

21 . Создание процессов (действия, выполняемые ос).
Создание виртуального адресного пространства процесса (ВАП)
Загрузка образа процесса в ВАП
Загрузка (части) модулей, используемых процессом, в ВАП
Добавление информации о новом процессе в таблицу (список) процессов
Создание одного потока процесса с приоритетом по умолчанию
Запуск потока процесса
Билет 22. Информация о процессах и потоках
Поля из записи табл. процессов
Управление процессов:
Регистры
Счетчик команд
Слово состояния программы
Указатель стека
Состояние процесса
Приоритет
Параметры планирования
Идентификатор процесса
Родительский процесс
Группа процесса
Сигналы
Время запуска процесса
Использованное время процессора
Время процессора, использованное дочерними процессами
Время следующего аварийного сигнала
Задача получения списка выполняющихся в системе процессов является одной из основных при выполнении мониторинга ресурсов, как отдельного ПК, так и ЛВС в целом, поэтому для ее решения разработано значительное количество утилит, имеется встроенное системное средство – диспетчер задач.
Все перечисленные программные средства используют как функции Win32 API (ApplicationProgram Interface – прикладной программный интерфейс), так и функции еще одного базового интерфейса, называемого Native API (естественный API). Внешняя часть Native API пользовательского режима содержится в модуле ntdll.dll, «настоящий» интерфейс реализован в ntoskernel.exe – ядре операционной системы NT (NT operation system kernel). Функции Win32 API, как правило, обращаются к функциям Native API, отбрасывая часть полученной от них информации. Поэтому использование функций Native API позволяет получить, вообще говоря, более эффективное ПО.
К функциям Win32 API для получения информации о выполняющихся в системе процессах относятся функции CreateToolHelp32Snapshot(), Process32First(), Process32Next(), Thread32First (), Thread32Next(), Module32First(), Module32Next(), Heap32ListFirst(), Heap32ListNext() и некоторые другие. Самая известная из функций Native API для доступа к содержимому многих важных внутренних структур операционной системы, таких как списки процессов, потоков, дескрипторов, драйверов и т. п. – функция NtQuerySystemInformation ().
1.1.1 Использование функций CreateToolHelp32Snapshot () и Process32xxxx() для получения списка имен процессов
Первый этап получения информации о выполняющихся в системе процессах - получение снимка(snapshot) системы, который содержит информацию о состоянии системы в момент выполнения снимка.
Снимок создается с помощью функции CreateToolHelp32Snapshot (dwFlags, th32ProcessID), первый аргумент определяет, какая информация будет записана в снимок - возможные значения dwFlagsприведены в таблице.
Флаг - dwFlags |
Описание |
TH32CS_SnapHEAPLIST |
В снимок включается список куч, принадлежащих указанному процессу |
TH32CS_SnapPROCESS |
В снимок включается список процессов, присутствующих в системе |
TH32CS_SnapTHREAD |
В снимок включается список потоков |
TH32CS_SnapMODULE |
В снимок включается список модулей, принадлежащих указанному процессу |
TH32CS_SnapALL |
В снимок включается список куч, процессов, потоков и модулей |
Второй аргумент определяет процесс, информация о котором необходима (если требуется список куч и модулей). В остальных случаях он игнорируется.
Второй этап - извлечение из снимка списка процессов. Для выполнения этой операции служат функции:
Process32First ( hSnapshot, LPProcessEntry32)
Process32Next ( hSnapshot, LPProcessEntry32).
Первый аргумент - хэндл созданного снимка (возвращает функция CreateToolHelp32Snapshot).
Второй аргумент- структура, содержащая 10 полей:
1. Первое поле этой структуры - dwSize - должно перед вызовом функции содержать размер структуры в байтах - sizeof (ProcessEntry32).
2. Второе поле - cntUsage - содержит число ссылок на процесс, то есть число потоков, которые в настоящий момент используют какие-либо данные процесса.
3. Третье поле - th32ProcessID - является идентификатором процесса.
4. Шестое поле - cntThreads - определяет число потоков, принадлежащих процессу.
5. Седьмое поле - th32ParentProcessID - является идентификатором родительского по отношению к текущему процесса.
6. Поле pcPriClassBase cодержит базовый приоритет процесса.
7. Поле szExeFile cодержит имя файла, создавшего процесс.
Для того, чтобы получить информацию о первом процессе в снимке, необходимо вызвать функцию Process32First. В случае успешного завершения функция возвращает TRUE. Для того, чтобы просмотреть все оставшиеся процессы, нужно вызывать функцию Process32Next до тех пор, пока она не возвратит FALSE.
В список используемых модулей - uses - необходимо добавить модуль TlHelp32
23. Состояния потока. Очередь потоков.
Три состояния:
выполнение — активное состояние потока, во время которого поток обладает всеми необходимыми ресурсами и непосредственно выполняется процессором;
ожидание — пассивное состояние потока, находясь в котором, поток заблокирован по своим внутренним причинам (ждет осуществления некоторого события, например завершения операции ввода-вывода, получения сообщения от другого потока или освобождения какого-либо необходимого ему ресурса);
готовность — также пассивное состояние потока, но в этом случае поток заблокирован в связи с внешним по отношению к нему обстоятельством (имеет все требуемые для него ресурсы, готов выполняться, однако процессор занят выполнением другого потока).

24. Планирование процессов. Цели планирования. Виды планирования.
Для всех ОС соблюдается следующие принципы планирования:
Предоставление каждому процессу справедливого (одинакового) количество процессорного времени.
Производится принудительное выполнение политики приоритетов выполняющихся процессов.
Планирование производится таким образом чтобы поддерживался максимальный баланс занятости системы. Например: в очереди на выполнение имеются 4 процесса, 2 из которых требуют значительного количество работы устройств ввода вывода и малого количество процессорного времени, а 2 других процесса требуют большого количество процессорного времени и малого времени работы устройств ввода вывода. Все процессы будут выполнятся значительно скорее если они будут запускаться попарно: процесс требующий большого количество работы устройств ввода вывода и малого количество времени процессора, а так же процесс требующий большого количество процессорного времени и малого времени работы устройств ввода вывода.
Вытесняющие и невытесняющие алгоритмы планирования
невытесняющая многозадачность - это способ планирования процессов, при котором активный процесс выполняется до тех пор, пока он сам, по собственной инициативе, не отдаст управление планировщику операционной системы для того, чтобы тот выбрал из очереди другой, готовый к выполнению процесс.
вытесняющая многозадачность - это такой способ, при котором решение о переключении процессора с выполнения одного процесса на выполнение другого процесса принимается планировщиком операционной системы, а не самой активной задачей.
25. Алгоритм планирования FIFO.
FIFO (акроним First In, First Out — «первым пришёл — первым ушёл») — способ организации и манипулирования данными относительно времени и приоритетов. Это выражение описывает принцип технической обработки очереди или обслуживания конфликтных требований путём упорядочения процесса по принципу: «первым пришёл — первым обслужен» (ПППО). Тот, кто приходит первым, тот и обслуживается первым, пришедший следующим ждёт, пока обслуживание первого не будет закончено, и так далее.
26. Алгоритм планирования «Кратчайшее задание первым».
Предполагается, что временные отрезки работы известны заранее. Если в очереди есть несколько одинаково важных задач, планировщик выбирает первой самую короткую задачу. Происходит экономия времени. Эта схема работает лишь в случае лишь одновременного наличия задач.
27. Алгоритм планирования потоков RR.
Круговое планирование (RR) (Round Robin)/
Каждому процессу предоставляется некоторый интервал времени процессора – квант времени. Таймер генерирует прерывания через определенные интервалы времени.
28. Алгоритм планирования «Многоуровневые очереди с обратными связями»
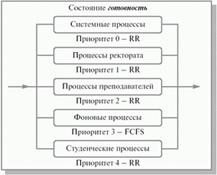
Для каждой группы процессов создается своя очередь процессов, находящихся в состоянии готовность (см. рис. 3.5). Этим очередям приписываются фиксированные приоритеты. Например, приоритет очереди системных процессов устанавливается выше, чем приоритет очередей пользовательских процессов. А приоритет очереди процессов, запущенных студентами, ниже, чем для очереди процессов, запущенных преподавателями. Это значит, что ни один пользовательский процесс не будет выбран для исполнения, пока есть хоть один готовый системный процесс, и ни один студенческий процесс не получит в свое распоряжение процессор, если есть процессы преподавателей, готовые к исполнению. Внутри этих очередей для планирования могут применяться самые разные алгоритмы.
29. Справедливое планирование потоков.
До сих пор мы предполагали, что каждый процесс фигурирует в планировании сам по себе, безотносительно своего владельца. В результате если пользователь 1 запускает 9 процессов, а пользователь 2 запускает 1 процесс, то при циклическом планировании или при равных приоритетах пользователь 1 получит 90% процессорного времени, а пользователь 2 получит только 10%.
Чтобы избежать подобной ситуации некоторые системы перед планированием работы процесса берут в расчет, кто является его владельцем. В этой модели каждому пользователю распределяется некоторая доля процессорного времени и планировщик выбирает процессы, соблюдая это распределение. Таким образом, если каждому из двух пользователей было обещано по 50% процессорного времени, то они его получат, независимо от количества имеющихся у них процессов.
В качестве примера рассмотрим систему с двумя пользователями, каждому из которых обещано 50% процессорного времени. У первого пользователя четыре процесса: Л, В, С и Д а у второго пользователя только один процесс — Е. Если используется циклическое планирование, то возможная последовательность планируемых процессов, соответствующая всем ограничениям, будет иметь следующий вид:
AEBECEDEAEBECEDE...
Но если первому пользователю предоставлено вдвое большее время, чем второму, то мы можем получить следующую последовательность:
ABECDEABECDE...
Разумеется, существует масса других возможностей, используемых в зависимости от применяемых понятий справедливости. Губадия с мясом
Б илет
31. Приоритеты процессов
илет
31. Приоритеты процессов

