

Розділ 7 СЛОВНИКОВІ МЕТОДИ СТИСНЕННЯ ЗІВА-ЛЕМПЕЛА
Раніше нами розглядалися статистичні методи стиснення інформації. Словникові алгоритми мають менш математичне обґрунтування, але більш практичний характер. Майже усі словникові методи розроблені ізраїльськими вченими Якобом Зівом (Ziv) та Абрамом Лемпелем (Lempel) і були вперше опубліковані у 1977 році.
Суть словникових методів полягає в тому, що повторювані підрядки у повідомленні замінюються покажчиками на місце у повідомленні, де ці підрядки вже раніше з'являлися. Декодування стиснутого повідомлення здійснюється заміною покажчика готовою фразою із словника, на яку цей покажчик вказує. LZ-методи забезпечують високий степінь стиснення даних, і їхньою важливою перевагою є швидка робота декодера.
Всі словникові методи можна поділити на дві групи.
До першої групи належать алгоритми з використанням «ковзного» за повідомленням вікна, розділеного на дві нерівні за об'ємом частини: перша, більша за розміром, включає фрагмент повідомлення, що вже проглянуто, – ця частина використовується як словник, друга частина вікна, набагато менша, виступає як буфер, що містить ще незакодовані символи вхідного потоку. Звичайно розмір ковзного вікна займає декілька кілобайтів, а розмір буфера - не більше 100 байтів. Алгоритми цієї групи відшукують у словнику (більшій частині вікна) ланцюжки символів, що збігаються із вмістом буфера, і замінюють ці ланцюжки покажчиками на їхнє попереднє входження у повідомлення, тобто на вміст словника. Словник в неявному вигляді міститься у закодованих даних, а зберігаються покажчики на повторювані ланцюжки символів (підрядки), що зустрічаються у повідомленні.
Усі алгоритми першої групи словникових методів базуються на алгоритмі, що має назву за іменами його авторів і роком розроблення – LZ77. Найдосконаліший представник цієї групи –алгоритм LZSS, опублікований у 1982 році Сторером (Storer) та Шиманські (Szimanski).
Алгоритми другої групи доповнюють початковий словник джерела словником фраз, що є повторюваними у повідомленні комбінаціями символів початкового словника. При цьому розмір словника збільшується, і для його кодування потрібне більше число бітів, але значна частина словника представлятиме вже не окремі букви, а сполучення букв або цілі слова. Якщо кодер знаходить фразу, що раніше зустрічалася, він замінює її індексом цієї фрази у словнику. При цьому довжина коду індексу виходить менше або набагато менше довжини коду незакодованого підрядка.
Базовий алгоритм другої групи словникових методів – алгоритм LZ78, розроблений Зівом і Лемпелем у 1978 році. Найдосконаліший представник цієї групи словникових методів – алгоритм LZW, запропонований у 1984 році Тері Уелчем.
7.1 Алгоритм lz77
Основна ідея алгоритму LZ77 полягає в тому, що друге і подальші входження деякого підрядка символів у повідомленні замінюються покажчиками на його перше або попереднє входження. Алгоритм використовує частину повідомлення, що вже проглянуто, як словник. Щоб добитися стиснення, він намагається замінити наступну фразу повідомлення покажчиком на вміст словника.
Позначимо через N розмір «ковзного» вікна; F - розмір буфера. Тоді перші N-F символів - це вже закодовані символи, що містить словник, а останні F символів – вміст випереджуючого буфера.
При кодуванні вмісту буфера серед попередніх N-F символів, тобто у словнику, шукається найдовший підрядок, що збігається з початком буфера. Знайдений найбільший збіг кодується тріадою <i, j, a>, де i - зсув у словнику підрядка, що збігається із початком буфера; j - довжина підрядка, що збігається; а - перший символ, що йде за підрядком, що збігається. Далі алгоритм зсовує увесь вміст вікна на j+1 символів і водночас зчитує стільки ж символів вхідного потоку у буфер.
