

Суть состоит в том, что при устранении избыточности очень важно исследовать значение каждой из связей, существующих между сущностями.
По завершении данного этапа получили упрощенную локальную концептуальную модель данных, из которой удалены все структуры, реализация которых в среде реляционных СУБД затруднительна.
Поэтому на данном этапе правильнее будет называть улучшенную локальную концептуальную модель локальной логической моделью данных.
Этап 2.2. Определение набора отношений исходя из структуры локальной логической модели данных
Цель: определение набора отношений на основе локальной логической модели данных.
На данном этапе предстоит на основе созданных локальных логических моделей данных определить наборы отношений, необходимые для представления сущностей и связей, входящих в представления отдельных пользователей о предметной области приложения.
Для описания структуры создаваемых отношений воспользуемся языком DBDL (Database Definition Language), широко используемым в реляционных СУБД. Описание отношения на языке DBDL начинается с присвоенного ему имени, за которым следует помещенный в скобки список имен его простых полей. Затем указывается первичный ключ отношения и все его альтернативные и/или внешние ключи. После описания внешних ключей может указываться ссылочный первичный ключ, если таковой имеется.
Теперь рассмотрим, как отношения, отражающие сущности и связи между ними, могут быть созданы исходя из имеющихся в логической модели различных допустимых структур данных. Для иллюстрации этого процесса будет использоваться логическая модель, показанная на рис. 5.8.
Связи, которые сущность имеет с другими типами сущностей, представляются с помощью механизма первичных и внешних ключей. Для принятия решения о том, откуда взять и куда поместить значения атрибута(ов) внешнего ключа, предварительно следует установить, какая из участвующих в связи сущностей является родительской, а какая – дочерней. Родительской считается сущность, которая передает копию набора значений своего первичного ключа в отношение, представляющее дочернюю сущность, где эти значения будут играть роль внешнего ключа.
Сильные типы сущностей
Для каждой сильной (регулярной) сущности в локальной модели данных создается, отношение, включающее все простые атрибуты этой сущности. В случае составных атрибутов (например, адреса) в отношение включаются только составляющие их простые атрибуты (такие, как город, улица, почтовый код).
Ниже приведен пример состава отношения Преподаватель, определенного для логической модели, показанной на рис. 5.8.
Преподаватель (Табельный номер, ФИО, Ученая степень, Адрес, Телефон, Код кафедры)
Primary Key Табельный номер
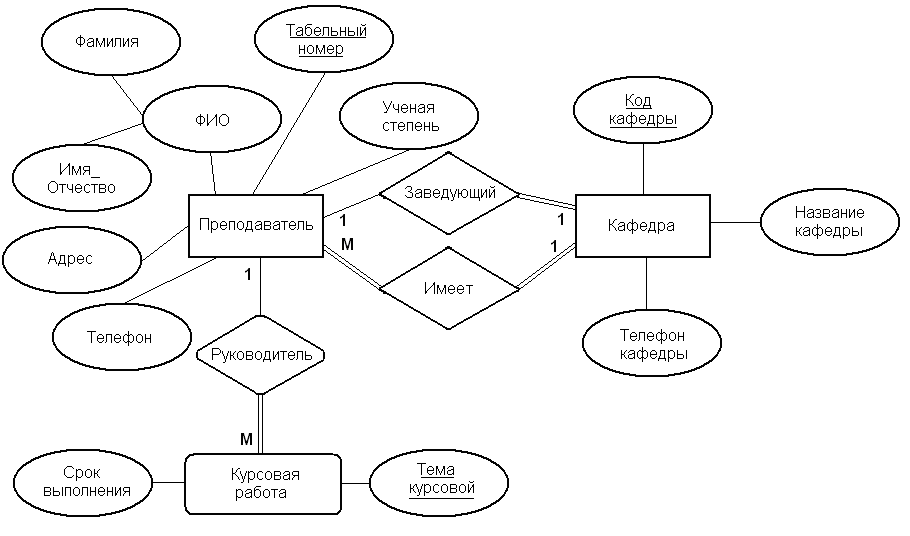
Рис. 5.8. Пример логической модели данных
Слабые типы сущностей
Для каждой слабой сущности, присутствующей в логической модели, создается отношение, включающее все простые атрибуты этой сущности. Дополнительно в отношение включается атрибут внешнего ключа, соответствующего первичному ключу сущности-владельца. Первичный ключ слабой сущности частично или полностью выводится из ключа сущности-владельца.
Например, показанная на рис. 5.8 сущность Преподаватель является владельцем слабой сущности Курсовая работа (имеется в виду, что определенный преподаватель руководит курсовой работой). Описание представляющее эту сущность отношения приведено ниже.
Курсовая работа (Табельный номер, Тема курсовой, Срок выполнения)
Primary Key Табельный номер, Тема курсовой
Foreign Key Табельный номер references Преподаватель(Табельный номер)
Обратите внимание на то, что атрибут внешнего ключа отношения Курсовая работа входит в состав первичного ключа этой сущности. В данной ситуации первичный ключ отношения Курсовая работа невозможно установить до тех пор, пока в нее не будет помещен внешний ключ, выбранный в отношении Преподаватель. Таким образом, к концу данного этапа необходимо определить любые первичные и потенциальные ключи, которые могут потребоваться для построения набора отношений, необходимого для полного представления исходной логической модели данных.
Бинарные связи типа „один к одному" (1:1)
Для каждой присутствующей в логической модели данных бинарной связи типа 1:1, установленной между сущностями Е1 и Е2, необходимо переслать атрибуты первичного ключа сущности Е1 в отношение, представляющее сущность Е2. Эти атрибуты будут использоваться в нем в качестве внешнего ключа. Определение родительской и дочерней сущностей зависит от ограничений участия, наложенных на члены отношения Е1 и Е2.