1 ИСТ = 10 Мсек или 15 Мсек (если ЦП имеет 2 ядра)
КВАНТ = 2 интервала системного таймера (ИСТ)
ПРИОРИТЕТ потока – целое число от 1 до 15 и от 16 до 31 (самый высокий).
Потоки с равными приоритетами получают кванты времени по циклическому алгоритму RR. Поток с меньшим приоритетом голодает
Более высокий приоритет должен давать процессу определенные преимущества перед низкоприоритетными процессами при работе планировщика.
Назначение приоритетов выполняется пользователем либо администратором системы, возможно также программное изменение приоритета процесса. На выбор оптимального уровня приоритета влияют в основном два соображения:
важность, ответственность данного процесса либо привилегированное положение запускающего процесс пользователя;
количество процессорного времени, на которое будет претендовать процесс (как мы видели в примере с фоновой печатью, высокий приоритет процесса, мало загружающего процессор, почти не приводит к замедлению работы остальных процессов).
Основной алгоритм приоритетного планирования напоминает простое круговое планирование, однако круговая очередь активных процессов формируется отдельно для каждого уровня приоритета. Пока есть хоть один активный процесс в очереди с самым высоким приоритетом, процессы с более низкими приоритетами не могут получить управление. Только когда все процессы с высшим приоритетом заблокированы либо завершены, планировщик выбирает процесс из очереди с более низким приоритетом.
Приоритет, присваиваемый процессу при создании, называется статическим приоритетом. Дисциплина планирования, использующая только статические приоритеты, имеет один существенный недостаток: низкоприоритетные процессы могут надолго оказаться полностью отлученными от процессора. Иногда это приемлемо (если высокоприоритетные процессы несравнимо важнее, чем низкоприоритетные), однако чаще хотелось бы, чтобы и на низкие приоритеты хоть что-нибудь перепадало, пусть даже реже и в меньшем количестве, чем на высокие. Для решения этой задачи предложено множество разных алгоритмов планирования процессов, основанных на идее динамического приоритета.
Динамический приоритет процесса — это величина, автоматически рассчитываемая системой на основе двух основных факторов: статического приоритета и степени предыдущего использования процессора данным процессом. Общая идея следующая: если процесс слишком долго не получал процессорного времени, то его приоритет следует повысить, чтобы дать процессу шанс на будущее. Наоборот, если процесс слишком часто и долго работал, есть смысл временно понизить его приоритет, чтобы пропустить вперед изголодавшихся конкурентов.
Могут учитываться и другие соображения, влияющие на динамический приоритет. Например, если процесс ведет диалог с пользователем, то имеет смысл повысить его приоритет, чтобы сократить время реакции и избежать досадных задержек при нажатии клавиш. Если процесс в последнее время часто блокировался, не использовав до конца выделенный ему квант времени, то это тоже основание для повышения приоритета: вполне возможно, процесс и впредь будет так же неприхотлив.
Билет 32. Базовые приоритеты процессов, управление
Голодающий поток – готовый к выполнению поток, не получивший квант времени в течение 300 ИСТ
Голодающий поток получает 2 кванта времени с приоритетом 15, далее существует в системе со своим приоритетом еще 300 ИСТ, после чего получает 2 кванта с приоритетом 15 и т. д.
Уровни приоритета назначаются с учетом двух разных точек зрения - Windows API и ядра Windows.
Windows API сначала упорядочивает процессы по классам приоритета, назначенным при их создании [Real-time (реального времени), High (высокий), Above Normal (выше обычного), Normal (обычный), Below Normal (ниже обычного) и Idle (простаивающий)], а затем — по относительному приоритету индивидуальных потоков в рамках этих процессов [Time-critical (критичный по времени), Highest (наивысший), Above-normal (выше обычного), Normal (обычный), Below-normal (ниже обычного), Lowest (наименьший) и Idle (простаивающий)].
Базовый приоритет каждого потока в Windows API устанавливается, исходя из класса приоритета его процесса и относительного приоритета самого потока. Если у процесса только одно значение приоритета (базовое), то у каждого потока их два: текущее и базовое. Решения, связанные с планированием, принимаются на основе текущего приоритета. В определенных обстоятельствах система может на короткое время повышать приоритеты потоков в динамическом диапазоне (1-15). Windows никогда не изменяет приоритеты потоков в диапазоне реального времени (16-31), поэтому у таких потоков базовый приоритет идентичен текущему.
Обычно базовый приоритет процесса (а значит, и базовый приоритет первичного потока) по умолчанию равен значению из середины диапазонов приоритетов процессов (24, 13, 10, 8, 6 или 4). Однако базовый приоритет некоторых системных процессов (например, диспетчера сеансов, контроллера сервисов и сервера локальной аутентификации) несколько превышает значение по умолчанию для класса Normal (8). Более высокий базовый приоритет по умолчанию обеспечивает запуск потоков этих процессов с приоритетом выше 8.
Динамические приоритеты позволяют повысить реактивность системы, т.к. реагируют на изменения ситуации, и начальное значение приоритета процесса может быть изменено на новое, более подходящее значение.
Динамическое повышение приоритета
Windows может динамически повышать значение текущего приоритета потока в одном из пяти случаев:
• после завершения операций ввода-вывода;
• по окончании ожидания на событии или семафоре исполнительной системы;
• по окончании операции ожидания потоками активного процесса;
• при пробуждении GUI-потоков из-за операций с окнами;
• если поток, готовый к выполнению, задерживается из-за нехватки процессорного времени.
Динамическое повышение приоритета предназначено для оптимизации общей пропускной способности и отзывчивости системы, а также для устранения потенциально «нечестных» сценариев планирования. Однако, как и любой другой алгоритм планирования, динамическое повышение приоритета — не панацея, и от него выигрывают не все приложения.
ПРИМЕЧАНИSWindows никогда не увеличивает приоритет потоков в диапазоне реального времени (16–31). Поэтому планирование таких потоков по отношению к другим всегда предсказуемо. Windows считает: тот, кто использует приоритеты реального времени, знает, что делает.
Динамическое повышение приоритета после завершения ввода-вывода
Windows временно повышает приоритет потоков по окончании определенных операций ввода-вывода, поэтому у потоков, ожидавших завершения таких операций, больше шансов немедленно возобновить выполнение и обработать полученные данные. Вспомните: после пробуждения потока оставшийся у него квант уменьшается на одну единицу, так что потоки, ожидавшие завершения ввода-вывода, не получают неоправданных преимуществ. Хотя рекомендованные приращения в результате динамического повышения приоритета определены в заголовочных файлах DDK (ищите строки «#define IO» в Wdm.h или Ntddk.h; эти же значения перечислены в таблице 6-17), реальное приращение определяется драйвером устройства. Именно драйвер устройства указывает — через функцию ядраIoCompleteRequest — на необходимость динамического повышения приоритета после выполнения запроса на ввод-вывод. Заметьте, что для запросов на ввод-вывод, адресованных устройствам, которые гарантируют меньшее время отклика, предусматриваются большие приращения приоритета.

Приоритет потока всегда повышается относительно базового, а не текущего уровня. Как показано на рис. 6-22, после динамического повышения приоритета поток в течение одного кванта выполняется с повышенным уровнем приоритета, после чего приоритет снижается на один уровень и потоку выделяется еще один квант. Этот цикл продолжается до тех пор, пока приоритет не снизится до базового. Поток с более высоким приоритетом все равно может вытеснить поток с повышенным приоритетом, но прерванный поток должен полностью отработать свой квант с повышенным приоритетом до того, как этот приоритет начнет понижаться.

