

Прототип системы OntoSeek
Разработка и реализация прототипа системы «содержательного» доступа к WWW-ресурсам OntoSeek - результат 2-летней работы, выполненной в кооперации Corinto (Consorzio di Ricerca Nazionale Tecnologia Oggetti - National Research Consortium for Object Technology) и Ladseb-CNR (National Research Council - Institute of Systems Science and Biomedical Engineering), как части проекта по поиску и повторному использованию программных компонентов [Guarino, et al., 1999].
Система OntoSeek разработана для содержательного извлечения информации из доступных в режиме on-line «желтых» страниц (yellow pages) и каталогов. В рамках системы совместно используются механизмы поиска по содержанию, управляемые соответствующей онтологией (ontology-driven content-matching mechanism), и достаточно мощный формализм представления.
При создании OntoSeek были приняты следующие проектные решения:
• использование ограниченного числа ЕЯ-терминов для точного описания ресурсов на фазе кодирования;
• полная «терминологическая свобода» в запросах за счет управляемого онтологией семантического отображения их на описания ресурсов;
• интерактивное ассистирование пользователю в процессе формулировки запроса, его обобщения и/или конкретизации, а также приняты во внимание:
♦ текущее состояние исследований в области Интернет-архитектур;
♦ необходимость достижения высокой точности и приемлемой эффективности на больших массивах данных;
♦ важность хорошей масштабируемости и портабельности принимаемых решений.
Система работает как с гомогенными, так и с гетерогенными каталогами продуктов. Понятно, что второй вариант сложнее. Поэтому в системе OntoSeek для представления запросов и описания ресурсов используется модификация простых концептуальных графов Дж. Совы [Sowa, 1984], которые обладают существенно более мощными выразительными возможностями и гибкостью по сравнению с обычно используемыми списками типа «атрибут-значение». Для концептуальных графов проблема контекстного отождествления редуцируется до управляемого онтологией поиска в графе. При этом узлы и дуги сопоставимы, если онтология «показывает», что между ними существует заданное отношение. Вместе с тем, поскольку система базируется на использовании лингвистической онтологии, узлы концептуального графа должны быть привязаны к соответствующим лексическим единицам, причем для этого должны выполняться определенные семантические ограничения.
На этапе планирования проекта вместо разработки собственной лингвистической онтологии были проанализированы доступные Интернет-ресурсы и выбрана онтология Sensus [Knight et al., 1994], которая обладает простой таксономической структурой, имеет объем около 50 000 узлов, в основном выделенных из тезауруса WordNet [Beckwith et al., 1990], а также доступна для исследовательских целей в свободном режиме.
Функциональная структура системы OntoSeek представлена на рис. 9.10.
На фазе кодирования описание ресурсов конвертируется в концептуальный граф. Для этого «поверхностные» узлы и дуги, отмеченные пользователем, с помощью лексического интерфейса трансформируются в смыслы, заданные в словаре. Таким образом, «граф слов» транслируется в «граф смыслов», причем каждому понятию последнего сопоставляется соответствующий узел онтологии. После семантической валидации концептуального графа на основе использования онтологии он запоминается в БД.
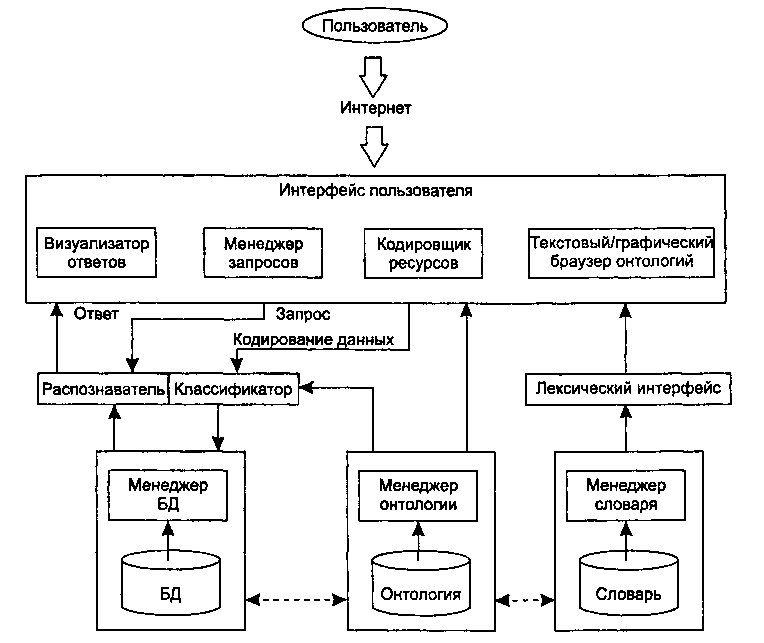
Рис. 9.10. Функциональная структура системы OntoSeek
Наиболее интересным моментом этапа кодирования ресурсов в системе OntoSeek является формализм представления помеченных концептуальных графов (ПКГ), который базируется на том, что заданы словари существительных и глаголов, а собственно ПКГ определяется как связный ориентированный граф, удовлетворяющий следующим синтаксическим ограничениям:
• Дуги могут быть помечены только существительными из словаря (любой граф, содержащий дугу, помеченную транзитивной конструкцией вида [<URLl>man] → (love) → [women], может быть конвертирован в базисный ПКГ вида [<URLl>man] ← (agent) ← [love] → (patient) → [women]).