Сущность, которая частично участвует в связи, определяется как родительская, а та сущность, которая участвует в связи полностью (тотально), определяется как дочерняя.
Копия набора значений первичного ключа родительской сущности помещается в отношение, представляющее дочернюю сущность.
Отметим, что в том случае, когда оба вида сущностей участвуют в связи типа 1:1 либо тотально, либо частично, выбор родительской и дочерней сущностей может выполняться произвольно. Более того, если обе сущности участвуют в связи тотально, можно (на выбор) либо представить эту связь с помощью пары первичного и внешнего ключей (как описывалось выше), либо слить атрибуты обеих сущностей в единое отношение. Слияние в единое отношение предпочтительнее в том случае, если данные сущности не принимают участия в других типах связей.
Ниже приведен пример, иллюстрирующий, как связь типа 1:1 можно представить в отношениях, созданных на базе предложенной выше логической модели данных.
Связь Заведующий, показанная на рис. 5.8, является связью типа 1:1, поскольку каждая кафедра имеет только одного заведующего. Сущность Преподаватель участвует в этой связи частично, тогда как сущность Кафедра – полностью. Та сущность, которая участвует в связи частично (Преподаватель), определяется как родительская, а та сущность, которая участвует в связи полностью (Кафедра), – как дочерняя. Следовательно, копия первичного ключа сущности Преподаватель (родительской), представленного атрибутом Табельный номер, пересылается в отношение Кафедра (дочернее). В результате отношения Преподаватель и Кафедра должны быть определены следующим образом:
Преподаватель (Табельный номер, ФИО, Ученая степень, Адрес,
Телефон, Код кафедры)
Primary Key Табельный номер
Кафедра (Код кафедры, Название кафедры, Телефон кафедры, Табельный
номер заведующего)
Primary Key Код кафедры
Foreign Key Табельный номер заведующего references Преподаватель
(Табельный номер)
Обратите внимание на то, что атрибут Табельный номер, представляющий заведующего кафедры, был переименован в Табельный номер заведующего. Это сделано с целью более точного указания назначения данного внешнего ключа отношения Кафедра.
Бинарные связи типа „один ко многим" (1:М)
Для каждой бинарной связи типа 1:М, установленной в логической модели данных между сущностями Е1 и Е2, необходимо переслать копию атрибутов первичного ключа сущности Е1 в отношение, представляющее сущность Е2, где они будут играть роль внешнего ключа.
Сущность, представляющая "единичную" сторону связи определяется как родительская, а сущность, представляющая "множественную" сторону, – как дочерняя. Как и в предыдущем случае, для представления данной связи необходимо скопировать первичный ключ родительской сущности в отношение, представляющее дочернюю сущность, где этот ключ должен быть описан как внешний.
Ниже приведен пример, иллюстрирующий, как связь типа 1:М можно представить в отношениях, созданных на базе предложенной выше логической модели данных.
Связь типа имеет, показанная на рис. 5.7, имеет тип 1:М, поскольку к каждой кафедре относятся несколько преподавателей. В этом случае отношение Кафедра является “единичной" стороной связи и представляет родительскую сущность, тогда как отношение Преподаватель является "множественной" стороной связи и представляет дочернюю сущность. Связь между этими двумя сущностями устанавливается путем помещения копии первичного ключа сущности Кафедра (родительской), представленного атрибутом Код кафедры, в отношение Преподаватель (дочернее). В результате окончательный вид отношений Преподаватель и Кафедра должен быть следующим:
Преподаватель (Табельный номер, ФИО, Ученая степень, Адрес,
Телефон, Код кафедры)
Primary Key Табельный номер
Foreign Key Код кафедры references Кафедра (Код кафедры)
Кафедра (Код кафедры, Название кафедры, Телефон кафедры, Табельный
номер заведующего)
Primary Key Код кафедры
Foreign Key Табельный номер заведующего references Преподаватель
(Табельный номер)
Связи типа "суперкласс/подкласс"
Для каждой присутствующей в логической модели данных связи типа "суперкласс/подкласс" сущность суперкласса необходимо определить как родительскую, а сущность подкласса – как дочернюю. Существуют различные варианты представления подобных связей в виде одного или нескольких отношений. Выбор наиболее подходящего варианта зависит от ограничений участия и пересечения, наложенных на участников связи типа "суперкласс/подкласс".
Рассмотрим, например, связь типа "суперкласс/подкласс" сущности Property, показанную на рис. 5.1 б. Существуют различные способы отображения этой связи.
(Вариант 1)
Все_Книги (Код книги, Название книги, Издательство, Количество
страниц, Термин сдачи)
Primary Key Код книги
(Вариант 2)
Книги (читательский зал) (Код книги, Название книги, Издательство,
Количество страниц)
Primary Key Код книги
Книги (выдача на руки) (Код книги, Название книги, Издательство,
Количество страниц, Термин сдачи)
(Вариант 3)
Книги (Код книги, Название книги, Издательство, Количество
страниц)
Primary Key Код книги
Книги (читательский зал) (Код книги)
Primary Key Код книги
Foreign Key Код книги references Книги (Код книги)
Книги (выдача на руки) (Код книги, Термин сдачи)
Primary Key Код книги
Foreign Key Код книги references Книги (Код книги)
Диапазон возможных вариантов решений простирается от помещения всех атрибутов суперкласса в единственное отношение (вариант 1) до распределения всех атрибутов между тремя различными отношениями (вариант 3). Наиболее подходящий вариант для каждой связи типа "суперкласс/подкласс" определяется ограничениями, специфическими для данной конкретной связи. Связи, которые суперкласс Книги имеет с его подклассами, являются тотальными и непересекающимися, поскольку каждый член суперкласса Книги обязательно должен быть членом одного и только одного из подклассов (Книги (читательский зал) или Книги (выдача на руки)). Поэтому самым целесообразным решением для связи типа "суперкласс/подкласс" с тотальными и непересекающимися членами является представление каждого из подклассов в виде отдельного отношения, содержащего копию первичного ключа суперкласса. Это второй вариант в приведенном выше примере. Однако на окончательное решение могут оказать влияние и другие факторы – в частности то, включены или нет отдельные подклассы в различные связи.
