

2.2 Паралельні алгоритми
Поняття паралельного алгоритму (Parallel Algorithm) відноситься до фундаментальних в теорії обчислювальних систем. Це поняття, перш за все, асоціюється з обчислювальними системами з масовим паралелізмом. Паралельний алгоритм - це опис процесу обробки інформації, орієнтований на реалізацію в колективі обчислювачів. Такий алгоритм, на відміну від послідовного, передбачає одночасне виконання множини операцій в межах одного кроку обчислень і як послідовний алгоритм зберігає залежність подальших етапів від результатів попередніх.
Паралельний алгоритм рішення задачі складає основу паралельної програми. Паралельна програма у свою чергу, впливає на алгоритм функціонування колективу обчислювачів. Запис паралельного алгоритму на мові програмування, доступній колективу обчислювачів, називають паралельною програмою. Паралельні алгоритми і програми слід розробляти для складних або трудомістких завдань.
Методи і алгоритми обробки інформації, рішення задач, як правило, - послідовні. Процес “пристосування” методів до реалізації на колективі обчислювачів або процес “розщеплювання” послідовних алгоритмів рішення складних задач називається розпаралелюванням (Paralleling or Multisequencing).
Теоретична і практична діяльність по створенню паралельних алгоритмів і програм обробки інформації називається паралельним програмуванням (Parallel or Concurrent Programming). Якість паралельного алгоритму (або його ефективність) визначається методикою розпаралелювання складних завдань.
Існує два підходи при розпаралелюванні завдань: локальне і глобальне (великоблочне) розпаралелювання (рис.2.3). Перший підхід орієнтований на розкладання алгоритму рішення складної задачі на гранично прості блоки (операції або оператори) і вимагає виділення для кожного етапу обчислень максимально можливої кількості одночасно виконуваних блоків. Процес такого розпаралелювання дуже трудомісткий, а отримувані паралельні алгоритми характеризуються не тільки структурною неоднорідністю, але і істотно різними об'ємами операцій на різних етапах обчислень. Останнє є серйозною перешкодою на шляху (автоматизації) розпаралелювання і забезпечення ефективної експлуатації ресурсів колективу обчислювачів. Локальне розпаралелювання дозволяє оцінити граничні можливості колективу обчислювачів при рішенні складних задач, отримати граничні оцінки по розпаралелюванню складних завдань.
Другий підхід орієнтований на розбиття складного завдання на великі блоки-підзадачі, між якими існує слабкий зв'язок. Тоді в алгоритмах, побудованих на основі великоблочного розпаралелювання, операції обміну між підзадачами складатимуть незначну частину в порівнянні із загальним числом операцій в кожній підзадачі. Такі підзадачі називають гілками паралельного алгоритму, а відповідні їм програми - гілками паралельної програми.
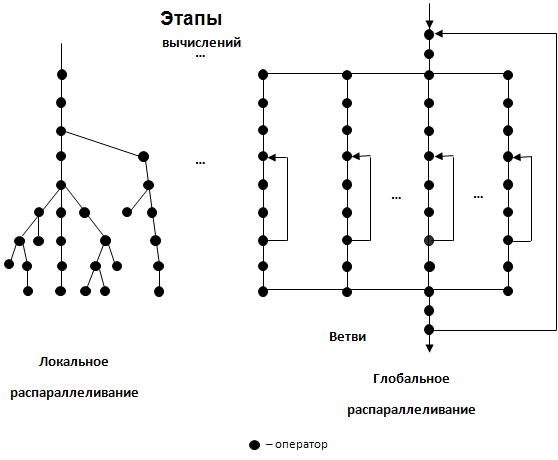
Рисунок 2.3 - Схеми паралельних алгоритмів
Одним з конструктивних прийомів великоблочного розпаралелювання складних завдань є розпаралелювання по циклах. Прийом дозволяє представити процес рішення задачі у вигляді паралельних гілок, отриманих розщеплюванням циклу на частини, число яких рівне числу повторень циклу. На вході і виході з циклу процес обчислень - послідовний; частка послідовних ділянок в загальному часі рішення задачі незначна.
Як правило, послідовні ділянки мають місце на початку і в кінці паралельної програми. На початковій ділянці здійснюється ініціалізація програми і введення початкових даних, а на кінцевому - виведення результатів (запис в архівні файли). Також можливі реалізації паралельного введення і виведення інформації.
Послідовні ділянки в паралельній програмі також можуть мати місце, якщо використовуються негрупові обміни інформацією між гілками (обчислювачами).
