

Лабораторные работы № 8, 9
Линейная, экспоненциальная и полиномиальная регрессия
Цель работы:
Изучить методы проведения регрессионного танализа экспериментальных данных.
Литература:
Чернышов Ю. Н. Информационные технологии в экономике и управлении : учеб. пособие для вузов / Ю. Н. Чернышов .- 2-е изд., испр. и доп.- М. : Горячая линия - Телеком, 2008
Рагулина М. И. Информационные технологии в математике : учеб. пособие для студ. вузов / Рагулина М. И.; под ред. М. П. Лапчика .- М. : Академия, 2008.
Сырецкий Г.А. Информатика. Фундаментальный курс. Том 1, 2. – Москва, 2005- 234с.
Интернет-технологии в экономике знаний : учебник / под ред. Н. М. Абдикеева .- М. : ИНФРА-М, 2010
Основное оборудование:
ПЭВМ.
Электронные таблицы Microsoft Excel.
Среда математической обработки данных MathCad..
Задание:
Изучить теоретический материал по теме «Линейная, экспоненциальная и полиномиальная регрессия».
Решить задачи с помощью программ Excel и MathCad.
Составить отчет по работе.
Теоретические сведения
Линейная регрессия
В технике часто возникает задача подбора функциональной зависимости для двух наборов данных. Независимые переменные х называют факторами, а зависимые у — откликами. Функция у = f(x) позволяет предсказывать значение отклика для факторов, не входящих в исходную совокупность.
Так как задача отыскания функциональной зависимости очень важна, в Excel введен набор функций, которые позволяют решать эту задачу. Эти функции основаны на методе наименьших квадратов. Но регрессионный анализ — это не только метод наименьших квадратов. Относительно исходных данных делаются некоторые статистические предположения. В качестве результата выдаются не только коэффициенты функции, приближающей данные, но и статистические характеристики полученных результатов.
Рассмотрим основные функции, используемые для регрессионного анализа.
Функция ЛИНЕЙН(известные_значения_y; известные_значения_x; конст; статистика) рассчитывает статистику для ряда данных с применением метода наименьших квадратов, чтобы вычислить коэффициенты уравнения прямой, которая наилучшим образом аппроксимирует имеющиеся данные. Функция возвращает массив, который описывает полученную прямую. Поскольку возвращается массив значений, функция должна задаваться в виде табличной формулы. ЛИНЕЙН может также возвращать дополнительную регрессионную статистику.
Известные_значения_y - это множество значений y, которые уже известны для соотношения y = mx + b.
Известные_значения_x - это необязательное множество значений x, которые уже известны для соотношения y = mx + b. Если известные_значения_x опущены, то предполагается, что это массив {1;2;3;...} такого же размера как и известные_значения_y.
Конст - это логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0. Если конст имеет значение ИСТИНА или опущено, то b вычисляется обычным образом. Если конст имеет значение ЛОЖЬ, то b полагается равным 0 и значения m подбираются так, чтобы выполнялось соотношение y = mx.
Статистика - это логическое значение, которое указывает, требуется ли вернуть дополнительную статистику по регрессии. Если статистика имеет значение ИСТИНА, то функция ЛИНЕЙН возвращает дополнительную регрессионную статистику. Если статистика имеет значение ЛОЖЬ или опущена, то функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b.
Вместо ИСТИНА и ЛОЖЬ в функцию можно вводить аргументы 1 и 0, что намного удобнее.
Рассмотрим решение задачи линейной регрессии с помощью функции ЛИНЕЙН на примере.
Пример.
Дан набор экспериментальных данных Хi = {0, 1, 2, 3, 4} и Yi = {3, 1, 6, 3, 7}. Найти коэффициенты m и b прямой линии y = mx + b, наилучшим образом аппроксимирующей эти данные.
Решение.
Ввести массив Хi диапазон А2:А6.
Ввести массив Yi диапазон В2:В6.
Так как функция возвращает сразу несколько значений, формулу с этой функцией надо вводить как табличную. Для получения полной статистики, надо выделить блок из пяти строк и двух столбцов. Поэтому выделим блок D2:E6.
В Мастере функций выбрать в категории "Статистические" функцию ЛИНЕИН.
С помощью навигатора заполнить аргументы так, как показано на рис.1.6.
Нажать комбинацию клавиш Ctrl+Shift+Enter.
Результат решения задачи приведен на рисунке.
В ячейку D2 записан коэффициент т, в E2 — коэффициент b. Под этими коэффициентами записаны стандартные отклонения (т.е. среднеквадратичные отклонения, или корни квадратные из дисперсий) для этих коэффициентов.