Документирование созданных отношений и атрибутов внешних ключей
Документирование состава отношений, созданных на базе каждой из логических моделей данных, осуществляется на языке DBDL. Отметим, что синтаксис языка DBDL может быть расширен с целью указания ограничений целостности для внешних ключей (этап 2.6). Кроме того, следует обновить содержимое словаря данных для отображения сведений о любых новых ключевых атрибутах, определенных на данном этапе.
Этап 2.3. Проверка модели с помощью правил нормализации
Цель: проверка локальной логической модели данных с использованием технологии нормализации.
Нормализация используется для улучшения модели данных, для того чтобы она удовлетворяла различным ограничениям, позволяющим исключить нежелательное дублирование данных. Нормализация гарантирует, что полученная в результате ее применения модель данных будет наилучшим образом отображать особенности использования информации на предприятии, не содержать противоречий, иметь минимальную избыточность и максимальную устойчивость.
Нормализация представляет собой процедуру принятия решений о том, какие именно атрибуты должны быть объединены для представления сущностей каждого типа. В одной из фундаментальных концепций теории нормализации утверждается, что атрибуты должны быть сгруппированы в отношения в соответствии с существующими между ними логическими связями. В некоторых случаях имеют место утверждения, что нормализация разрабатываемых баз данных не позволяет достичь максимальной производительности при их обработке. На это можно ответить следующими замечаниями:
Нормализация проекта позволяет организовать размещение данных в соответствии с их функциональными зависимостями. Поэтому данная процедура должна выполняться между этапами концептуального и физического проектирования.
На этапе логического проектирования не ставится задача достичь окончательного вида проекта. Цель этого этапа заключается в предоставлении проектировщику более углубленного понимания природы и назначения данных, используемых на предприятии. Если к приложению предъявляются специфические требования в отношении его производительности, то они должны учитываться на этапе физического проектирования. В этом случае одним из подходов является денормализация определенных таблиц. Однако это не означает, что время на их нормализацию было затрачено впустую, поскольку для правильного выполнения нормализации проектировщик должен глубоко изучить семантику и особенности использования данных. Подробнее о денормализации речь пойдет в разделе "Методология физического проектирования реляционных баз данных" (этап 5.4).
Нормализация проекта позволяет повысить его устойчивость и избавиться от аномалий обновления.
За последние несколько лет мощность компьютеров существенно возросла. Поэтому в некоторых случаях может быть вполне обоснованным решение реализовать проект, позволяющий упростить работу с данными за счет выполнения некоторого объема дополнительной обработки.
Выполнение нормализации требует от разработчика полного понимания назначения каждого атрибута, присутствующего в создаваемой базе данных. Достигнутые за счет этого преимущества могут оказаться весьма существенными.
В результате применения нормализации разработчик получает весьма гибкий проект базы данных, позволяющий легко вносить в нее необходимые расширения.
На предыдущем этапе был создан набор отношений, реализующих локальные логические модели данных. На этом этапе проанализируем корректность объединения атрибутов в каждом из отношений. Другими словами, задача состоит в проверке корректности состава каждого из созданных отношений посредством применения к ним процедуры нормализации. Процесс нормализации включает следующих четыре основных этапа:
приведение к первой нормальной форме (1НФ), позволяющее удалить из отношений повторяющиеся группы атрибутов;
приведение ко второй нормальной форме (2НФ), позволяющее устранить частичную зависимость атрибутов от первичного ключа;
приведение к третьей нормальной форме (ЗНФ), позволяющее устранить транзитивную зависимость атрибутов от первичного ключа;
приведение к нормальной форме Бойса-Кодда (НФБК), позволяющее удалить из функциональных зависимостей оставшиеся аномалии. Целью выполнения этих этапов является получение гарантий того, что каждое из отношений, созданных на основании логической модели данных, отвечает, по крайней мере, требованиям НФБК. Если будут найдены отношения, не отвечающие требованиям НФБК, это может указывать на то, что часть логической модели данных неверна либо преобразование логической модели в набор отношений выполнено некорректно. При необходимости потребуется перестроить модель данных и убедиться, что она верно отображает моделируемую часть информационной структуры предприятия.
Этап 2.4. Проверка модели в отношении транзакций пользователей
Цель: убедиться в том, что локальная логическая модель данных позволяет выполнить все транзакции, предусмотренные данным представлением пользователя.
Целью выполнения данного этапа является проверка локальной логической модели данных на возможность выполнения всех транзакций, предусмотренных данным представлением пользователя. Перечень транзакций определяется в соответствии со спецификациями, описывающими действия, выполняемые данным пользователем. Используя ER-диаграммы, словарь данных и установленные связи между первичными и внешними ключами, указанные в описании отношений, необходимо выполнить все необходимые операции доступа к данным вручную. Если удастся подобным образом найти способ выполнения всех требуемых транзакций, то на этом проверка логической модели данных будет завершена. Однако, если какую-либо из транзакций выполнить вручную не удастся, значит, составленная модель данных является неадекватной и содержит ошибки, которые потребуется устранить. Вероятнее всего, ошибка будет связана с пропуском в модели данных сущности, связи или атрибута.
