

Создание семантических объектных моделей данных
В этом разделе иллюстрируется процесс разработки семантических объектов, в ходе которого разработчики анализируют интерфейс приложения (формы, отчеты, запросы) и двигаются в обратном направлении, получая из этой информации структуру объектов. Например, чтобы смоделировать структуру объекта ФАКУЛЬТЕТ, мы сначала собираем все отчеты, формы и запросы, связанные с факультетом. Исходя из них, мы определяем объект ФАКУЛЬТЕТ, который позволяет конструировать эти отчеты, формы и запросы.
Однако для абсолютно нового приложения в распоряжении разработчиков нет компьютерных отчетов, форм и запросов, которые можно было бы изучать. В этой ситуации разработчики начинают с определения того, какие объекты пользователи хотят отслеживать. Затем путем опроса пользователей команда выясняет, какие объектные атрибуты являются важными. На основе этой информации могут быть созданы прототипы форм и отчетов, с помощью которых модель данных будет далее уточняться.
Пример: база данных администрации нтуу «кпи»
Предположим, что администрация НТУУ «КПИ» желает вести учет данных по факультетам и кафедрам. Предположим, далее, что приложение должно генерировать четыре типа отчетов (рис. 3.21,3.23,3.25 и 3.27). Цель – изучить эти отчеты и, используя инженерный анализ, определить, какие объекты и атрибуты должны храниться в базе данных.
Объект ФАКУЛЬТЕТ
Отчет, изображенный на рис. 3.21, содержит информацию о факультете, а именно об Институте телекоммуникационных систем. Данный отчет – это только один частный пример. НТУУ «КПИ» имеет подобные отчеты и о других факультетах, в частности о факультете лингвистики и факультете менеджмента. Создавая модель данных, важно собрать достаточное количество примеров, чтобы на их основе можно было построить образец отчета о факультете. Здесь предположим, что отчет на рис. 3.21 является типичным.
Исследуя отчет, мы найдем данные, специфичные для данного факультета (название, имя директора, номер телефона и местный адрес, а также сведения о каждой из кафедр факультета). Это наводит на мысль о том, что база данных может содержать объекты ФАКУЛЬТЕТ и КАФЕДРА, а также связь между ними.
Эти предварительные заключения отражены в объектных диаграммах на рис. 3.22. Обратите внимание, что мы не указали кардинальность простых атрибутов, у которых она равна 0.1.
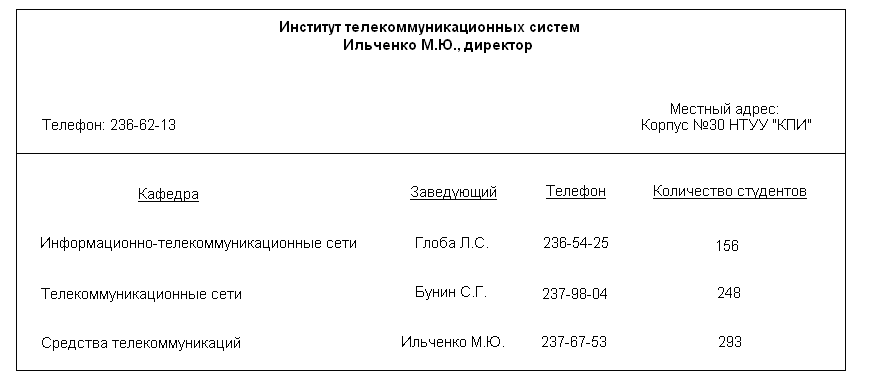
Рис. 3.21. Пример отчета о факультете.
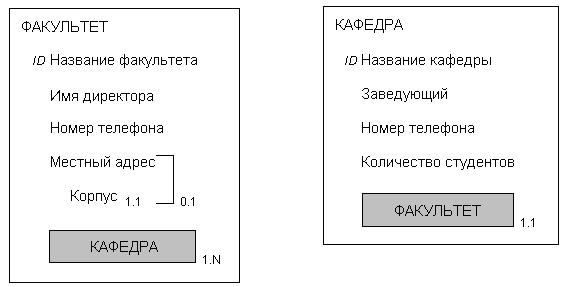
Рис. 3.22. Первая версия объектов ФАКУЛЬТЕТ и КАФЕДРА.
Кардинальность атрибута КАФЕДРА объекта ФАКУЛЬТЕТ равна 1.N – это означает, что факультет должен иметь как минимум одну кафедру и кафедр может быть много. Это минимальное кардинальное число не может быть выведено из отчета на рис. 3.21. Чтобы его получить, пользователям был задан вопрос о том, может ли существовать факультет без кафедр, и их ответ был отрицательным.