Паралелізм - основа високопродуктивної роботи всіх підсистем обчислювальних машин. Організація пам'яті будь-якого рівня ієрархії, організація системного введення/виведення, організація мультиплексування шин і т.д. базуються на принципах паралельної обробки запитів. Сучасні операційні системи є багатозадачними і розрахованими на багато користувачів, імітують паралельне виконання програм за допомогою механізму переривань.
Розвиток процессоробудування також орієнтований на розпаралелювання операцій, тобто на виконання процесором більшого числа операцій за такт. Ключовими ступенями розвитку архітектури процесорів стали гіперконвеєризація, суперскалярність, векторне процесування (технологія SIMD), архітектура VLIW. Всі ступені були орієнтовані на підвищення ступеня паралелізму виконання.
В даний час суперсервера є мультипроцесорними системами, а в процесорах активно використовується паралелізм рівня потоків.
Розпаралелювання операцій - перспективний шлях підвищення продуктивності обчислень. Згідно закону Мура число транзисторів експоненціально росте, що дозволяє в даний час включати до складу CPU велику кількість виконавчих пристроїв самого різного призначення.
У 70-і роки став активно застосовуватися принцип конвеєризації обчислень. Конвеєр Intel Pentium 4 складається з 20 ступенів. Таке розпаралелювання на мікрорівні - перший крок на шляху еволюції процесорів (рис.2.4). На принципах конвеєризації базуються і зовнішні пристрої. Наприклад, динамічна пам'ять (організація чергування банків) або зовнішня пам'ять (організація RAID).
Використання паралелізму мікрорівня дозволяло лише зменшувати CPI (Cycles Per Instruction - число тактів, необхідних для виконання однієї інструкції), оскільки мільйони транзисторів при виконанні одиночної інструкції простоювали. CPI = загальна кількість тактів / число виконаних команд.
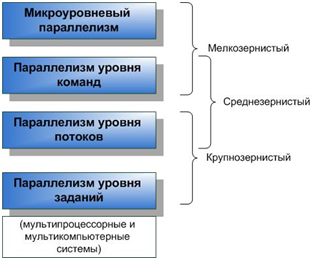
Рисунок 2.4 – Рівні паралелізму
На наступному етапі еволюції в 80-і роки стали використовувати паралелізм рівня команд за допомогою розміщення в CPU відразу декількох конвеєрів (рис.2.4). Такі суперскалярні CPU дозволяли досягати CPI<2.
Сучасні методики підвищення ILP засновані на використанні процесорів класу SIMD. Це векторне процесування, матричні процесори, архітектура VLIW.
Паралелізм рівня потоків і рівня завдань застосовується в процесорах класу MIMD (рис.2.4).
Паралелізм всіх рівнів властивий не тільки процесорам загального призначення (GPP), але і процесорам спеціального призначення (ASP (Application-Specific Processor), DSP (Digital Signal Processor)).
Іноді класифікують паралелізм по ступені гранулярності як відношення об'єму обчислень до об'єму комунікацій. Розрізняють дрібнозернистий, средньозернистий і грубозернистий паралелізм.
Дрібнозернистий паралелізм забезпечує сам CPU, а компілятор може і повинен йому допомогти.
Средньозернистий паралелізм - реалізується програмістом, який розробляє багатопотокові алгоритми. Тут роль компілятора полягає у виборі оптимальної послідовності інструкцій.
Грубозернистий паралелізм забезпечує ОС.
Системи (мови) паралельного програмування
В рамках паралельної моделі програмування існують різні підходи, орієнтовані на різну архітектуру високопродуктивних обчислювальних систем і різні інструментальні засоби. Перерахуємо деякі з них.
Модель передачі повідомлень
Основні особливості даного підходу:
- програма породжує декілька завдань;
- кожному завданню привласнюється свій унікальний ідентифікатор;
- взаємодія здійснюється за допомогою відправки і прийому повідомлень;
- нові завдання можуть створюватися під час виконання паралельної програми, декілька завдань можуть виконуватися на одному процесорі.
Основними інструментами програмування є спеціалізовані бібліотеки (MPI - Message Passing Interface, PVM - Parallel Virtual Machines).
Модель паралелізму даних
Основні особливості даного підходу:
- одна операція застосовується до безлічі елементів структури даних. Програма містить послідовність таких операцій;
- "зернистість" обчислень мала;
- програміст повинен вказати транслятору, як дані слід розподілити між завданнями;
- при програмуванні на основі паралелізму даних часто використовуються спеціалізовані мови або надбудови над мовами DVM Fortran, HPF (High Perfomance Fortran) та інші.