Рассмотрим два возможных подхода, благодаря которым сможем убедиться, что локальная логическая модель данных позволяет выполнить все необходимые транзакции.
Первый подход предусматривает выполнение проверки того, что данная логическая модель предоставляет всю информацию (сущности, связи и их атрибуты), необходимую для выполнения каждой из транзакций. Практически это реализуется при подготовке описания требований, выдвигаемых каждой из транзакций.
Например, транзакции, необходимые заведующему каждой кафедры, могут включать следующие операции:
а) Ввод сведений о новом преподавателе.
Первичным ключом отношения Преподаватель является атрибут Табельный номер. Прежде всего, убедимся, что присвоенный новому преподавателю табельный номер является уникальным. Если это не так, ввод данных следует запретить, а выполнение операции завершить. В противном случае ввод данных о новом преподавателе разрешается. Проверьте, что для каждого элемента сведений о преподавателе в отношении Преподаватель имеется соответствующий атрибут.
б) Удаление сведений о преподавателе, заданном его табельным номером.
Выполняется поиск заданного табельного номера в соответствующем столбце отношения Преподаватель. Если он не будет найден, то фиксируется ошибка и никакие дальнейшие действия не выполняются. В противном случае из отношения Преподаватель удаляется весь найденный кортеж и обновляется внешний ключ всех кортежей других отношений, с которыми был связан "удаляемый" преподаватель.
Второй подход к проверке модели данных на соответствие требуемым транзакциям заключается в нанесении непосредственно на ER-диаграммы всех путей, которые потребуются для выполнения каждой из транзакций.
Простой пример использования этого подхода для контроля за выполнением упомянутых выше транзакций (а и б) показан на рис. 5.9.
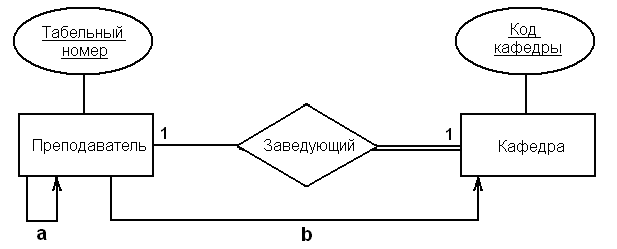
Рис. 5.9. Представление транзакций (а и б) на ЕR-диаграмме
Этот подход позволяет визуально выделить те области модели, которые не используются для выполнения транзакций, а также те области, которые наиболее существенны с точки зрения выполнения транзакций. В нашем распоряжении оказывается удобное средство прямого анализа поддержки, которую модель данных обеспечивает для выполнения необходимых транзакций пользователя. Если на диаграмме имеются области, которые не используются ни в одной из транзакций, возникает вопрос о целесообразности представления этой информации в модели данных. В то же время, если в модели присутствуют области, которые не позволяют найти подходящий метод выполнения некоторой транзакции, потребуется провести анализ того, какая из обязательных для выполнения транзакции сущностей или связей была пропущена при составлении модели.
Этап 2.5. Создание диаграмм „сущность-связь"
Цель: создание окончательного варианта диаграмм "сущность-связь" (ER-диаграмм), являющихся локальным логическим представлением данных, используемых отдельными пользователями приложения.
Теперь все готово для того, чтобы создать окончательные варианты ER-диаграмм для отдельных представлений каждого из пользователей предприятия. Данные на этих диаграммах были проверены с применением методов нормализации, а также проконтролированы на предмет возможности выполнения всех требуемых транзакций.
Этап 2.6. Определение требований поддержки целостности данных
Цель: определение ограничений, налагаемых в представлениях пользователей требованием сохранения целостности данных.
Ограничения целостности данных представляют собой такие ограничения, которые вводятся с целью предотвратить помещение в базу противоречивых данных. Отметим, что, хотя в конкретных СУБД функции контроля целостности могут, как поддерживаться, так и не поддерживаться, в данном случае это не будет интересовать. На этом этапе выполняется проектирование только на верхнем уровне, где рассмотрение вопросов целостности данных является обязательным условием, не связанным с конкретными аспектами реализации. Полное и точное отражение представления пользователя можно получить только после определения ограничений, необходимых с точки зрения сохранения целостности данных. При необходимости на основе локальной логической модели можно даже создать предварительный физический проект базы данных, который впоследствии может послужить прототипом системы для данного конкретного пользователя.
Здесь будут обсуждены пять типов ограничений целостности данных:
обязательные данные;
ограничения для доменов атрибутов;
целостность сущностей;
ссылочная целостность;
требования данного предприятия.
Обязательные данные
Некоторые атрибуты всегда должны содержать одно из допустимых значений. Другими словами, эти атрибуты не могут иметь пустого значения.
Так, каждый преподаватель должен преподавать тот или иной предмет.
Эти ограничения должны фиксироваться при занесении сведений об атрибуте в словарь данных (этап 1.3).
Ограничения для доменов атрибутов
Каждый атрибут имеет домен, представляющий собой набор его допустимых значений.
Например, атрибут "пол" может содержать одно из двух допустимых значений – "М" или "Ж", поэтому его домен состоит из двух символьных строк длиной в один символ, содержащих указанные значения.
Данные ограничения устанавливаются при определении доменов атрибутов, присутствующих в модели данных (этап 1.4).
Целостность сущностей
Первичный ключ любой сущности не может содержать пустого значения.
Например, каждая строка отношения Преподаватель должна содержать уникальное значение атрибута первичного ключа; в данном случае это – атрибут Табельный номер.
Подобные ограничения должны учитываться при определении первичных ключей для сущностей каждого типа (этап 1.5).