Как уже отмечалось, динамическое повышение приоритета применяется только к потокам с приоритетом динамического диапазона (0-15). Независимо от приращения приоритет потока никогда не будет больше 15. Иначе говоря, если к потоку с приоритетом 14 применить динамическое повышение на 5 уровней, его приоритет возрастет лишь до 15. Если приоритет потока равен 15, он остается неизменным при любой попытке его повышения.
Динамическое повышение приоритета по окончании ожидания событий и семафоров
Когда ожидание потока на событии исполнительной системы или объекте «семафор» успешно завершается (из-за вызова SetEvent, PulseEvent или ReleaseSemaphore), его приоритет повышается на 1 уровень (см. значения EVENT_INCREMENT и SEMAPHORE_INCREMENT в заголовочных файлах DDK). Причина повышения приоритета потоков, закончивших ожидание событий или семафоров, та же, что и для потоков, ожидавших окончания операций ввода-вывода: потокам, блокируемым на событиях, процессорное время требуется реже, чем остальным. Такая регулировка позволяет равномернее распределять процессорное время.
B данном случае действуют те же правила динамического повышения приоритета, что и при завершении операций ввода-вывода (см. предыдущий раздел).
K потокам, которые пробуждаются в результате установки события вызовом специальных функцийNtSetEventBoostPriority (используется в Ntdll.dll для критических секций) и KeSetEventBoostPriority(используется для ресурсов исполнительной системы и блокировок с заталкиванием указателя) повышение приоритета применяется особым образом. Если поток с приоритетом 13 или ниже, ждущий на событии, пробуждается в результате вызова специальной функции, его приоритет повышается до приоритета потока, установившего событие, плюс 1. Если длительность его кванта меньше 4 единиц, она приравнивается 4 единицам. Исходный приоритет восстанавливается по истечении этого кванта.
Динамическое повышение приоритета потоков активного процесса после выхода из состояния ожидания
Всякий раз, когда поток в активном процессе завершает ожидание на объекте ядра, функция ядраKiUnwaitThread динамически повышает его текущий (не базовый) приоритет на величину текущего значения PsPrioritySeparation. (Какой процесс является активным, определяет подсистема управления окнами.) Как было сказано в разделе «Управление величиной кванта» ранее в этой главе,PsPrioritySeparation представляет собой индекс в таблице квантов (байтовом массиве), с помощью которой выбираются величины квантов для потоков активных процессов. Однако в данном случаеPsPrioritySeparation используется как значение, на которое повышается приоритет.
Это увеличивает отзывчивость интерактивного приложения по окончании ожидания. B результате повышаются шансы на немедленное возобновление его потока — особенно если в фоновом режиме выполняется несколько процессов с тем же базовым приоритетом.
B отличие от других видов динамического повышения приоритета этот поддерживается всеми системами Windows, и его нельзя отключить даже через Windows-функцию SetThreadPriorityBoost.
Динамическое повышение приоритета после пробуждения GUI-потоков
Приоритет потоков, владеющих окнами, дополнительно повышается на 2 уровня после их пробуждения из-за активности подсистемы управления окнами, например при получении оконных сообщений. Подсистема управления окнами (Win32k.sys) повышает приоритет, вызывая KeSetEvent для установки события, пробуждающего GUI-поток. Приоритет повышается по той же причине, что и в предыдущем случае, — для создания преимуществ интерактивным приложениям.
Билет 33. Цели и средства синхронизации. Классификация потоков по способу взаимодействия. Необходимость синхронизации. Примеры выполнения параллельных конкурирующих потоков, работающих с общей переменной и с наборами разделяемых данных.
Потребность в синхронизации потоков возникает только в мультипрограммной ОС и связана с совместным использованием несколькими процессами аппаратных и информационных ресурсов ВС. Выполнение потока в мультипрограммной среде всегда имеет асинхронный характер. Очень сложно с полной определенностью сказать, на каком этапе будет находиться процесс в определенный момент времени. Т.к. исходные данные в разные моменты запуска задачи могут быть разными, то и время выполнения отдельных этапов и задачи в целом является весьма неопределенной величиной. Также неопределенным является время выполнения программы в мультипрограммной системе. Потоки в общем случае (когда программист не предпринял специальных мер по синхронизации) протекают независимо, асинхронно друг другу. Любое взаимодействие процессов (потоков), связанное с разделением ресурсов или обменом данными, требует их синхронизации. Синхронизация заключается в согласовании скоростей процессов (потоков) путем приостановки одного или нескольких из них до наступления некоторого события и последующей активации при наступлении этого события. (Задача «поставщик-потребитель»). При совместном использовании аппаратных средств синхронизация совершенно необходима. Часто нужна синхронизация с событиями, внешними по отношению к ВС, например, реакции на нажатие комбинации клавиш Ctrl+C.
Средства. Для синхронизации потоков прикладных программ программист может использовать как собственные средства и приемы синхронизации, так и средства ОС. Например, два потока одного прикладного процесса могут координировать свою работу с помощью доступной для них обоих глобальной логической переменной, которая устанавливается в единицу при осуществлении некоторого события, например, выработки одним потоком данных, нужных для продолжения работы другого. Но во многих случаях эффективными и даже единственно возможными являются средства синхронизации, предоставляемые ОС в форме системных вызовов. Так, потоки, принадлежащие разным процессам, не имеют возможности вмешиваться каким-либо образом в работу друг друга. Без посредничества ОС они не могут приостановить друг друга или оповестить о произошедшем событии. Средства синхронизации используются ОС не только для синхронизации прикладных процессов, но и для ее внутренних нужд. Обычно разработчики ОС предоставляют в распоряжение прикладных и системных программистов широкий спектр средств синхронизации. Эти средства могут образовывать иерархию, когда на основе более простых средствах строятся более сложные, кроме того, подобные средства могут быть функционально специализированными, например, средства для синхронизации потоков одного процесса, средства для синхронизации потоков разных процессов для обмена данными и т.д. Часто функциональные возможности разных системных вызовов синхронизации перекрываются, так что для решения одной задачи программист может воспользоваться несколькими вызовами в зависимости от своих личных предпочтений.
Типы потоков по способу взаимодействия
Параллельные (не взаимодействуют, не модифицируют общих ресурсов)
Конкурирующие за получение доступа к общему ресурсу
Сотрудничающие – совместно решающие общую задачу (например, поставщик - потребитель)
Необходимость синхронизации. Итак, в Windows выполняются не процессы, а потоки. При создании процесса автоматически создается его основной поток. Этот поток в процессе выполнения может создавать новые потоки, которые, в свою очередь, тоже могут создавать потоки и т.д. Процессорное время распределяется именно между потоками, и получается, что каждый поток работает независимо.Все потоки, принадлежащие одному процессу, разделяют некоторые общие ресурсы - такие, как адресное пространство оперативной памяти или открытые файлы. Эти ресурсы принадлежат всему процессу, а значит, и каждому его потоку. Следовательно, каждый поток может работать с этими ресурсами безы каких-либо ограничений. Но так ли это в действительности? Вспомним, что в Windows реализована вытесняющая многозадачность - это значит, что в любой момент система может прервать выполнение одного потока и передать управление другому. (Раньше использовался способ организации, называемый кооперативной многозадачностью. Система ждала, пока поток сам не соизволит передать ей управление. Именно поэтому в случае глухого зависания одного приложения приходилось перезагружать компьютер. Так была организована, например, Windows 3.1). Что произойдет, если один поток еще не закончил работать с каким-либо общим ресурсом, а система переключилась на другой поток, использующий тот же ресурс? Произойдет штука очень неприятная, я вам это могу с уверенностью сказать, и результат работы этих потоков может чрезвычайно сильно отличаться от задуманного. Такие конфликты могут возникнуть и между потоками, принадлежащими различным процессам. Всегда, когда два или более потоков используют какой-либо общий ресурс, возникает эта проблема. Именно поэтому необходим механизм, позволяющий потокам согласовывать свою работу с общими ресурсами. Этот механизм получил название механизма синхронизации потоков (thread synchronization).
Пренебрежение вопросами синхронизации в многопоточной системе может привести к неправильному решению задачи или даже к краху системы. Рассмотрим, например (рис. 6.1.1), задачу ведения базы данных клиентов некоторого предприятия. Каждому клиенту отводится отдельная запись в базе данных, в которой среди прочих полей имеются поля Заказ и Оплата. Программа, ведущая базу данных, оформлена как единый процесс, имеющий несколько потоков, в том числе поток А, который заносит в базу данных информацию о заказах, поступивших от клиентов, и поток В, который фиксирует в базе данных сведения об оплате клиентами выставленных счетов. Оба эти потока совместно работают над общим файлом базы данных, используя однотипные алгоритмы, включающие три шага.
1. Считать из файла базы данных в буфер запись о клиенте с заданным идентификатором.
2. Внести новое значение в поле Заказ (для потока А) или Оплата (для потока В).
3. Вернуть модифицированную запись в файл базы данных.

Рис. 6.1.1. Возникновение гонок при доступе к разделяемым данным
Обозначим соответствующие шаги для потока А как Al, A2 и A3, а для потока В как Bl, B2 и ВЗ. Предположим, что в некоторый момент поток А обновляет поле Заказ записи о клиенте N. Для этого он считывает эту запись в свой буфер (шаг А1), модифицирует значение поля Заказ (шаг А2), но внести запись в базу данных (шаг A3) не успевает, так как его выполнение прерывается, например, вследствие завершения кванта времени.
Предположим также, что потоку В также потребовалось внести сведения об оплате относительно того же клиента N. Когда подходит очередь потока В, он успевает считать запись в свой буфер (шаг В1) и выполнить обновление поля Оплата (шаг В2), а затем прерывается. Заметим, что в буфере у потока В находится запись о клиенте N, в которой поле Заказ имеет прежнее, не измененное значение.
Когда в очередной раз управление будет передано потоку А, то он, продолжая свою работу, запишет запись о клиенте N с модифицированным полем Заказ в базу данных (шаг A3). После прерывания потока А и активизации потока В последний запишет в базу данных поверх только что обновленной записи о клиенте N свой вариант записи, в которой обновлено значение поля Оплата. Таким образом, в базе данных будут зафиксированы сведения о том, что клиент N произвел оплату, но информация о его заказе окажется потерянной (рис. 6.1.2, а).
Сложность проблемы синхронизации кроется в нерегулярности возникающих ситуаций. Так, в предыдущем примере можно представить и другое развитие событий: могла быть потеряна информация не о заказе, а об оплате (рис. 6.1.2, б) или, напротив, все исправления были успешно внесены (рис. 6.1.2, в). Все определяется взаимными скоростями потоков и моментами их прерывания. Поэтому отладка взаимодействующих потоков является сложной задачей. Ситуации, подобные той, когда два или более потоков обрабатывают разделяемые данные и конечный результат зависит от соотношения скоростей потоков, называются гонками.

Рис. 6.1.2. Влияние относительных скоростей потоков на результат решения задачи
Билет 34. Критический участок и критическая секция. Реализация критических секций с использованием блокирующих переменных и ее недостатки.
Возникновение гонок при доступе к разделяемым данным

Важным понятием синхронизации потоков является понятие «критической секции» программы. Критическая секция — это часть программы, результат выполнения которой может непредсказуемо меняться, если переменные, относящиеся к этой части программы, изменяются другими потоками в то время, когда выполнение этой части еще не завершено. Критическая секция всегда определяется по отношению к определенным критическим данным, при несогласованном изменении которых могут возникнуть нежелательные эффекты. В предыдущем примере такими критическими данными являлись записи файла базы данных. Во всех потоках, работающих с критическими данными, должна быть определена критическая секция. Заметим, что в разных потоках критическая секция состоит в общем случае из разных последовательностей команд.
Самый простой и в то же время самый неэффективный способ обеспечения взаимного исключения состоит в том, что операционная система позволяет потоку запрещать любые прерывания на время его нахождения в критической секции. Однако этот способ практически не применяется, так как опасно доверять управление системой пользовательскому потоку — он может надолго занять процессор, а при крахе потока в критической секции крах потерпит вся система, потому что прерывания никогда не будут разрешены.
Для синхронизации потоков одного процесса прикладной программист может использовать глобальные блокирующие переменные. С этими переменными, к которым все потоки процесса имеют прямой доступ, программист работает, не обращаясь к системным вызовам ОС.

