

Контрольні запитання
1 На які підкласи ділиться клас комп’ютерних систем SIMD?
2 Коли була розроблена комп’ютерна система ILLIAC IV?
3 Що означає термін “квадрант”?
Лекція № 6 Мультипроцесорні комп’ютерні системи
6.1 Загальна характеристика мультипроцесорних комп’ютерних систем
В мультипроцесорних КС спільним ресурсом є оперативна пам’ять. Паралельна робота процесорів і використання загальної оперативної пам’яті забезпечується управлінням єдиної операційної системи.
В мультипроцесорних КС швидкодія і надійність істотно вищі від аналогічних показників мультикомп’ютерних КС, що взаємодіють на рівні каналів зв'язку. Це відбувається, по-перше, завдяки більш швидкому обміну інформацією між процесорами і швидшому реагуванню на ситуації, що виникають у системі, по-друге, унаслідок більшого ступеня резервування пристроїв системи (система зберігає працездатність, поки працездатні хоч би по одному модулю кожного типу пристроїв).
В більшості випадків мультипроцесорні КС реалізовані в суперкомп'ютерах. Багато дослідників вважають, що використання мультипроцесорних КС є основним шляхом розвитку обчислювальної техніки нових поколінь.
Якщо всі процесори мають рівний доступ до всіх модулів пам'яті і до всіх пристроїв введення/виведення і кожен процесор взаємозамінний з іншими процесорами, то така система називається симетричним мультипроцесором (SMP - Symmetric Multiprocessor), якщо ні, то така система називається асиметричним мультипроцесором (АSMP).
Симетричні мультипроцесорні КС (SMP) бувають з архітектурою UMA, COMA, NUMA.
У системах із загальною пам'яттю всі процесори мають рівні можливості по доступу до єдиного адресного простору. Єдина пам'ять може бути побудована як одноблокова або за модульним принципом, але зазвичай практикується другий варіант.
Обчислювальні системи із загальною пам'яттю, де доступ будь-якого процесора до пам'яті проводиться одноково і займає однаковий час, називають системами з однорідним доступом до пам'яті і позначають абревіатурою UMA (Uniform Memory Access). Це найбільш поширена архітектура пам'яті паралельних КС із загальною пам'яттю.
Технічно UMA-системи припускають наявність вузла, що сполучає кожний з процесорів з кожним з модулів пам'яті. Найпростіший шлях побудови таких КС - об'єднання декількох процесорів з єдиною пам'яттю за допомогою загальної шини (рис.6.1). Проте, в цьому випадку в кожен момент часу обмін по шині може вести тільки один з процесорів, тобто процесори повинні змагатися за доступ до шини. Коли процесор Рi, вибирає з пам'яті команду, решта процесорів повинна чекати, поки шина звільниться. Якщо в систему входять тільки два процесори, вони в змозі працювати з продуктивністю, близькою до максимальної, оскільки їх доступ до шини можна чергувати (поки один процесор декодує і виконує команду, інший має право використовувати шину для вибору з пам'яті наступної команди). Проте коли додається третій процесор, продуктивність починає падати (рис.6.2). За наявності на шині десяти процесорів, крива швидкодії шини стає горизонтальною, так що додавання 11-го процесора вже не дає підвищення продуктивності (рис.6.2). Тому дана схема широкого застосування не знайшла.
Можна оптимізувати архітектуру UMA, додаючи локальний кеш і локальну пам'ять до кожного з процесорів (рис.6.3).
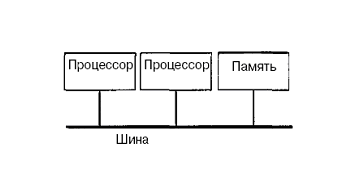
Рисунок 6.1 – Архітектура UMA
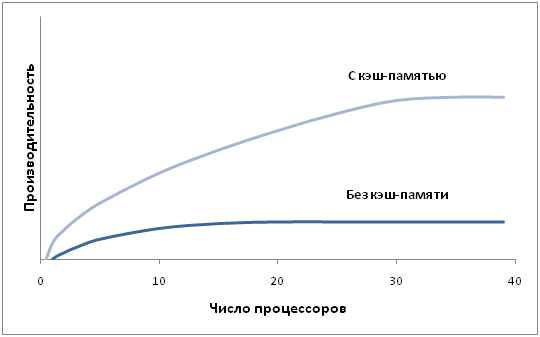
Рисунок 6.2 – Продуктивність багатопроцесорних КС з архітектурою UMA
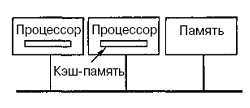
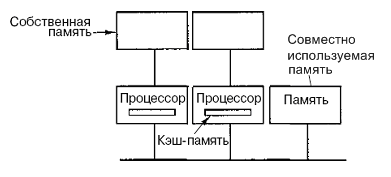
Рисунок 6.3 – Оптимізована архітектура UMA
Щоб оптимально використовувати конфігурацію вказану на рис.6.3, компілятор повинен помістити в локальні модулі пам'яті весь текст програми, ланцюжки, константи, інші дані, призначені тільки для читання, стечи і локальні змінні. Загальна розділена пам'ять використовується тільки для загальних змінних. В більшості випадків таке розумне розміщення сильно скорочує кількість даних, що передаються по шині, і не вимагає активного втручання з боку компілятора.
Навіть при всіх можливих оптимізаціях використання тільки однієї шини обмежує розмір мультипроцесора UMA до 16 або 32 процесорів. Щоб отримати більший розмір, потрібний інший тип комунікаційної мережі. Найпростіша схема з'єднання n процесорів з k блоками пам'яті через координатний комутатор (рис.6.4). Координатні комутатори використовуються впродовж багатьох десятиліть для з'єднання групи вхідних ліній з рядом вихідних ліній довільним чином.
Координатний комутатор є мережею, що не блокується. Це означає, що процесор завжди буде зв'язаний з потрібним блоком пам'яті, навіть якщо якась лінія або вузол вже зайняті. Більш того, ніякого попереднього планування не потрібно.
Недолік системи: зростання вузлів як n2. За наявності 1000 процесорів і 1000 модулів пам'яті отримуємо число вузлів - 1 млн. Це неприйнятно. Проте координатні комутатори можна застосовувати для систем середніх розмірів.
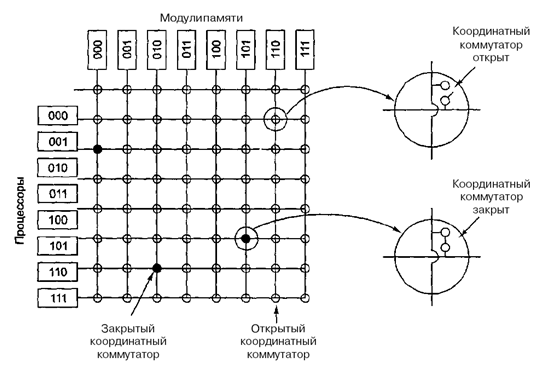
Рисунок 6.4 – Координатний комутатор