Ссылочная целостность
Внешний ключ связывает каждую строку дочернего отношения с той строкой родительского отношения, которая содержит это же значение соответствующего потенциального ключа. Понятие ссылочной целостности означает, что если внешний ключ содержит некоторое значение, то оно обязательно должно присутствовать в потенциальном ключе одной из строк родительского отношения.
Например, атрибут Код кафедры отношения Преподаватель связывает данные о каждом из преподавателей со строкой в отношении Кафедра, т.е. указывается к какой кафедре относится преподаватель. Если поле Код кафедры не пусто, оно должно содержать допустимое значение, присутствующее в атрибуте Код кафедры одной из строк отношения Кафедра. В противном случае окажется, что преподаватель относится к несуществующей кафедре.
Существует несколько важных моментов, связанных с использованием внешних ключей. Во-первых, следует проанализировать, допустимо ли использование во внешних ключах пустых значений. Например, имеет ли смысл сохранять сведения о преподавателе, если не задан код кафедры, к которой он относится? Вопрос не в проверке существования заданного кода кафедры, а в том, обязательно ли этот код должен указываться. В общем случае, если участие дочернего отношения в связи является тотальным, то рекомендуется запрещать использование пустых значений в соответствующем внешнем ключе. В то же время, если участие дочернего отношения в связи является частичным, то помещение пустых значений в атрибут внешнего ключа должно быть разрешено.
Следующая проблема связана с организацией поддержки ссылочной целостности. Реализация этой поддержки осуществляется посредством задания ограничений существования, определяющих условия, при которых может вставляться, обновляться или удаляться каждое значение потенциального или внешнего ключа. Для примера рассмотрим связь типа 1:М между двумя отношениями Факультет и Кафедра. Первичный ключ отношения Факультет – атрибут Название факультета – является внешним ключом отношения Кафедра. Рассмотрим следующие ситуации.
Случай 1. Вставка новой строки в дочернее отношение (Кафедра). Для обеспечения ссылочной целостности необходимо убедиться, что значение атрибута внешнего ключа Название факультета новой строки отношения Кафедра равно пустому значению либо некоторому конкретному значению, присутствующему в одной из строк отношения Факультет.
Случай 2. Удаление строки из дочернего отношения (Кафедра). При удалении строки из дочернего отношения никаких нарушений ссылочной целостности не происходит.
Случай 3. Обновление внешнего ключа в строке дочернего отношения (Кафедра). Этот случай подобен случаю 1. Для сохранения ссылочной целостности необходимо убедиться, что атрибут Название факультета в обновленной строке отношения Кафедра содержит либо пустое значение, либо некоторое конкретное значение, присутствующее в одной из строк отношения Факультет.
Случай 4. Вставка строки в родительское отношение (Факультет). Вставка строки в родительское отношение (Факультет) не может вызвать нарушения ссылочной целостности. Добавленная строка просто становится родительским объектом, не имеющим дочерних объектов.
Случай 5. Удаление строки из родительского отношения (Факультет). При удалении строки из родительского отношения ссылочная целостность будет нарушена в том случае, если в дочернем отношении будут существовать строки, ссылающиеся на удаленную строку родительского отношения. В этом случае может быть использована одна из следующих стратегий.
NO ACTION. Удаление строки из родительского отношения запрещается, если в дочернем отношении существует хотя бы одна ссылающаяся на нее строка.
CASCADE. При удалении строки из родительского отношения автоматически удаляются все ссылающиеся на нее строки дочернего отношения. Если любая из удаляемых строк дочернего отношения выступает в качестве родительской стороны в некоторой другой связи, то операция удаления применяется ко всем строкам дочернего отношения этой связи, и т.д.. Другими словами, удаление строки родительского отношения автоматически распространяется на любые дочерние отношения.
SET NULL. При удалении строки из родительского отношения во всех ссылающихся на нее строках дочернего отношения в атрибут внешнего ключа записывается пустое значение. Следовательно, удаление строк из родительского отношения вызовет занесение пустого значения в соответствующий атрибут строк дочернего отношения. Эта стратегия может использоваться только в тех случаях, когда в атрибут внешнего ключа дочернего отношения разрешается помещать пустые значения.
SET DEFAULT. При удалении строки из родительского отношения в атрибут внешнего ключа всех ссылающихся на нее строк дочернего отношения автоматически помещается значение, указанное для этого атрибута как значение по умолчанию. Таким образом, удаление строки из родительского отношения вызывает помещение принимаемого по умолчанию значения в атрибут внешнего ключа всех строк дочернего отношения, ссылающихся на удаленную строку. Эта стратегия применима только в тех случаях, когда атрибуту внешнего ключа дочернего отношения назначено некоторое значение, принимаемое по умолчанию.
NO CHECK. При удалении строки из родительского отношения никаких действий по сохранению ссылочной целостности данных не предпринимается.
Случай 6. Обновление первичного ключа в строке родительского отношения (Факультет). Если значение первичного ключа некоторой строки родительского отношения будет обновлено, нарушение ссылочной целостности будет иметь место в том случае, если в дочернем отношении существуют строки, ссылающиеся на исходное значение первичного ключа.
Для сохранения ссылочной целостности может использоваться любая из описанных выше стратегий. При использовании стратегии CASCADE обновление значения первичного ключа в строке родительского отношения будет отображено в любой строке дочернего отношения, ссылающейся на данную строку (каскадным образом).
Требования данного предприятия
В заключение требуется проанализировать ограничения, называемые ограничениями предприятия (или бизнес-правилами).
Например, обновление сущностей может регламентироваться принятыми на предприятии правилами, описывающими методы выполнения транзакций, связанных с подобными обновлениями.
Документирование всех ограничений целостности данных
Поместите сведения обо всех установленных ограничениях целостности данных в словарь данных. Они потребуются на этапе физической реализации базы данных.