Рис. 6.1.3. Реализация критических секций с использованием блокирующих переменных
Реализация взаимного исключения описанным выше способом имеет существенный недостаток: в течение времени, когда один поток находится в критической секции, другой поток, которому требуется тот же ресурс, получив доступ к процессору, будет непрерывно опрашивать блокирующую переменную, бесполезно тратя выделяемое ему процессорное время, которое могло бы быть использовано для выполнения какого-нибудь другого потока. Для устранения этого недостатка во многих ОС предусматриваются специальные системные вызовы для работы с критическими секциями.
Билет 35. Реализация взаимного исключения с использованием системных функций входа в критическую секцию и выхода из нее.
На рис. 6.1.4 показано, как с помощью этих функций реализовано взаимное исключение в операционных системах семейства Windows NT. Перед тем как начать изменение критических данных, поток выполняет системный вызов EnterCriticalSection(). В рамках этого вызова сначала выполняется, как и в предыдущем случае, проверка блокирующей переменной, отражающей состояние критического ресурса. Если системный вызов определил, что ресурс занят (F(D) - 0), он в отличие от предыдущего случая не выполняет циклический опрос, а переводит поток в состояние ожидания D) и делает отметку о том, что данный поток должен быть активизирован, когда соответствующий ресурс освободится. Поток, который в это время использует данный ресурс, после выхода из критической секции должен выполнить системную функцию LeaveCriticalSection(), в результате чего блокирующая переменная принимает значение, соответствующее свободному состоянию ресурса (F(D) - 1), а операционная система просматривает очередь ожидающих этот ресурс потоков и переводит первый поток из очереди в состояние готовности.

Рис. 6.1.4. Реализация взаимного исключения с использованием системных функций входа в критическую секцию и выхода из нее
Таким образом, исключается непроизводительная потеря процессорного времени на циклическую проверку освобождения занятого ресурса. Однако в тех случаях, когда объем работы в критической секции небольшой и существует высокая вероятность в очень скором доступе к разделяемому ресурсу, более предпочтительным может оказаться использование блокирующих переменных. Действительно, в такой ситуации накладные расходы ОС по реализации функции входа в критическую секцию и выхода из нее могут превысить полученную экономию.
Билет 36. Семафорные примитивы Дейкстра. Назначение. Примеры использования.
Обобщением блокирующих переменных являются так называемые семафоры Дийкстры. Вместо двоичных переменных Дийкстра (Dijkstra) предложил использовать переменные, которые могут принимать целые неотрицательные значения. Такие переменные, используемые для синхронизации вычислительных процессов, получили название семафоров.
Для работы с семафорами вводятся два примитива, традиционно обозначаемых Р и V. Пусть переменная S представляет собой семафор. Тогда действия V(S) и P(S) определяются следующим образом.
V(S): переменная S увеличивается на 1 единым действием. Выборка, наращивание и запоминание не могут быть прерваны. К переменной S нет доступа другим потокам во время выполнения этой операции.
PCS): уменьшение S на 1, если это возможно. Если S=0 и невозможно уменьшить S, оставаясь в области целых неотрицательных значений, то в этом случае поток, вызывающий операцию Р, ждет, пока это уменьшение станет возможным. Успешная проверка и уменьшение также являются неделимой операцией.
Никакие прерывания во время выполнения примитивов V и Р недопустимы.
В частном случае, когда семафор S может принимать только значения 0 и 1, он превращается в блокирующую переменную, которую по этой причине часто называют двоичным семафором. Операция Р заключает в себе потенциальную возможность перехода потока, который ее выполняет, в состояние ожидания, в то время как операция V может при некоторых обстоятельствах активизировать другой поток, приостановленный операцией Р.
Рассмотрим использование семафоров на классическом примере взаимодействия двух выполняющихся в режиме мультипрограммирования потоков, один из которых пишет данные в буферный пул, а другой считывает их из буферного пула. Пусть буферный пул состоит из N буферов, каждый из которых может содержать одну запись. В общем случае поток-писатель и поток-читатель могут иметь различные скорости и обращаться к буферному пулу с переменой интенсивностью. В один период скорость записи может превышать скорость чтения, в другой — наоборот. Для правильной совместной работы поток-писатель должен приостанавливаться, когда все буферы оказываются занятыми, и активизироваться при освобождении хотя бы одного буфера. Напротив, поток-читатель должен приостанавливаться, когда все буферы пусты, и активизироваться при появлении хотя бы одной записи.
Введем два семафора: е — число пустых буферов, и f — число заполненных буферов, причем в исходном состоянии е =N, a f =0. Тогда работа потоков с общим буферным пулом может быть описана следующим образом (рис. 6.1.5).
Поток-писатель прежде всего выполняет операцию Р(е), с помощью которой он проверяет, имеются ли в буферном пуле незаполненные буферы. В соответствии с семантикой операции Р, если семафор е равен 0 (то есть свободных буферов в данный момент нет), то поток-писатель переходит в состояние ожидания. Если же значением е является положительное число, то он уменьшает число свободных буферов, записывает данные в очередной свободный буфер и после этого наращивает число занятых буферов операцией V(f). Поток-читатель действует аналогичным образом, с той разницей, что он начинает работу с проверки наличия заполненных буферов, а после чтения данных наращивает количество свободных буферов.

Рис. 6.1.5. Использование семафоров для синхронизации потоков
В данном случае предпочтительнее использовать семафоры вместо блокирующих переменных. Действительно, критическим ресурсом здесь является буферный пул, который может быть представлен как набор идентичных ресурсов — отдельных буферов, а значит, с буферным пулом могут работать сразу несколько потоков, и именно столько, сколько буферов в нем содержится. Использование двоичной переменной не позволяет организовать доступ к критическому ресурсу более чем одному потоку. Семафор же решает задачу синхронизации более гибко, допуская к разделяемому пулу ресурсов заданное количество потоков. Так, в нашем примере с буферным пулом могут работать максимум N потоков, часть из которых может быть «писателями», а часть — «читателями».
Таким образом, семафоры позволяют эффективно решать задачу синхронизации Доступа к ресурсным пулам, таким, например, как набор идентичных в функциональном назначении внешних устройств (модемов, принтеров, портов), или набор областей памяти одинаковой величины, или информационных структур. Во всех этих и подобных им случаях с помощью семафоров можно организовать доступ к разделяемым ресурсам сразу нескольких потоков.
Билет 37. Задача поставщик-потребитель и ее решение.
Синхронизация сотрудничающих потоков (поставщик – потребитель)

