБД. В ней можно выделить ядро СУБД, обеспечивающее организацию ввода, обработки и хранения данных и средства настройки, тестирование и утилиты вспомогательных функций для восстановления БД, сборы статистики о функционировании БД и др. Компиляторы и трансляторы являются важной компонентой языковых средств СУБД. Все СУБД работают под управлением операционной системы (ОС).
Для обработки запросов к БД разрабатывается соответствующее прикладное программное обеспечение. Языковые средства БнД обеспечивают интерфейс пользователей разных категорий с банком данных и базируются на языковых средствах СУБД. Их спектр достаточно широк (рис. 3.3). Категории языковых средств различаются по функциональным возможностям:
− языки ввода данных по запросу (устарели);

− языки запросов – обновлений (сложные запросы по нескольким взаимосвязанным записям);
− генератор отчетов для выбора данных и формирования в виде формы требуемого документа;
− графические языки, аналогичны генератору отчетов, данные отображаются в виде диаграмм, графиков и т.п.;
− языки принятия решений (пролог);
− генераторы приложений для автоматизированной генерации программ;
− параметризированные пакеты прикладных программ (ППП), для генерирования собственных отчетов и запросов;
− языки приложений.
По форме представления различают аналитические, табличные и графические языковые средства. Такая классификация справедлива и для ЯОД и для ЯМД. Современные СУБД включают в свой состав несколько языковых средств разного уровня. В качестве технических средств для БнД чаще всего используются универсальные ЭВМ, стандартный набор периферийных устройств и сетевого оборудования. Для создания и эксплуатации систем баз данных используются специальные технические средства, например серверы, накопители на магнитных лентах (стримеры), накопители на оптических носителях (CD R/W).
Этапы проектирования баз данных
Число этапов проектирования БД напрямую зависит от количества уровней представления данных, или моделей данных. Известно четыре основных модели данных: даталогическая (ДЛМ), физическая (ФМ), внешняя (ВМ) и инфологическая (ИЛМ). Следовательно, можно говорить о четырех этапах проектирования БД (рис. 6.8).

1 Даталогическое проектирование основано на модели логического уровня и представляет собой описание и построение схем связей между элементами данных безотносительно к их содержанию и среде хранения.
2 Физическое проектирование состоит в описании и построении схем хранения данных для определенной среды хранения. На этом этапе осуществляется выбор типа носителя, способ организации данных, методов доступа, определение параметров физического блока, управление работой памяти, считывание данных и т.д.
3 Внешнее моделирование состоит в описании и построении схем или логических структур с точки зрения конкретного пользователя. На этом этапе формализуются допустимые режимы обработки данных в рамках данной схемы или подсхемы. Для реляционных моделей это описание процедуры View конкретного приложения.
4 Инфологическое проектирование состоит в описании и построении схем отражений предметной области, выполненном без ориентации на используемые в дальнейшем программные и технические средства.
3 вопрос(Архитектура однопользовательской и многопользовательской, малой и корпоративной ИС, локальной и распределенной ИС, состав и назначение подсистем).
Однопользовательские ИС - информационные системы
Для работы одного человека. К ним можно отнести автоматизированное рабочее место (АРМ) специалиста (конструктора, технолога, расчетчика на прочность, бухгалтера малого предприятия, расчетчика заработной платы и т.д.) ИС этого уровня позволяют специалистам, работающим с данными повысить продуктивность и производительность работы.
Внедрение таких программ не вызывает особых трудностей и для хороших систем может исчисляться днями. Настольные ИС реализуются на автономном компьютере, как правило, ПК. Такая система может содержать несколько простых приложений, связанных общим информационным фондом, и рассчитана на работу одного пользователя или группы пользователей, разделяющих по времени одно рабочее место. Подобные приложения создаются с помощью так называемых "настольных СУБД" (FoxPro, Paradox, dBase, MS Access ) или с помощью файловой системы и диалоговой оболочки для ввода, редактирования и обработки данных.