Этап 2.7. Обсуждение разработанных локальных логических моделей данных с конечными пользователями
Цель: убедиться, что созданные локальные модели данных точно отражают представления пользователей о предметной области приложения.
На данный момент работа над локальными моделями данных, отражающих представления конкретных пользователей о работе предприятия, должна быть закончена и полностью отражена в документации. Однако прежде чем второй этап разработки можно будет считать полностью завершенным, необходимо обсудить с пользователями созданные логические модели данных и всю сопроводительную документацию.
Прежде чем перейти к третьему этапу, предусмотренному обсуждаемой методологией проектирования баз данных, бегло познакомимся с полезным дополнительным методом проверки локальных логических моделей данных, выполняемой с помощью диаграмм потоков данных.
Взаимосвязь между логическими моделями данных и диаграммами потоков данных
Логическая модель данных отображает структуру сохраняемых данных предприятия. Диаграмма потоков данных (Data Flow Diagram – DFD) отображает перемещение данных в пределах предприятия и помещение их в хранилища информации. Все атрибуты, которые сохраняются на предприятии, должны быть объявлены в одном из типов сущностей и, вероятно, найти свое место в потоках данных, перемещающихся в пределах предприятия. Если обе эти технологии используются для моделирования требований пользователей, каждая из них может применяться для контроля согласованности и полноты другой. Правила, которые определяют отношения между этими двумя технологиями, следующие:
каждое хранилище данных должно представлять все множество типов сущностей;
атрибуты в потоках данных должны принадлежать сущности того или иного типа.
Этап 3. Создание и проверка глобальной логической модели данных
Цель: объединение отдельных локальных логических моделей данных в единую глобальную логическую модель данных, представляющую ту часть предприятия, которая охватывается данным приложением.
На данном этапе фазы логического проектирования баз данных строится глобальная логическая модель данных, создаваемая посредством слияния отдельных логических моделей данных, отражающих представления каждого пользователя. По завершении объединения локальных моделей необходимо проверить правильность полученной глобальной модели, как в отношении правил нормализации, так и в отношении возможности выполнения транзакций, предусмотренных спецификациями на функции отдельных пользователей. Проверка выполняется с использованием тех же методов, которые применялись при выполнении этапов 2.3 и 2.4.
Однако проведение нормализации потребуется только в том случае, если в процессе слияния были внесены изменения в состав отдельных типов сущностей. Аналогично, проверка возможности выполнения транзакций выполняется только для тех областей модели, которые были подвергнуты изменениям в ходе слияния. В больших системах подобный подход позволяет существенно сократить объем требуемых повторных проверок.
Хотя каждая отдельная логическая модель данных предполагается корректной, полной и непротиворечивой, любая из них отражает лишь восприятие системы отдельным пользователем или группой пользователей. Другими словами, каждая модель отражает не функции предприятия, а лишь представление о функциях предприятия отдельных его сотрудников. Поэтому любая из этих моделей является неполной. А это означает, что между отдельными моделями в полном наборе представлений могут существовать несовместимость и взаимное перекрытие. Следовательно, при слиянии локальных моделей данных в единую глобальную модель придется прилагать усилия для устранения конфликтов между отдельными представлениями и принимать во внимание их возможное перекрытие.
Процедуру слияния можно считать самой важной в ходе логического проектирования базы данных, поскольку с ее помощью создается представление о предприятии, не зависящее от любых конкретных пользователей, бизнес-процессов или приложений.
Данный этап предусматривает выполнение следующих действий:
Этап 3.1. Слияние локальных логических моделей данных в единую
глобальную модель данных.
Этап 3.2. Проверка глобальной логической модели данных.
Этап 3.3. Проверка возможностей расширения модели в будущем.
Этап 3.4. Создание окончательного варианта диаграммы "сущность-связь".
Этап 3.5. Обсуждение глобальной логической модели данных с
пользователями.
Этап 3.1. Слияние локальных логических моделей данных в единую глобальную модель данных
Цель: объединить отдельные локальные логические модели данных в единую глобальную логическую модель данных предприятия.
В небольших системах, насчитывающих два-три пользовательских представления с незначительным количеством типов сущностей и связей, задача сравнения локальных моделей с последующим слиянием и устранением любых возможных противоречий является относительно несложной. Однако в крупных системах потребуется использовать более систематический подход. Ниже вашему вниманию предложен один из подобных подходов, который можно использовать для выполнения слияния локальных моделей и разрешения любых возникающих при этом проблем. Предлагаемый подход предусматривает выполнение следующих действий:
1. Анализ имен сущностей и их первичных ключей.
2. Анализ имен связей.
3. Слияние общих сущностей из отдельных локальных моделей.
4. Включение (без слияния) сущностей, уникальных для каждого локального
представления.
5. Слияние общих связей из отдельных локальных моделей.
6. Включение (без слияния) связей, уникальных для каждого локального
представления.
7. Проверка на наличие пропущенных сущностей и связей.
8. Проверка корректности внешних ключей.
9. Проверка соблюдения ограничений целостности.
10. Выполнение чертежа глобальной логической модели данных.
11. Обновление документации.
Вероятно, самый простой метод слияния нескольких локальных моделей данных в единую модель состоит в слиянии двух локальных моделей в одну общую модель, с последующим добавлением к ней третьей локальной модели (и т.д.). Процесс добавления к предыдущему результату очередной локальной модели будет продолжаться то тех пор, пока все модели не будут слиты в единую глобальную модель. Этот подход можно считать более простым, чем попытка слить все локальные модели за одну операцию.
Очень важно отметить, что, прежде чем приступать к созданию глобального представления информационной модели предприятия, следует убедиться, что каждая из сливаемых локальных логических моделей была создана в полном соответствии с последовательностью действий, предусмотренных первым и вторым этапами разработки, определенными в обсуждаемой методологии проектирования баз данных.