Взаимодействуют два процесса – Поставщик и Потребитель. Поставщик созда¨т сообщения и записывает их в пул буферов (для каждого сообщения свой буфер). Потребитель считывает сообщения из пула буферов для дальнейшего анализа и обработки. Параллельные действия по записи в пул и чтению из него запрещены. Пул буферов имеет конечную размерность. Поэтому, оба процесса должны корректно изменять число свободных и занятых буферов в пуле, как при записи очередного сообщения, так и при его считывании из пула. Решение данной задачи, основанное на использовании семафорных примитивов, представлено ниже:
Const N=100;
Var S, SS, SN: semaphore;
Begin
S:=1; SS:=0; SN:=N;
Parbegin
Поставщик: while true do begin
… { генерация собщения}
P(SN); P(S);
… {запись сообщения}
V(SS); V(S);
End;
And
Потребитель: while true do begin
P(SS); P(S);
…{ чтение сообщения}
V(SN); V(S);
… {обработка сообщения}
End;
Parend
End.
Здесь N – число буферов в пуле, S – двоичный семафор, используемый для регулирования доступа к пулу буферов как при записи так и при считывании, SS и SN – числовые семафоры, используемые как сч¨тчики числа занятых и свободных буферов в пуле соответственно.
Для того чтобы понять представленное решение рассмотрим несколько возможных ситуаций развития взаимодействующих процессов.
Пусть пул буферов частично занят (числовые поля SS и SN имеют целые положительные значения), и управление получает Поставщик. Он создаст новое сообщение, последовательно выполнит P(SN) и P(S), и начнёт запись. Если в этот момент управление получит Потребитель, то он выполнит P(SS), затем P(S), и здесь заблокируется по семафору S. Потребитель сможет деблокироваться только после того, как Поставщик закончит запись и выполнит операцию V(S). Другими словами, пока очередная запись в пул не закончена чтение из пула невозможно, и наоборот.
Пусть пул буферов пуст, а управление получил Потребитель. Он выполнит операцию P(SS) и тут же заблокируется по семафору SS (числовое поле семафора SS к этому моменту равнялось нулю). Другими словами, чтение из пула запрещено, если он не содержит сообщений.
Пусть пул буферов полностью заполнен сообщениями, а управление получил Поставщик. Он выполнит операцию P(SN) и заблокируется по семафору SN (значение числового поля семафора SN к этому моменту будет равняться нулю). Другими словами, запись в пул запрещается, если он полностью заполнен сообщениями.
Билет 38. Задача обедающих философов.
Пять безмолвных философов сидят вокруг круглого стола, перед каждым философом стоит тарелка спагетти. Вилки лежат на столе между каждой парой ближайших философов.
Каждый философ может либо есть, либо размышлять. Приём пищи не ограничен количеством оставшихся спагетти — подразумевается бесконечный запас. Тем не менее, философ может есть только тогда, когда держит две вилки — взятую справа и слева (альтернативная формулировка проблемы подразумевает миски с рисом и палочки для еды вместо тарелок со спагетти и вилок).
Каждый философ может взять ближайшую вилку (если она доступна), или положить — если он уже держит её. Взятие каждой вилки и возвращение её на стол являются раздельными действиями, которые должны выполняться одно за другим.
Суть проблемы заключается в том, чтобы разработать модель поведения (параллельный алгоритм), при котором ни один из философов не будет голодать, то есть будет вечно чередовать приём пищи и размышления.
Официант
Относительно простое решение задачи достигается путём добавления официанта возле стола. Философы должны дожидаться разрешения официанта перед тем, как взять вилку. Поскольку официант знает, сколько вилок используется в данный момент, он может принимать решения относительно распределения вилок и тем самым предотвратить взаимную блокировку философов. Если четыре вилки из пяти уже используются, то следующий философ, запросивший вилку, вынужден будет ждать разрешения официанта — которое не будет получено, пока вилка не будет освобождена. Предполагается, что философ всегда пытается сначала взять левую вилку, а потом — правую (или наоборот), что упрощает логику. Официант работает, как семафор — понятие, введённое Дейкстрой в 1965 году.[
Чтобы показать, как это решение работает, предположим, что философы обозначены от А до Д по часовой стрелке. Если философы А и В едят, то заняты четыре вилки. Философ Б сидит между А и В, так что ему недоступна ни одна из вилок. В то же время, философы Г и Д имеют доступ к одной неиспользуемой вилке между ними. Предположим, что философ Г хочет есть. Если он тут же берёт свободную вилку, то становится возможна взаимная блокировка философов. Если вместо этого он спрашивает разрешения у официанта, то тот просит его подождать — и можно быть уверенным в том, что как только пара вилок освободится, то по крайней мере один философ сможет взять две вилки. Таким образом, взаимная блокировка становится невозможной.
Иерархия ресурсов
Другое простое решение достигается путём присвоения частичного порядка ресурсам (в данном случае вилкам) и установления соглашения, что ресурсы запрашиваются в указанном порядке, а возвращаются в обратном порядке. Кроме того, не должно быть двух ресурсов, не связанных порядком, используемых одной рабочей единицей.
Пусть ресурсы (вилки) будут пронумерованы от 1 до 5, и каждая рабочая единица (философ) всегда берёт сначала вилку с наименьшим номером, а потом вилку с наибольшим номером из двух доступных. Далее, философ кладёт сначала вилку с бо́льшим номером, потом — с меньшим. В этом случае, если четыре из пяти философов одновременно возьмут вилку с наименьшим номером, на столе останется вилка с наибольшим возможным номером. Таким образом, пятый философ не сможет взять ни одной вилки. Более того, только один философ будет иметь доступ к вилке с наибольшим номером, так что он сможет есть двумя вилками. Когда он закончит использовать вилки, он в первую очередь положит на стол вилку с бо́льшим номером, потом — с меньшим, тем самым позволив другому философу взять недостающую вилку и приступить к еде.
Данное решение было предложено Дейкстрой.
В то время, как иерархия ресурсов позволяет избежать взаимных блокировок, данное решение не всегда является практичным, в особенности когда список необходимых ресурсов неизвестен заранее. Например, если рабочая единица удерживает ресурс 3 и 5 и решает, что ей необходим ресурс 2, то она должна выпустить ресурс 5, затем 3, после этого завладеть ресурсом 2 и снова взять ресурс 3 и 5. Компьютерные программы, которые работают с большим количеством записей в базе данных, не смогут работать эффективно, если им потребуется выпускать все записи с верхними индексами прежде, чем завладеть новой записью. Это делает данный метод непрактичным.
Решение на основе монитора
|
|
|
Пример ниже показывает решение, где вилки не представляются явно. Философы могут есть, если ни один из их соседей не ест. Аналогично системе, где философы, которые не могут взять вторую вилку, должны положить первую вилку до того, как они попробуют снова.
В отсутствии блокировок, связанных с вилками, философы должны обеспечивать то, что начало принятия пищи не основывается на старой информации о состоянии соседей. Например: Если философ B видит, что A не ест в данный момент времени, а потом поворачивается и смотрит на C, A мог начать есть, пока философ B смотрит на C. Используя одну взаимоисключающую блокировку, можно избежать этой проблемы. Эта блокировка не связана с вилками, но она связана с решением процедур, которые могут изменить состояние философов. Это обеспечивается монитором.
Алгоритм монитора реализует схему «проверить, взять и положить» и разделяет взаимоисключающую блокировку. Заметьте, что философы, желающие есть, не будут иметь вилок.
Если монитор разрешает философу, желающему есть, действовать, то философ снова завладевает первой вилкой, прежде чем взять уже свободную вторую.
По окончании текущего приёма пищи философ оповещает монитора о том, что обе вилки свободны.
Стоит заметить, что этот алгоритм монитора не решает проблемы голодания. Например, философ B может бесконечно ждать своей очереди, если у философов A и C периоды приёма пищи всё время пересекаются. Чтобы гарантировать также, что ни один философ не будет голодать, можно отслеживать, сколько раз голодный философ не ел, когда его соседи положили вилки на стол. Если количество раз превысит некий предел, такой философ перейдёт в состояние Голодания и алгоритм монитора форсирует процедуру завладения вилками, выполняя условие недопущения голодания ни одного из соседей.
Философ, не имеющий возможности взять вилки из-за того, что его сосед голодает, находится в режиме полезного ожидания окончания приёма пищи соседом его соседа. Эта дополнительная зависимость снижает параллелизм. Увеличение значения порога перехода в состояние Голодание уменьшает этот эффект.
Билет 39. Взаимные блокировки, клинчи или тупики. Причины возникновения, проявление, последствия. Пример тупика двух потоков. Средства распознавания тупиков.
Тупиком называется такое состояние вычислительной системы, при котором 2 или более потоков находятся в заблокированном состоянии и при этом каждый поток ожидает освобождения ресурса, занятого другим потоком. Пусть двум потокам, принадлежащим разным процессам и выполняющимся в режиме мультипрограммирования, для выполнения их работы нужно два ресурса, например принтер и последовательный порт. Такая ситуация может возникнуть, например, во время работы приложения, задачей которого является распечатка информации, поступающей по модемной связи.
На рис. 4.22, а показаны фрагменты соответствующих программ. Поток А запрашивает сначала принтер; а затем порт, а поток В запрашивает устройства в обратном порядке. Предположим, что после того, как ОС назначила принтер потоку А и установила связанную с этим ресурсом блокирующую переменную, поток А был прерван. Управление получил поток В, который сначала выполнил запрос на получение СОМ- порта, затем при выполнении следующей команды был заблокирован, так как принтер оказался уже занятым потоком А. Управление снова получил поток А, который в соответствии со своей программой сделал попытку занять порт и был заблокирован, поскольку порт уже выделен потоку В. В таком положении потоки А и В могут находиться сколь угодно долго.
В зависимости от Соотношения скоростей потоков они могут либо взаимно блокировать друг друга (рис. 4.22, б), либо образовывать очереди к разделяемым ресурсам (рис. 4.22, в), либо совершенно независимо использовать разделяемые ресурсы (рис. 4.22, г).

Рис. 4.22. Возникновение взаимных блокировок при выполнении программы
ПРИМЕЧАНИЕ
Тупиковые ситуации надо отличать от простых очередей* хотя те и другие возникают при совместном использовании ресурсов и внешне выглядят похоже: поте* приостанавливается и ждет освобождения ресурса. Однако очередь — это нормальное явление, неотъемлемый признак высокого коэффициента использования ресурсов при случайном поступлении запросов. Очередь появляется тогда, когда ресурс недоступен в данный момент, но освободится через некоторое время, позволив потоку продолжить выполнение. Тупик же, что видно из его названия, является в некотором роде неразрешимой ситуацией. Необходимым условием возникновения тупика является потребность потока сразу в нескольких ресурсах. Невозможность потоков завершить начатую работу из-за возникновения взаимных блокировок снижает производительность вычислительной системы. Поэтому проблеме предотвращения тупиков уделяется большое внимание. На тот случай, когда взаимная блокировка все же возникает, система должна предоставить администратору-оператору средства, с помощью которых он смог бы распознать тупик, отличить его от обычной блокировки из-за временной недоступности ресурсов. И наконец, если тупик диагностирован, то нужны средства для снятия взаимных блокировок и восстановления нормального вычислительного процесса.

Рис. 4.23. Взаимная блокировка нескольких потоков
Тупики могут быть предотвращены на стадии написания программ, то есть программы должны быть написаны таким образом, чтобы тупик не мог возникнуть при любом соотношении взаимных скоростей потоков. Так, если бы в примере, показанном на рис. 4.22, поток А и поток В запрашивали ресурсы в одинаковой последовательности, то тупик был бы>в принципе невозможен. Другой, более гибкий подход к предотвращению тупиков заключается в том, что ОС каждый раз при запуске задач анализирует их потребности в ресурсах и определяет, может ли в данной мультипрограммной смеси возникнуть тупик. Если да, то запуск новой задачи временно откладывается. ОС может также использовать определенные правила при назначении ресурсов потокам, например, ресурсы могут выделяться операционной системой в определенной последовательности, общей для всех потоков.
В тех же случаях, когда тупиковую ситуацию не удалось предотвратить, важно быстро и точно ее распознать, поскольку блокированные потоки не выполняют никакой полезной работы. Если тупиковая ситуация образована множеством потоков, занимающих массу ресурсов, распознавание тупика является нетривиальной задачей. Существуют формальные, программнореализованные методы распознавания тупиков, основанные на ведении таблиц распределения ресурсов и таблиц запросов к занятым ресурсам. Анализ этих таблиц позволяет обнаружить взаимные блокировки.
Если же тупиковая ситуация возникла, то не обязательно снимать с выполнения все заблокированные потоки/Можно снять только часть из них, освободив ресурсы, ожидаемые остальными потоками, можно вернуть некоторые потоки в область подкачки, можно совершить -«откат» некоторых потоков до так называемой контрольной точки, в которой запоминается вся информация, необходимая для восстановления выполнения программы с данного места. Контрольные точки расставляются в программе в тех местах, после которых возможно возникновение тупика.
Билет 40. Функции ОС по управлению памятью. Классификация методов распределения памяти. Распределение памяти фиксированными разделами и динамическими разделами. Перемещаемые разделы.
Под памятью (memory) здесь подразумевается оперативная память компьютера. В отличие от памяти жесткого диска, которую называют внешней памятью (storage), оперативной памяти для сохранения информации требуется постоянное электропитание. Функциями ОС по управлению памятью в мультипрограммной системе являются:
отслеживание свободной и занятой памяти;
выделение памяти процессам и освобождение памяти по завершении процессов;
вытеснение кодов и данных процессов из оперативной памяти на диск (полное или частичное), когда размеры основной памяти не достаточны для размещения в ней всех процессов, и возвращение их в оперативную память, когда в ней освобождается место;
настройка адресов программы на конкретную область физической памяти.