Также обратите внимание, что структура объекта КАФЕДРА выведена на основе данных, представленных на рис. 3.21. Поскольку объектные атрибуты всегда являются парными, объект ФАКУЛЬТЕТ показан внутри объекта КАФЕДРА, хотя, строго говоря, этот факт нельзя получить из анализа рис. 3.21. Как и в ситуации с атрибутом КАФЕДРА объекта ФАКУЛЬТЕТ, пользователей попросили определить кардинальность атрибута ФАКУЛЬТЕТ. Она равна 1.1, что означает, что кафедра может быть связана с одним и только одним факультетом.
По ходу изложения отчет на рис. 3.21 интерпретировали таким образом, что группы повторяющихся данных относятся к объекту КАФЕДРА как к независимому объекту. Фактически наличие таких групп часто является сигналом о том, что существует некий другой объект. Однако это не всегда так. Повторяющаяся группа может быть также групповым атрибутом, у которого оказалось несколько значений.
Возможно, будет интересно, как различить эти два типа повторяющихся данных – те, которые представляют объект, и те, которые представляют группу. Какого-либо твердого и четкого правила на этот счет не существует, поскольку ответ зависит от того, как пользователи представляют себе свой мир. Следовательно, наилучшим выходом будет спросить самих пользователей о семантике их данных. Спросите, являются ли эти повторяющиеся группы данных частью факультета, или они относятся к чему-то еще – чему-то самостоятельному. В первом случае они составляют групповой атрибут, во втором – семантический объект. Посмотрите также другие отчеты (или формы, или запросы). Имеются ли у пользователей отчеты по кафедрам? Если да, то предположение о том, что кафедра может быть представлена семантическим объектом, подтвердится. На самом деле персонал НТУУ «КПИ» работает с двумя видами отчетов по кафедрам. Этот факт еще более подтверждает мысль о том, что следует ввести объект под названием КАФЕДРА.
Далее, группы атрибутов, представляющие независимый объект, обычно содержат явный идентифицирующий атрибут или несколько атрибутов.
Объект КАФЕДРА
Отчет, представленный на рис. 3.23, содержит информацию о кафедрах, а также список работающих на них преподавателей. Обратите внимание, что этот отчет содержит местный адрес кафедры. Поскольку эти данные не присутствуют в версии объекта КАФЕДРА, изображенной на рис. 3.22, их необходимо добавить к объекту, как показано на рис. 3.24. Такое уточнение является типичным для процесса моделирования данных. То есть структура семантических объектов постоянно уточняется по мере того, как идентифицируются и анализируются новые отчеты, формы и запросы.

Рис. 3.23. Пример отчета о кафедре.
Объект ПРЕПОДАВАТЕЛЬ
Отчет на рис. 3.23 не только указывает на необходимость введения объекта КАФЕДРА, но и наводит на мысль, что для представления данных о профессоре может понадобиться еще один объект. Соответственно, в модель добавлен объект ПРЕПОДАВАТЕЛЬ, как показано на рис. 3.24. Идентификатор объекта ПРЕПОДАВАТЕЛЬ, которым является атрибут ФИО преподавателя, не является уникальным; на это указывает тот факт, что буквы ID на рис. 3.24 не подчеркнуты.
В соответствии с объектными диаграммами на рис. 3.24, на каждой кафедре должен быть как минимум один преподаватель, причем на одной кафедре преподавателей может быть несколько, но каждый преподаватель должен работать на одной и только на одной кафедре. Таким образом, согласно этой модели, работа по совместительству запрещена. Это ограничение является частью делового регламента, который должен определяться из опросов пользователей.
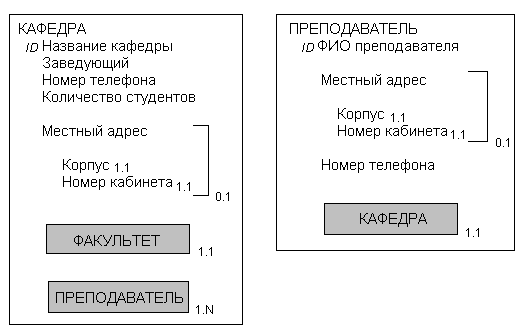
Рис. 3.24. Уточненный объект КАФЕДРА и новый объект ПРЕПОДАВАТЕЛЬ.
На рис. 3.25 показан второй отчет о кафедре. В нем представлена информация о кафедре и о студентах, специальность которых имеет отношение к этой кафедре. Ситуация, когда об одном объекте имеется два отчета, типична; эти отчеты просто документируют различные представления одного и того же объекта реального мира. Более того, существование второго отчета укрепляет уверенность в том, что кафедра является объектом в понимании пользователей.