1. Анализ имен сущностей и их первичных ключей
Может оказаться полезным предварительно проанализировать имена сущностей присутствующих в локальных моделях данных, – эти сведения можно найти в словаре данных. Проблемы имеют место в следующих случаях:
если две или более сущностей имеют одно и то же имя, но на самом деле отличаются одна от другой;
если две или более сущностей идентичны, но имеют различные имена.
Для выявления возможных проблем следует сравнить между собой составы данных сущностей каждого типа. В частности, обнаружить эквивалентные сущности различными именами поможет сравнение их первичных ключей.
2. Анализ имен связей
Выполняемые действия аналогичны описанным на предыдущем этапе.
3. Слияние общих сущностей из отдельных локальных моделей
Теперь следует проанализировать имена и содержимое сущностей каждого типа, присутствующих в сливаемых логических моделях. Обычно эта процедура включает следующие действия:
слияние сущностей с одинаковыми именами и первичными ключами;
слияние сущностей с одинаковыми именами, но с различными первичными ключами;
слияние сущностей с различными именами, имеющих одинаковые или различные первичные ключи.
Слияние сущностей с одинаковыми именами и первичными ключами.
Как правило, сущности с одним и тем же первичным ключом представляют один и тот же объект реального мира и, следовательно, должны быть слиты. Объединенная сущность будет включать все атрибуты сливаемых сущностей, за исключением дублирующихся.
Например, в листинге 5.1 перечислены атрибуты, связанные с двумя сущностями, носящими имя Преподаватель, которые определены в двух различных представлениях, названных View l и View 2. В обоих, случаях первичным ключом является атрибут Табельный номер. Слияние этих сущностей осуществляется путем объединения их атрибутов, поэтому в сводной сущности Преподаватель будут присутствовать все атрибуты исходных сущностей. Отметим, что в данном случае имеет место конфликт, связанный со способом представления в каждой из исходных сущностей имени преподавателя. В подобной ситуации, прежде чем выбрать необходимый способ представления конфликтных данных, следует (по возможности) проконсультироваться с пользователями каждого из исходных представлений. Допустим, что в примере выбрано развернутое представление атрибута ФИО, т.е. разделение его в сводной сущности на атрибуты Фамилия и Имя_Отчество.
Листинг 5.1. Слияние сущностей Преподаватель из представлений View1 и View2
(Представление View1)
Преподаватель (Табельный номер, ФИО, Ученая степень, Код
кафедры)
Primary Key Табельный номер
Foreign Key Код кафедры references Кафедра (Код кафедры)
(Представление View2)
Преподаватель (Табельный номер, Фамилия, Имя_Отчество, Адрес,
Телефон, Код кафедры)
Primary Key Табельный номер
Foreign Key Код кафедры references Кафедра (Код кафедры)
(Глобальное представление)
Преподаватель (Табельный номер, Фамилия, Имя_Отчество, Ученая
степень, Адрес, Телефон, Код кафедры)
Primary Key Табельный номер
Foreign Key Код кафедры references Кафедра (Код кафедры)
Слияние сущностей с одинаковыми именами, но с различными первичными ключами.
В некоторых ситуациях могут быть обнаружены две сущности с одним и тем же именем, в которых используются различные первичные ключи, однако имеются одинаковые потенциальные ключи. В этом случае сущности сливаются аналогично тому, как это было сделано в предыдущем варианте. Дополнительно потребуется выбрать в результирующей сущности первичный ключ, объявив все остальные ключи альтернативными. В листинге 5.2 перечислены атрибуты двух сущностей Преподаватель, определенных в двух различных представлениях под именами View l и View 2. Первичным ключом сущности Преподаватель из представления View l является атрибут ФИО, а первичным ключом сущности Преподаватель из представления View 2 – атрибут Табельный номер. Однако, в сущности Преподаватель из представления View l определен альтернативный ключ Табельный номер, a в сущности Преподаватель из представления View 2 – альтернативный ключ (Фамилия, Имя_Отчество). Хотя первичные ключи в каждой из исходных сущностей различны, первичный ключ сущности Преподаватель из представления View l является альтернативным ключом сущности Преподаватель из представления View 2, и наоборот. Сущность, полученная в результате слияния двух исходных сущностей, аналогична результирующей сущности, представленной в листинге 5.1, однако в ней следует дополнительно определить альтернативный ключ (FName, LName).
Листинг 5.2. Слияние эквивалентных сущностей с различными первичными ключами
(Представление View1)
Преподаватель (Табельный номер, ФИО, Ученая степень, Код
кафедры)
Primary Key ФИО
Alternate Key Табельный номер
Foreign Key Код кафедры references Кафедра (Код кафедры)
(Представление View2)
Преподаватель (Табельный номер, Фамилия, Имя_Отчество, Адрес,
Телефон, Код кафедры)
Primary Key Табельный номер
Alternate Key Фамилия, Имя_Отчество
Foreign Key Код кафедры references Кафедра (Код кафедры)
(Глобальное представление)
Преподаватель (Табельный номер, Фамилия, Имя_Отчество, Ученая
степень, Адрес, Телефон, Код кафедры)
Primary Key Табельный номер
Alternate Key Фамилия, Имя_Отчество
Foreign Key Код кафедры references Кафедра (Код кафедры)
Слияние сущностей с различными именами, имеющих одинаковые или различные первичные ключи.
В некоторых случаях можно обнаружить сущности, которые имеют различные имена, но предназначены для одной и той же цели. Подобные эквивалентные сущности можно распознать по их именам, которые будут указывать на их сходное назначение, по их содержанию и по их первичным ключам. Кроме того, их можно распознать по участию в определенных связях. Типичным примером подобной ситуации является наличие в моделях сущностей с названиями Персонал и Преподаватель, которые, по сути, являются эквивалентными и должны быть слиты в единую сущность.