В ячейку D4 записан так называемый коэффициент детерминации. Этот коэффициент лежит на отрезке [0; I]. Считается, что чем ближе этот коэффициент к 1, тем лучше регрессионное уравнение описывает зависимость.
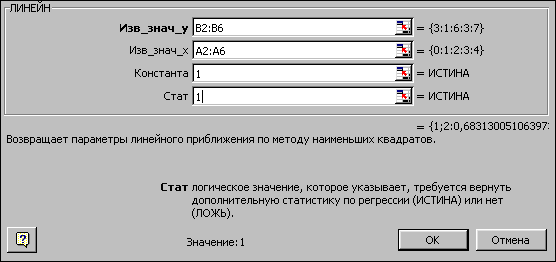
Рис. Заполнение аргументов функции ЛИНЕЙН.
В ячейке E4 находится стандартная ошибка для оценки у. В ячейку D5 записано значение F-статистики, а в E5 — количество степеней свободы. Число степеней свободы нужно для расчета критических значений F-статистики (этого вопроса мы касаться не будем).
В последней строке таблицы записаны регрессионная сумма квадратов и сумма квадратов остатков.
Для того чтобы осмыслить значения этих статистических оценок, нужны серьезные познания в области математической статистики.
Наиболее важными являются коэффициенты т и b. Их можно вычислить с помощью функций НАКЛОН и ОТРЕЗОК, не прибегая к функции ЛИНЕИН. Названия этих функций отвечают геометрическому смыслу коэффициентов регрессии: т — это тангенс угла наклона прямой регрессии, a b — отрезок, отсекаемый этой прямой на оси ординат.
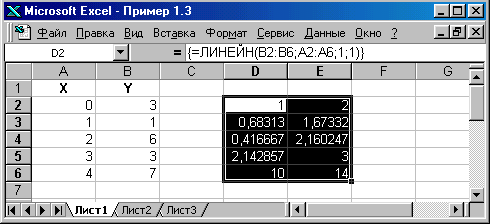
Рис. Решение задачи линейной регрессии с помощью функции ЛИНЕЙН.
Функция НАКЛОН(известные_значения_y; известные_значения_x) и функция ОТРЕЗОК(известные_значения_y; известные_значения_x) имеют одинаковый набор аргументов.
Известные_значения_y - это массив или интервал ячеек, содержащих числовые зависимые точки данных.
Известные_значения_x - это множество независимых точек данных.
Аргументы функций должны быть числами или именами, массивами или ссылками, содержащими числа. Если аргумент, который является массивом или ссылкой, содержит тексты, логические значения или пустые ячейки, то такие значения игнорируются; однако, ячейки с нулевыми значениями учитываются.
Если известные_значения_y и известные_значения_x пусты или содержат различное число точек данных, то функции возвращают значение ошибки #Н/Д.
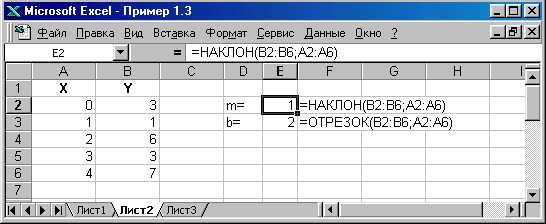
Рис. Использование функций НАКЛОН и ОТРЕЗОК для вычисления
коэффициентов регрессионной прямой.
На рисунке приведен второй способ решения задачи из рассмотренного примера. Очевидно, что результаты решения задачи разными способами совпадают.
В некоторых случаях при решении экономических задач можно и не вычислять коэффициенты регрессионного уравнения. Ведь они нужны для оценки откликов для старых и новых значений факторов. (Старые значения — те, на основе которых вычислялось уравнение регрессии.) Для этого служат две функции: ТЕНДЕНЦИЯ и ПРЕДСКАЗ.
Функция ТЕНДЕНЦИЯ (известные_значения_y; известные_значения_x; новые_значения_x; конст) возвращает значения в соответствии с линейным трендом. Аппроксимирует прямой линией (по методу наименьших квадратов) массивы известные_значения_y и известные_значения_x. Возвращает значения y, в соответствии с этой прямой для заданного массива новые_значения_x.
Функция ПРЕДСКАЗ(x; известные_значения_y; известные_значения_x) вычисляет или предсказывает будущее значение по существующим значениям. Предсказываемое значение - это y-значение, соответствующее заданному x-значению.