Объект СТУДЕНТ
Отчет на рис. 3.25 содержит данные о студентах, профилирующая специальность которых относится к области деятельности данной кафедры, что подразумевает, что студенты также являются объектами. Поэтому объект КАФЕДРА должен также содержать объекты СТУДЕНТ и ПРЕПОДАВАТЕЛЬ, как показано на рис. 3.26.
 Рис.
3.25. Второй пример отчета о кафедре.
Рис.
3.25. Второй пример отчета о кафедре.
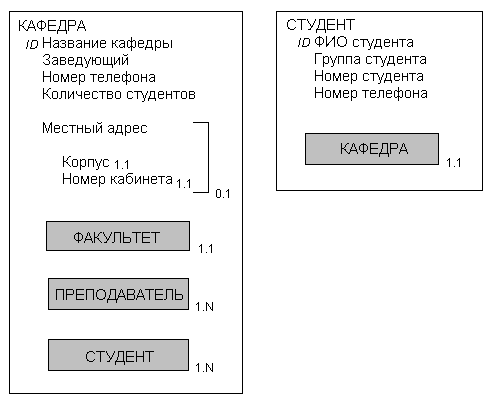
Рис. 3.26. Уточненный объект КАФЕДРА и новый объект СТУДЕНТ.
Объект СТУДЕНТ на рис. 3.26 имеет атрибуты ФИО студента, Группа студента, Номер студента и Номер телефона – атрибуты, перечисленные в отчете на рис. 3.25. Обратите внимание, что ФИО студента не является уникальным идентификатором.
На рис. 3.27 представлен другой пример отчета о студентах – письмо-приглашение, которое университет рассылает поступившим в него студентам. Даже, несмотря на то, что это письмо, оно все же является отчетом.
Те элементы данных в письме, которые должны храниться в базе данных, напечатаны жирным шрифтом. Кроме данных, относящихся к студенту, письмо также содержит данные о профильной кафедре студента и о его руководителе. Поскольку руководитель является преподавателем, это письмо подтверждает потребность в отдельном объекте под названием ПРЕПОДАВАТЕЛЬ.

Рис. 3.27. Письмо-приглашение.
Уточненные диаграммы объектов ПРЕПОДАВАТЕЛЬ и СТУДЕНТ представлены на рис. 3.28. Глядя, на объект СТУДЕНТ, можно видеть, что как КАФЕДРА, так и ПРЕПОДАВАТЕЛЬ имеют единственное значение (их максимальное кардинальное число равно 1). Следовательно, студент этого университета имеет максимум одну профильную кафедру и одного руководителя, причем имеет обязательно.
Объект СТУДЕНТ на рис. 3.28 соответствует данным, изображенным на рис. 3.27. Может, однако, оказаться, что студент имеет более одной специальности, и тогда атрибуты КАФЕДРА и ПРЕПОДАВАТЕЛЬ будут многозначными. Этот факт не может быть выявлен из единственного стандартного письма, которое было представлено, поэтому требуется проанализировать другие письма и провести дополнительные опросы, чтобы определить, разрешено ли иметь несколько профилирующих специальностей. Здесь мы предполагаем, что такая специальность может быть только одна.
ФИО студента дается сначала в формате Фамилия Имя Отчество в верхней строчке письма, а затем в формате Имя Отчество в приветствии. ФИО руководителя также дается в формате {Фамилия, Имя, Отчество}.
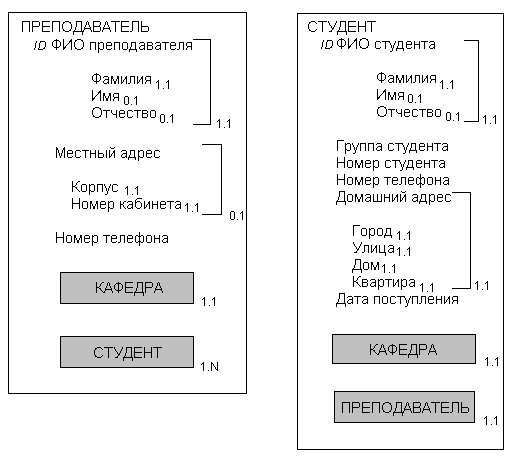
Рис. 3.28. Уточненные объекты ПРЕПОДАВАТЕЛЬ и СТУДЕНТ.
Опять-таки, эти изменения иллюстрируют итеративную природу моделирования данных. Имеющиеся решения часто приходится пересматривать и корректировать вновь и вновь. Это не означает, что процесс проектирования идет с ошибками; фактически, такие итерации являются обычными и ожидаемыми.