4. Включение (без слияния) сущностей, уникальных для каждого локального представления
На предыдущем этапе были выделены все сущности, описывающие подобные объекты. Все остальные сущности просто включаются в глобальную модель без внесения каких-либо изменений.
5. Слияние общих связей из отдельных локальных моделей
На этом этапе анализируются имена и назначение каждой из связей во всех представлениях отдельных пользователей. Прежде чем объединять связи, очень важно разрешить любые конфликты, которые могут иметь место между ними, – например, в отношении ограничений участия или кардинальности. Выполняемые на этом этапе действия включают слияние связей с одинаковыми именами и назначением, после чего может потребоваться выполнить слияние связей с различными именами, но имеющих одно и то же назначение.
6. Включение (без слияния) связей, уникальных для каждого локального представления
На предыдущем этапе были выявлены и слиты все связи, имевшие сходное назначение (по определению, эти связи должны существовать между одними и теми же сущностями, которые также должны быть слиты друг с другом). Все оставшиеся связи включаются в глобальную модель без каких-либо изменений.
7. Проверка на наличие пропущенных сущностей и связей
Вероятно, одной из самых трудных задач при создании глобальной модели данных является задача выявления пропущенных сущностей и связей между элементами представлений различных пользователей. Если на предприятии существует корпоративная модель данных, она может использоваться для обнаружения сущностей и связей между элементами представлений различных пользователей, которых нет ни в одном из локальных представлений. В то же время, при проведении опросов пользователей конкретного представления в качестве превентивной меры следует попросить их уделить некоторое внимание сущностям и связям, которые, по их мнению, могут существовать в других представлениях. Кроме того, при анализе атрибутов сущностей каждого типа можно попробовать выделить ссылки на сущности, принадлежащие другим пользовательским представлениям. Достаточно часто оказывается, что атрибут, связанный с той или иной сущностью в представлении одного пользователя, соответствует первичному ключу, альтернативному ключу или даже простому, не ключевому атрибуту некоторой сущности из другого представления.
8. Проверка корректности внешних ключей
На этом этапе может осуществляться слияние различных сущностей и связей, изменение первичных ключей и установка новых связей. Убедитесь, что внешние ключи в дочерних сущностях по-прежнему являются корректными, и в случае необходимости внесите в модель все требуемые изменения.
9. Проверка соблюдения ограничений целостности
Убедитесь, что установленные для глобальной логической модели ограничения целостности данных не вступают в противоречие с теми ограничениями, которые были установлены для каждого из пользовательских представлений. Любые конфликты следует устранять посредством проведения консультаций с пользователями.
10. Выполнение чертежа глобальной логической модели данных
На этом этапе рисуется окончательный вариант ER-диаграммы, представляющей глобальную логическую модель данных, полученную в результате слияния всех локальных моделей.
11. Обновление документации
Обновление документации выполняется с целью отображения любых изменений, вносимых в процессе создания глобальной логической модели данных из набора отдельных пользовательских представлений. Очень важно, чтобы документация всегда поддерживалась в актуальном состоянии и точно отражала текущее состояние модели данных. Если впоследствии в модель будут вноситься изменения, либо в ходе физической реализации базы данных, либо в процессе ее сопровождения, все внесенные изменения также должны немедленно фиксироваться в документации. Устаревшая документация часто является источником множества досадных ошибок и служит причиной принятия неверных решений.
Этап 3.2. Проверка глобальной логической модели данных
Цель: проверка глобальной логической модели данных с помощью методов нормализации и контроль возможности выполнения требуемых транзакций.
На этом этапе производятся действия, аналогичные тем, которые выполнялись на этапах 2.3 и 2.4 при проверке каждой из локальных логических моделей данных.
Этап 3.3. Проверка возможностей расширения модели в будущем
Цель: определение вероятности внесения каких-либо существенных изменений в созданную модель данных в обозримом будущем и оценка того, насколько данная модель приспособлена для этого.
Очень важно, чтобы созданная глобальная модель была легко расширяема. Если модель сможет поддерживать только текущие требования, то время ее существования будет весьма ограниченным, а для реализации поддержки новых или изменяющихся требований потребуется прилагать значительные усилия. Необходимо так построить модель, чтобы она была легко расширяема и позволяла реализовать поддержку новых требований с минимальными изменениями в работе уже существующих пользователей.
Следовательно, имеет смысл выполнить проверку созданной модели с точки зрения эффективности реализации новых требований, которые могут иметь место в будущем. Однако не следует вносить в модель каких-либо изменений, пока они не будут одобрены пользователями.
Этап 3.4. Создание окончательного варианта диаграммы „сущность-связь"
Цель: создание окончательного варианта диаграммы "сущность-связь", отображающей глобальную логическую модель данных предприятия.
Завершив все проверки созданной глобальной логической модели, можно приступить к подготовке окончательного варианта ER-диаграммы. Эта диаграмма должна представлять глобальную логическую модель данных той части предприятия, которая моделируется в данном приложении. Описывающая эту модель документация (включая схему отношений и словарь данных) должна быть обновлена и подготовлена в полном объеме.
Этап 3.5. Обсуждение глобальной логической модели данных с пользователями
Цель: убедиться, что созданная глобальная логическая модель данных адекватно отображает моделируемую часть информационной структуры предприятия.
Глобальная логическая модель данных предприятия к этому моменту должна быть полностью завершена и проверена. Сама модель и прилагаемая к ней документация предоставляются для просмотра и анализа конечным пользователям, которые должны убедиться, что она точно отображает структуру и функционирование предприятия.