• В общем случае узлы помечаются строками вида concept [instance], где concept существительное или глагол из словаря, а необязательная ссылка: instance - управляющий идентификатор.
• Для каждого графа существует в точности один узел, называемый «головой». Этот узел маркируется URL в угловых скобках, идентифицирующим файл описания ресурса, который описывает данный граф, и маркерной строки, представляющей понятие онтологии.
Понятно, что прежде, чем использовать этот граф, должна быть устранена полисемия, что может позволить однозначно отразить существующие метки в понятия онтологии. После выполнения этой процедуры семантическая интерпретация ПКГ происходит следующим образом:
• каждый узел, помеченный «словом» А, представляет класс экземпляров соответствующего концепта. При наличии в описании идентификатора экземпляра узел определяет синглетон, содержащий этот экземпляр. Если А - глагол, узел фиксирует его номинализацию (например, узел с пометкой «love» определяет класс событий «любить»);
• каждая дуга с пометкой С из узла А в узел В определяет соответствующее непустое отношение;
• в целом граф с «головой» А и URL U определяют класс экземпляров А, описываемых ресурсом, помеченным U.
Процесс поиска осуществляется следующим образом. Пользователь представляет свой запрос тоже в виде концептуального графа, который после устранения лексической неоднозначности и семантической валидации передается компоненте отождествления, работающей с БД. Здесь ищутся графы, удовлетворяющие запросу и ограничениям, заданным в онтологии, после чего ответ представляется пользователю в виде HTML-отчета.
Семантика графа запроса и процедура его построения аналогичны рассмотренной выше процедуре кодирования ресурсов, но имеет следующие отличия:
• на месте URL может быть задана переменная;
• переменными может быть помечено произвольное число узлов.
Так, например, запрос вида [<Х> саr] → (part) → [radio] вернет множество URL на документы, описывающие автомобили с радиоприемниками в качестве части, а запрос вида [саr] → (part) → [<Х> radio] - множество URL на документы, описывающие радиоприемник как часть автомобиля. И более того, композиция этих запросов вида [<Х> саr] → (part) → [<Y> radio] может быть использована для получения документов обоих типов.
Таким образом, предполагается, что граф запроса Q отождествляется с графом описания ресурса R, если:
• Q изоморфен подграфу графа R;
• пометки графа R соответствуют пометкам графа Q;
• «голова» графа R соответствует узлу, помеченному переменной в графе Q.
Последнее условие необходимо, если мы хотим «сосредоточиться» на ресурсах, соответствующих запросу в точности.
Реализация системы OntoSeek выполнена в парадигме «клиент-сервер». Архитектурным ядром ее является сервер онтологий, обеспечивающий для приложений интерфейсы доступа и/или манипулирования данными модели онтологии, а также поддержки БД концептуальных графов. Заметим, что последняя может строиться и пополняться не только в интерактивном режиме, но и за счет скомпилированных описаний ПКГ, представленных на языке XML. Компонента БД в системе OntoSeek выделена в отдельный блок, что позволяет легко заменить при необходимости используемую СУБД.
Проект начался зимой 1996 г. - на заре эры языка Java. Поэтому прототип был реализован на языке C++. В настоящее время авторы предполагают провести реинжиниринг системы на основе использования новейших Интернет-технологий.
Таким образом, использование онтологий для интеллектуальной работы с Интернет-ресурсами является в настоящее время «горячей» точкой исследований и практических применений.
Специалистам в этой области хорошо известны Интернет-сайты организаций и проектов, связанных с созданием и использованием онтологий, но даже у них при выборе онтологии, «подходящей» для конкретного приложения, возникают определенные проблемы. Основные из них: отсутствие стандартного набора свойств, характеризующих онтологию с точки зрения ее пользователя; уникальность логической структуры представления релевантной информации на каждом «онтологическом» сайте; высокая трудоемкость поиска подходящей онтологии.
Учитывая вышесказанное, в заключение данного параграфа рассмотрим пример интеллектуального агента, который демонстрирует онтологический подход к поиску на Web и выбору для использования собственно онтологий.