Распределение памяти фиксированными разделами
Простейший способ управления оперативной памятью состоит в том, что память разбивается на несколько областей фиксированной величины, называемых разделами. Такое разбиение может быть выполнено вручную оператором во время старта системы или во время ее установки. После этого границы разделов не изменяются.
Очередной новый процесс, поступивший на выполнение, помещается либо в общую очередь (рис. 5.8, а), либо в очередь к некоторому разделу (рис. 5.8, 6).

Рис. 5.8. Распределение памяти фиксированными разделами: с общей очередью (а), с отдельными очередями (б)
Подсистема управления памятью в этом случае выполняет следующие задачи:
Сравнивает объем памяти, требуемый для вновь поступившего процесса, с размерами свободных разделов и выбирает подходящий раздел;
Осуществляет загрузку программы в один из разделов и настройку адресов. Уже на этапе трансляции разработчик программы может задать раздел, в котором ее следует выполнять. Это позволяет сразу, без использования перемещающего загрузчика, получить машинный код, настроенный на конкретную область памяти.
При очевидном преимуществе — простоте реализации, данный метод имеет существенный недостаток — жесткость. Так как в каждом разделе может выполняться только один процесс, то уровень мультипрограммирования заранее ограничен числом разделов. Независимо от размера программы она будет занимать весь раздел. Такой способ управления памятью применялся в ранних мультипрограммных ОС. Однако и сейчас метод распределения памяти фиксированными разделами находит применение в системах реального времени, в основном благодаря небольшим затратам на реализацию. Детерминированность вычислительного процесса систем реального времени (заранее известен набор выполняемых задач, их требования к памяти, а иногда и моменты запуска) компенсирует недостаточную гибкость данного способа управления памятью.
Распределение памяти динамическими разделами
В этом случае память машины не делится заранее на разделы. Сначала вся память, отводимая для приложений, свободна. Каждому вновь поступающему на выполнение приложению на этапе создания процесса выделяется вся необходимая ему память (если достаточный объем памяти отсутствует, то приложение не принимается на выполнение и процесс для него не создается). После завершения процесса память освобождается, и на это место может быть загружен другой процесс. Таким образом, в произвольный момент времени оперативная память представляет собой случайную последовательность занятых и свободных участков (разделов) произвольного размера. На рис. 5.9 показано состояние памяти в различные моменты времени при использовании динамического распределения. Так, в момент t0 в памяти находится только ОС, а к моменту t1 память разделена между 5 процессами, причем процесс П4, завершаясь, покидает память. На освободившееся от процесса П4 место загружается процесс П6, поступивший в момент t3.
Функции операционной системы, предназначенные для реализации данного метода управления памятью, перечислены ниже.
Ведение таблиц свободных и занятых областей, в которых указываются начальные адреса и размеры участков памяти.
При создании нового процесса — анализ требований к памяти, просмотр таблицы свободных областей и выбор раздела, размер которого достаточен для размещения кодов и данных нового процесса. Выбор раздела может осуществляться по разным правилам, например: «первый попавшийся раздел достаточного размера», «раздел, имеющий наименьший достаточный размер» или «раздел, имеющий наибольший достаточный размер».
Загрузка программы в выделенный ей раздел и корректировка таблиц свободных и занятых областей. Данный способ предполагает, что программный код не перемещается во время выполнения, а значит, настройка адресов может быть проведена единовременно во время загрузки.
После завершения процесса корректировка таблиц свободных и занятых областей.

Рис. 5.9. Распределение памяти динамическими разделами
По сравнению с методом распределения памяти фиксированными разделами данный метод обладает гораздо большей гибкостью, но ему присущ очень серьезный недостаток — фрагментация памяти. Фрагментация — это наличие большого числа несмежных участков свободной памяти очень маленького размера (фрагментов). Настолько маленького, что ни одна из вновь поступающих программ не может поместиться ни в одном из участков, хотя суммарный объем фрагментов может составить значительную величину, намного превышающую требуемый объем памяти.
Распределение памяти динамическими разделами лежит в основе подсистем управления памятью многих мультипрограммных операционных системах 60-70-х годов, в частности такой популярной операционной системы, как OS/360.
Перемещаемые разделы
Одним из методов борьбы с фрагментацией является перемещение всех занятых участков в сторону старших или младших адресов, так, чтобы вея свободная память образовала единую свободную область (рис. 5.10). В дополнение к функциям, которые выполняет ОС при распределении памяти динамическими разделами* в данном случае она должна еще время от времени копировать содержимое разделов из одного места памяти в другое, корректируя таблицы свободных и занятых областей. Эта процедура называется сжатием. Сжатие может выполняться либо при каждом завершении процесса, либо только тогда, когда для вновь создаваемого процесса нет свободного раздела достаточного размера. В первом случае требуется меньше вычислительной работы при корректировке таблиц свободных и занятых областей, а во втором — реже выполняется процедура сжатия.

Рис. 5.10. Распределение памяти перемещаемыми разделами
Так как программы перемещаются по оперативной памяти в ходе своего выполнения, то в данном случае невозможно выполнить настройку адресов с помощью перемещающего загрузчика. Здесь более подходящим оказывается динамическое преобразование адресов.
Хотя процедура сжатия и приводит к более эффективному использованию памяти, она может потребовать значительного времени, что часто перевешивает преимущества данного метода.
Концепция сжатия применяется и при использовании других методов распределения памяти, когда отдельному процессу выделяется не одна сплошная область памяти, а несколько несмежных участков памяти произвольного размера (сегментов). Такой подход был использован в ранних версиях OS/2, в которых память распределялась сегментами, а возникавшая при этом фрагментация устранялась путем периодического перемещения сегментов.
Билет 41. Сегментное, страничное и сегментно-страничное распределение памяти. Виды фрагментации памяти. Борьба с фрагментацией. Достоинства и недостатки методов распределения памяти.
Сегмент кода 11. Св-ва: возможность чтения (R). Запись запрещена всегда. Размер. Привилегии. Базовый адрес.
Сегмент данных 10. Св-ва: возможность записи(W). Чтение разрешено всегда. Размер. Привилегии. Базовый адрес.
Сегмент LDT 00. Св-ва: чтение и запись НЕВОЗМ. Размер. Привилегии. Базовый адрес.
ВСЕ свойства сегмента хранятся в ДЕСКРИПТОРЕ сегмента. ВСЕ дескрипторы хранятся в GDT или LDT
Страничное распределение
При
страничном распределении виртуальная
память делится на части одинакового и
фиксированного для данной системы
размера, называемыми виртуальными
страницами.
Вся оперативная память также делится
на части такого же размера,
называемые физическими
страницами.
Размер страницы выбирается равным
степени двойки: 512, 1024, 4096 и т.д.

Рис12. Страничное распределение. где, таблица страниц – это внутренняя структура ОС. Адрес страницы входит в контекст процесса. Таблица страниц состоит из дескрипторов. Каждый дескриптор включает:
Номер физической таблицы
Признак присутствия в ОЗУ (формируется аппаратно)
Признак модификации (формируется аппаратно)
Признак обращения (формируется аппаратно)
Виртуальный адрес, который представлен парой (p, sv) преобразуется в (n, sf).Объем страницы равен степени 2k, тогда смещение (s) можно получить отделением к разрядов. Например. Если размер страницы = 1кб (210), то 50718 = 101 000 111 0012, 108=28 – номер страницы. Достоинства:
нет проблемы внешней фрагментации
никак не ограничены размерами физической памяти, т.е. мы часть страниц можем всегда держать во вне и через прерывания их закачивать, когда они нам нужны
Недостатки:
проблема принятия решений об организации таблицы страниц
при страничной организации памяти адресное пространство представляет одну модель от 0 до Ν. Т.е. мы работаем с одним пространством адресации в этом процессе. В некоторых ситуациях это бывает не очень удобно.
Сегментное распределение
При страничном распределении виртуальное адресное пространство делится на равные части механически, без учета смыслового значения данных. В одной странице могут одновременно оказаться код программы и исходные данные. Такой подход не позволяет обеспечить раздельную обработку, например защиту, совместный доступ и т.д. Разбиение адресного пространства на "осмысленные" части устраняет эти недостатки и называется сегментным распределением. Примеры сегментов: код программы, массив исходных данных и пр. На этапе создания процесса, ОС создает таблицу сегментов процесса, аналогичную таблице страниц. (рис.13)

Рис.14 Распределение памяти сегментами

Рис.15. Схема преобразования виртуального адреса в физический при сегментном распределении. где, физический адрес получается путем сложения по модулю 2. К недостаткам сегментного распределения можно отнести следующие:
Использование операции сложения при формировании физического адреса приводит к понижению производительности
Избыточность. Т.к. сегмент в общем случае может быть больше страницы, то следовательно единица обмена между ОЗУ и диском более крупная, что приводит к замедлению работы.
Достоинства:
простота реализации
размер таблицы сегментов может быть много меньше размера таблицы страниц
Недостатки:
наличие внешней фрагментации
сегмент рассматривается как единое целое
Сегментное - страничное распределение
Данный метод представляет собой комбинацию страничного и сегментного механизмов управления памятью и направлен на реализацию достоинств обоих подходов. Виртуальная память делится на сегменты, а каждый сегмент - на страницы. Все современные ОС используют именно такой способ организации.

