

Основні принципи роботи ацп.
По-перше, він робить дискретизацію записуваного звукового сигналу за часом. Це означає, що вимір рівня інтенсивності звуку виконується через рівні проміжки часу. Частоту, що характеризує періодичність вимірювання звукового сигналу прийнято називати частотою дискретизації. Питання про її вибір далеко не вільне і відповідь у значній мірі залежить від спектра сигналу, що зберігається: існує спеціальна теорема Найквіста, відповідно до якої частота "оцифровки" звуку повинна як мінімум у 2 рази перевищувати максимальну частоту, що входить до складу спектра сигналу. Вважається, що звичайна людина чує звук частотою не більш 20 000 Гц (20 кгц). Тому для високоякісного відтворення звуку верхню границю звичайно з деяким запасом приймають рівної 22 кгц. Звідси випливає, що частота звукозапису в таких випадках повинна бути не нижче 44 кгц. Названа частота використовується, зокрема, при запису музичних компакт-дисків. Однак часто така висока якість не потрібна, і частоту дискретизації можна значно знизити. Наприклад, при запису мови цілком достатньо частоти дискретизації 8 кгц. Помітимо, що результат при цьому виходить хоча і не блискучий, але легко розбірливий – згадайте, як ви чуєте голоси своїх друзів по телефону.
По-друге, АЦП робить дискретизацію амплітуди звукового сигналу. Це варто розуміти так, що при вимірюванні існує "сітка" стандартних рівнів (наприклад, 256 чи 65536 – ця кількість характеризує глибину кодування), і поточний рівень вимірюваного сигналу округляється до найближчого з них. Напрошується лінійна залежність між величиною вхідного сигналу і номером рівня. Іншими словами, якщо голосність зростає в 2 рази, то інтуїтивно очікується, що і відповідне йому число зросте вдвічі. У найпростіших випадках так і робиться, але, як показує більш детальне вивчення, це не найкраще рішення. Проблема в тому, що в широкому діапазоні голосності звуку людське вухо не є лінійним. Наприклад, при дуже голосних звуках (коли "вуха закладає"), збільшення або зменшення інтенсивності звуку майже не дає ефекту, у той час як при сприйнятті шепоту дуже незначне падіння рівня може приводити до повної втрати розбірливості. Тому при запису цифрового звуку, особливо при 8-бітному кодуванні, часто використовують різні нерівномірні розподіли рівнів гучності, в основі яких лежить логарифмічний закон .
Отже, у ході «оцифровки» звуку ми одержуємо потік цілих чисел, що представляють собою стандартні амплітуди сигналів через рівні проміжки часу. На рис.1. процес дискретизації проілюстровано графічно:
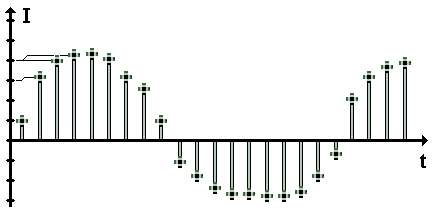
Рис.1.
На рисунку представлений процес "оцифровки" залежності інтенсивності звукового сигналу I від часу t. Чітко видно дискретизацію за часом (рівномірні відбитки на горизонтальній осі) та за інтенсивністю сигналу (необхідно при цьому округлення схематично зображене "зломами" горизонтальних ліній розмітки). Підкреслимо, що на малюнку ступінь дискретизації для наочності свідомо перебільшена: реальне розходження між сусідніми рівнями дискретизації по обох осях значно менше і, отже, форма сигналу передається набагато точніше.
Ми розглянули лише найбільш загальні принципи запису цифрового звуку. На практиці для одержання якісних звукових файлів використовується ціла низька додаткових технічних прийомів.
Викладений метод перетворення звукової інформації для збереження в пам'яті комп'ютера підтверджу тезу: будь-яка інформація для збереження в комп'ютері приводиться до цифрової форми і потім переводиться в двійкову систему. Тепер ми знаємо, що і звукова інформація не є виключенням з цього фундаментального правила.