Рис.16 Схема преобразования виртуального адреса в физический при сегментно - страничном распределении.
Оценим достоинства сегментно-страничного способа. Разбиение программы на сегменты позволяет размещать сегменты в памяти целиком. Сегменты разбиты на страницы, все страницы сегмента загружаются в память. Это позволяет уменьшить обращения к отсутствующим страницам, поскольку вероятность выхода за пределы сегмента меньше вероятности выхода за пределы страницы. Страницы исполняемого сегмента находятся в памяти, но при этом они могут находиться не рядом друг с другом, а «россыпью», поскольку диспетчер памяти манипулирует страницами. Наличие сегментов облегчает реализацию разделения программных модулей между параллельными процессами. Возможна и динамическая компоновка задачи. А выделение памяти страницами позволяет минимизировать фрагментацию.
Однако, поскольку этот способ распределения памяти требует очень значительных затрат вычислительных ресурсов и его не так просто реализовать, используется он редко, причем в дорогих, мощных вычислительных системах. Возможность реализовать сегментно-страничное распределение памяти заложена и в семейство микропроцессоров i80x86, однако вследствие слабой аппаратной поддержки, трудностей при создании систем программирования и операционной системы, практически он не используется в ПК.
Фрагментация — это наличие большого числа несмежных участков свободной памяти очень маленького размера (фрагментов). Настолько маленького, что ни одна из вновь поступающих программ не может поместиться ни в одном из участков, хотя суммарный объем фрагментов может составить значительную величину, намного превышающую требуемый объем памяти.
Фрагментация бывает внутренняя и внешняя. При внешней фрагментации имеется достаточно большая область свободной памяти, но она не является непрерывной. Внутренняя фрагментация может возникнуть вследствие применения системой специфической стратегии выделения памяти, при которой фактически в ответ на запрос память выделяется несколько большего размера, чем требуется, - например, с точностью до страницы (листа), размер которого – степень двойки. Страничная организация памяти подробно рассматривается далее в данной лекции. Внешняя фрагментация может быть уменьшена или ликвидирована путем применения компактировки (compaction) – сдвига или перемешивания памяти с целью объединения всех не смежных свободных областей в один непрерывный блок. Компактировка может выполняться либо простым сдвигом всех свободных областей памяти, либо путем перестановки занятых областей, с выбором на каждом шаге подходящей свободной области методом наиболее подходящего. Компактировка возможна, только если связывание адресов и перемещение происходит динамически. Компактировка выполняется во время исполнения программы. При компактировке памяти и анализе свободных областей может быть выявлена проблема зависшей задачи: какая-либо задача может "застрять" в памяти, так как выполняет ввод-вывод в свою область памяти (по этой причине откачать ее невозможно). Решение данной проблемы: ввод-вывод должен выполняться только в специальные буфера, выделяемой для этой цели операционной системой.
Билет 42. Схема управления ОП в МП семейства Intel 80x86
8080
Пересылка из ячейки памяти в регистр и из регистра в память осуществляется с помощью косвенно регистровой адресации. Это означает, что адрес ячейки памяти загружается в регистровую пару HL, а в командах типа MOV A,M (такие команды кодируются как 01DDD110) в регистр A будет загружено содержимое ячейки памяти, адрес которой содержится в HL. Так как в таких командах требуется обращение к памяти, то на их выполнение нужно два машинных цикла. Система команд процессора очень экономична - она не рассчитана на поддержку языков высокого уровня. Все это появится в Intel-процессорах позже. Средняя длина команды в типичной программе равна двум байтам, а для программ более поздних 16-разрядных процессоров типа 8086 она равна 4,1. Поэтому на логических программах 8-разрядные процессоры не сильно уступали 16-разрядным. Аналогично работают и команды записи в память.
8086
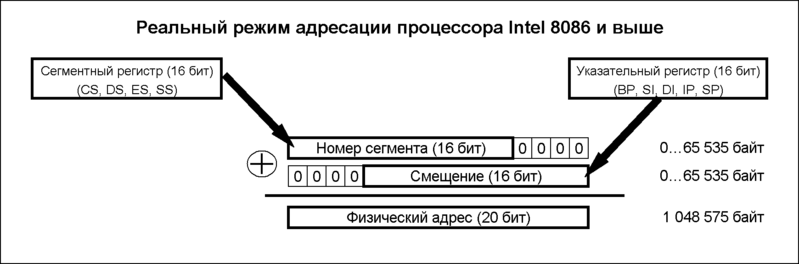
1-й вариант. Для того чтобы адресовать больший, чем i8080, объём памяти, потребовалось изменить способ адресации памяти. Ведь если использовать старые методы, когда адрес к ячейке памяти содержался в указательных регистрах, то пришлось бы увеличивать размер этих самых регистров, чтобы иметь возможность обращаться к большему объёму памяти. Поэтому для адресации 1 Мбайт памяти применили следующую схему. На шину адреса подавался физический адрес размером 20 бит, который формировался путём сложения содержимого одного из сегментных регистров (16 бит), умноженного на 24, с содержимым указательного регистра: таким образом, адресация ячейки памяти производилась по номеру сегмента и эффективному адресу ячейки в сегменте(называемому также смещением). Если результат сложения оказывался больше, чем 220 -1, то 21-й бит отбрасывался; такая процедура называется «заворачиванием» адреса. Этот метод впоследствии (после появления защищённого режима) назвали реальным режимом адресации процессора, такой режим позволяет адресовать до 1 Мбайт памяти.
2-й вариант. Для того чтобы адресовать 1 мегабайт памяти (20 бит адреса) с использованием 16-битных регистров используется сегментирование. Старшие 4 бит адреса выводятся на отдельные контакты корпуса, а младшие 16 выводятся на совмещённую шину адреса-данных. Но граница сегмента не жёсткая, а плавающая. Для того чтобы адресовать нужный сегмент используются 16-битные регистры сегмента, значение которых сдвигается на 4 бита вверх и складывается с указательным 16-битным регистром. Полученное значение — 20 битный адрес памяти или устройства выводится на контакты. Если результат сложения оказывался больше чем 1 мегабайт, выводятся только младшие 20 бит адреса, 21-бит отбрасывается.
Таким
образом, память разделяется на сегменты,
размером 64 Кбайт каждый и начинающиеся
с адреса, кратного 16; память в 1 Мбайт
разделялась, таким образом, на 16 сегментов.
Эти 16 сегментов называют страницами
памяти.
80286
Шина адреса разрядностью 24 бита позволяет адресовать 16 Мбайт физической памяти, но в реальном режиме доступен только 1 Мбайт, начинающийся с младших адресов. С программной точки зрения память так же, как и в 8086, организуется в виде сегментов, но управление сегментацией имеет существенные различия для реального и защищённого режимов.
В реальном режиме по адресации памяти декларируется полная совместимость с процессором 8086, который своей 16-битной адресной шиной охватывает пространство физической памяти в 1 Мбайт. На самом деле, на радость разработчикам программного обеспечения PC, 80286 имеет ошибку, «узаконенную» и в следующих поколениях процессоров. При вычислении физического адреса возможно возникновение переполнения, которое с 20-битной шиной адреса просто игнорируется. Если, например, Seg=FFFFh и EA=FFFFh, физический адрес, вычисленный по формуле РА=16 х Seg + EA=10FFEF, процессором 8086 трактуется как 0FFEF — адрес, принадлежащий первому мегабайту. Однако на выходе А20 процессора 80286 в этом случае установится единичное значение, что соответствует адресу ячейки из второго мегабайта физической памяти. Для обеспечения полной программной совместимости с 8086 в схему PC был введен специальный вентиль Gate A20, принудительно обнуляющий бит А20 системной шины адреса. Не оценив потенциальной выгоды от этой ошибки, управление вентилем узаконили через программно-управляемый бит контроллера клавиатуры 8042. Когда оперативная память подешевела, а «аппетит» программного обеспечения вырос, в эту небольшую область (64К-16 байт) стали помещать некоторые резидентные программы или даже часть операционной системы, а для ускорения управления вентилем появились более быстрые способы (Gate A20 Fast Control).
В отличие от 8086 процессор 80286 имеет средства контроля за переходом через границу сегмента, работающие и в реальном режиме. При попытке адресации к слову, имеющему смещение FFFFh (его старший байт выходит за границу сегмента), или выполнения инструкции, все байты которой не умещаются в данном сегменте, процессор вырабатывает прерывание — исключение типа 13 (0Dh) — Segment Overran Exception. При попытке выполнения инструкции ESCAPE с операндом памяти, не умещающемся в сегменте, вырабатывается исключение типа 9 — Processor Extension Segment Overrrun Interrupt.
В защищенном режиме работают все режимы адресации, допустимые для 8086 и реального режима 80286. Отличия касаются определения сегментов:
сегментные регистры CS, DS, SS и ES хранят не сами базовые адреса сегментов, а селекторы, по которым из таблицы, хранящейся в ОЗУ, извлекаются дескрипторы сегментов
дескриптор описывает базовый адрес, размер сегмента (1 — 64 Кбайт) и его атрибуты;
базовый адрес сегмента имеет разрядность 24 бита, что и обеспечивает адресацию 16 Мбайт физической памяти.
Билет 43. Управление ОП в МП i80286. Дескрипторные таблицы. Схема вычисления адреса ОП.
Шина адреса разрядностью 24 бита позволяет адресовать 16 Мбайт физической памяти, но в реальном режиме доступен только 1 Мбайт, начинающийся с младших адресов. С программной точки зрения память так же, как и в 8086, организуется в виде сегментов, но управление сегментацией имеет существенные различия для реального и защищённого режимов. В реальном режиме по адресации памяти декларируется полная совместимость с процессором 8086, который своей 16-битной адресной шиной охватывает пространство физической памяти в 1 Мбайт. На самом деле, на радость разработчикам программного обеспечения PC, 80286 имеет ошибку, «узаконенную» и в следующих поколениях процессоров. При вычислении физического адреса возможно возникновение переполнения, которое с 20-битной шиной адреса просто игнорируется. Если, например, Seg=FFFFh и EA=FFFFh, физический адрес, вычисленный по формуле РА=16 х Seg + EA=10FFEF, процессором 8086 трактуется как 0FFEF — адрес, принадлежащий первому мегабайту. Однако на выходе А20 процессора 80286 в этом случае установится единичное значение, что соответствует адресу ячейки из второго мегабайта физической памяти. Для обеспечения полной программной совместимости с 8086 в схему PC был введен специальный вентиль Gate A20, принудительно обнуляющий бит А20 системной шины адреса. Не оценив потенциальной выгоды от этой ошибки, управление вентилем узаконили через программно-управляемый бит контроллера клавиатуры 8042. Когда оперативная память подешевела, а «аппетит» программного обеспечения вырос, в эту небольшую область (64К-16 байт) стали помещать некоторые резидентные программы или даже часть операционной системы, а для ускорения управления вентилем появились более быстрые способы (Gate A20 Fast Control). В отличие от 8086 процессор 80286 имеет средства контроля за переходом через границу сегмента, работающие и в реальном режиме. При попытке адресации к слову, имеющему смещение FFFFh (его старший байт выходит за границу сегмента), или выполнения инструкции, все байты которой не умещаются в данном сегменте, процессор вырабатывает прерывание — исключение типа 13 (0Dh) — Segment Overran Exception. При попытке выполнения инструкции ESCAPE с операндом памяти, не умещающемся в сегменте, вырабатывается исключение типа 9 — Processor Extension Segment Overrrun Interrupt. В защищенном режиме работают все режимы адресации, допустимые для 8086 и реального режима 80286. Отличия касаются определения сегментов:
сегментные регистры CS, DS, SS и ES хранят не сами базовые адреса сегментов, а селекторы, по которым из таблицы, хранящейся в ОЗУ, извлекаются дескрипторы сегментов
дескриптор описывает базовый адрес, размер сегмента (1 — 64 Кбайт) и его атрибуты;
базовый адрес сегмента имеет разрядность 24 бита, что и обеспечивает адресацию 16 Мбайт физической памяти.
Дескрипторные таблицы — служебные структуры данных, содержащие дескрипторы сегментов.
В архитектуре x86 есть три вида дескрипторных таблиц:
Глобальная дескрипторная таблица (англ. Global Descriptor Table, GDT);
Локальная дескрипторная таблица (англ. Local Descriptor Table, LDT);
Таблица векторов прерываний (англ. Interrupt Descriptor Table, IDT);
Глобальная дескрипторная таблица
Глобальная дескрипторная таблица является общей для всех процессов. Её размер и расположение в физической памяти определяются регистром GDTR. Размер таблицы не может превышать 8192 дескрипторов, поскольку один дескриптор занимает 8 байт, а лимит в регистре GDTR — двухбайтный и хранит размер таблицы минус один (максимальное значение лимита — 65535), а 8192 x 8 = 65536.
Дескрипторы LDT и сегментов задач (TSS) могут находиться только здесь.
Особенностью GDT является то, что у неё запрещён доступ к первому (с нулевым смещением относительно начала таблицы) дескриптору. Обращение к нему вызывает исключение #GP, что предотвращает обращение к памяти с использованием незагруженного сегментного регистра.
Локальная дескрипторная таблица
В отличие от GDT, LDT может быть много (соответственно количеству задач (потоков), но не обязательно). Каждая задача может иметь свою. На расположение таблицы текущей задачи указывает регистр LDTR.
Размер и расположение LDT в линейной памяти определяются дескриптором LDT из GDT (но это не означает, что размер LDT может быть больше 65536 байт).
Первый дескриптор LDT (№ 0) использовать можно.
Таблица дескрипторов прерываний
Таблица прерываний глобальна. Размещение в физической памяти определяется регистром IDTR.
При возникновении прерывания (внешнего, аппаратного, или вызванного инструкцией Int):
из IDT выбирается дескриптор шлюза, соответственно номеру прерывания;
проверяются условия защиты (права доступа);
при соблюдении условий защиты выполняется переход на подпрограмму-обработчик этого прерывания.
Билет 44. Формат дескриптора сегмента МП i80286
БД- байт доступа содержит тип сегмента привилегий R или W


Билет 45. Формат байта доступа дескриптора сегмента
Номер бита |
Назначение |
0 (P) |
Бит присутствия в памяти. Установлен в 1, если определяемая данным дескриптором таблица страниц находится в оперативной памяти. Этот бит используется для организации виртуальной памяти. |
1 (W) |
Разрешение записи. Если бит установлен в 1, то запись в страницы разрешена. Бит используется для организации защиты от записи на уровне страниц. |
2 (U) |
Пользователь/супервизор. Используется для разграничения доступа к страницам операционной системы (страницы супервизора) и страницам программ пользователя. Значение бита, равное 0, соответствует страницам супервизора, 1 - страницам программы пользователя. |
3-4 |
Эти биты зарезервированы и должны быть установлены в 0 для совместимости со следующими моделями процессора. |
5 (A) |
Бит доступа. Он устанавливается процессором перед выполнением операций чтения страницы или записи в страницу. |
Бит P определяет доступность сегмента (0 — сегмента нет, 1 — есть).
Номер привилегий DPL содержит 2-битный номер (0-3), определяющий, к какому уровню (кольцу) защиты относится этот сегмент.
Тип сегмента, cтарший бит (S) определяет сегмент как системный (S=0) или пользовательский (S=1)
P |
|
|
|
|
|
|
|
DPL тип A (доступ к сегменту)
Типы: сегмент кода(11),сегмент данных(10), LDT(00)
31 15 0
Селектор сегмента |
смещение |
Билет 46. Причины нарушений защиты памяти
1 – попытка записи в сегмент кода
2 – запрет чтения сегмента кода
3 – запрет записи в сегмент данных
4 - попытка обращения за пределы сегмента
5 – попытка обращения к сегменту LDT
6 – недостаточность привилегий программы для обращения к данным сегмента
Билет 47. Кольца защиты. Условие доступа программы к сегменту данных
Процессор i80286 использует более гибкую и надёжную схему защиты операционной системы и программ друг от друга.
В этой схеме используются привилегии четырёх уровней - от 0 до 3. Самые большие привилегии соответствуют уровню 0. Обычно такими привилегиями обладает ядро операционной системы. Минимальные привилегии у пользовательских программ - уровень 3.
Уровни привилегий часто называют кольцами защиты (см. рис. 10).

Рис. 10. Кольца защиты.
Как распределить привилегии программ в операционной системе? Можно использовать, например, такое распределение:
Кольцо 0 - ядро операционной системы, системные драйверы. Привилегированное кольцо. Содержит код и данные операционной системы
Кольцо 1 - программы обслуживания аппаратуры, драйверы, программы, работающие с портами ввода/вывода компьютера. В ОС Windows не поддерживается
Кольцо 2 - системы управления базами данных, расширения операционной системы. В ОС Windows не поддерживается
Кольцо 3 - прикладные программы, запускаемые пользователем. непривелигированное кольцо. Содержит
код и данные пользовательских программ
Программа будет предоставлять доступ к сегментам только в случае, когда уровень привилегий дескриптора запрашиваемого сегмента DPL больше или равен наибольшему из значений текущего уровня привилегий CPL и уровня запрашиваемых привилегий RPL: DPL ≥ max(CPL, RPL) Если программа попытается получить доступ к более привилегированному сегменту памяти, чем она сама, её выполнение будет прервано.
Билет 48. Средства управления памятью в МП i80386. MMU и таблицы управления памятью
Блок управления памятью или устройство управления памятью (англ. memory management unit, MMU) — компонент аппаратного обеспечения компьютера, отвечающий за управление доступом к памяти, запрашиваемым центральным процессором. Его функции заключаются в трансляции адресов виртуальной памяти в адреса физической памяти (то есть управление виртуальной памятью), защите памяти, управлении кэш-памятью, арбитражем шины и, в более простых компьютерных архитектурах (особенно 8-битных), переключением блоков памяти. Иногда также упоминается как блок управления страничной памятью (англ. Paged memory management unit, PMMU)
В настоящее время, чаще всего, упоминается в связи с организацией т. н. виртуальной памяти и, следовательно, критически важен для многих современных многозадачныхоперационных систем, включая все современные Windows NT и многие из UNIX‐подобных. Специальная редакция ядра Linux, μClinux, может работать без MMU.
Блок управления памятью в настоящее время очень часто включается в состав центрального процессора или чипсета компьютера.
Принципы работы
Принцип работы современных MMU основан на разделении виртуального адресного пространства (одномерного массива адресов, используемых центральным процессором) на участки одинакового, как правило несколько килобайт, хотя, возможно, и существенно большего, размера равного степени 2, называемые страницами. Младшие n бит адреса (смещение внутри страницы) остаются неизменными. Старшие биты адреса представляют собой номер (виртуальной) страницы. MMU обычно преобразует номера виртуальных страниц в номера физических страниц используя буфер ассоциативной трансляции (англ. Translation Lookaside Buffer, TLB). Если преобразование при помощи TLB невозможно, включается более медленный механизм преобразования, основанный на специфическом аппаратном обеспечении или на программных системных структурах. Данные в этих структурах как правило называются элементами таблицы страниц (англ. page table entries (PTE)), а сами структуры — таблицами страниц (англ. page table, PT). Конкатенация номера физической страницы со смещением внутри страницы дает физический адрес.
Элементы PTE или TLB могут также содержать дополнительную информацию: бит признака записи в страницу (англ. dirty bit), время последнего доступа к странице (англ. accessed bit, для реализации алгоритма замещения страниц наиболее давно использованный (англ. least recently used, LRU), какие процессы (пользовательские (англ. user mode) или системные(англ. supervisor mode)) могут читать или записывать данные в страницу, необходимо ли кэшировать страницу
Билет 49. Схема вычисления адреса памяти в МП i80386
Логический (виртуальный) адрес
Ofs 32 32
16
ОП

GDT
LDT
Т Линейный
 база
адрес
база
адрес
MMU