Об'єм
пам'яті, що потребує алгоритм-кодер або
декодер, визначається розміром вікна
N.
Довжина коду обчислюється так: довжина
підрядка, що співпав із вмістом словника,
не може бути більше розміру буфера F,
а зсув цього підрядка у словнику не може
бути більше розміру словника мінус 1.
Отже, довжина двійкового коду зсуву
i
буде округлений
до більшого цілого
 ,
а довжина коду довжини підрядка j
буде
округлений у більшу сторону
,
а довжина коду довжини підрядка j
буде
округлений у більшу сторону
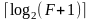 ,
а символ а
кодується 8
бітами за таблицею ASCII+.
,
а символ а
кодується 8
бітами за таблицею ASCII+.
При декодуванні виконується той же самий порядок роботи з вікном, що й при кодуванні, але на відміну від пошуку підрядків, що збігаються, вони, навпаки, копіюються декодером з вікна згідно з черговою тріадою коду.
Приклад 1 (а) Закодуємо за алгоритмом LZ77 рядок «КРАСНАЯ КРАСКА»; розмір словника 8 байтів, буфера – 5 байтів.
Кодування повідомлення подається табл. 2.13.
В останньому рядку таблиці буква «А» береться не із словника, оскільки вона остання.
Таблиця 2.13
Словник (8 Бт) |
Буфер (5 Бт) |
Код
|
||||||||||||||||||
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
1 |
2 |
3 |
4 |
5 |
||||||||
. |
. |
. |
. |
. |
. |
. |
. |
К |
Р |
А |
С |
Н |
<0, 0, ‘К’> |
|||||||
. |
. |
. |
. |
. |
. |
. |
К |
Р |
А |
С |
Н |
А |
<0, 0, ‘Р’> |
|||||||
. |
. |
. |
. |
. |
. |
К |
Р |
А |
С |
Н |
А |
Я |
<0, 0, ‘А’> |
|||||||
. |
. |
. |
. |
. |
К |
Р |
А |
С |
Н |
А |
Я |
|
<0, 0, ‘С’> |
|||||||
. |
. |
. |
. |
К |
Р |
А |
С |
Н |
А |
Я |
|
К |
<0, 0, ‘Н’> |
|||||||
. |
. |
. |
К |
Р |
А |
С |
Н |
А |
Я |
|
К |
Р |
<5, 1, ‘Я’> |
|||||||
. |
К |
Р |
А |
С |
Н |
А |
Я |
|
К |
Р |
А |
С |
<0, 0, ‘ ’> |
|||||||
К |
Р |
А |
С |
Н |
А |
Я |
|
К |
Р |
А |
С |
К |
<0, 4, ‘К’> |
|||||||
А |
Я |
|
К |
Р |
А |
С |
К |
А |
. |
. |
. |
. |
<0, 0, ‘А’> |
|||||||
Довжина отриманого коду Lcode=9(3+3+8)=126 (бітів) проти LASCII+=148=112 (бітів) коду нестисненого рядка.
Приклад 1 (б) Розпакуємо повідомлення, закодоване за алгоритмом LZ77, довжина словника 8 байтів. Код стисненого повідомлення: <0,0,‘K’> <0,0,‘P’> <0,0,‘A’> <0,0,‘C’> <0,0,‘H’> <5,1,‘Я’> <0,0,‘ ’> <0,4,‘K’> <0,0,‘A’>.
Розпаковування повідомлення показано у табл. 2.14.
Таблиця 2.14
Вхідний код |
Вихід |
Словник |
|||||||||
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
||||
<0, 0, ‘K’> |
«К» |
. |
. |
. |
. |
. |
. |
. |
К |
||
<0, 0, ‘P’> |
«Р» |
. |
. |
. |
. |
. |
. |
К |
Р |
||
<0, 0, ‘A’> |
«А» |
. |
. |
. |
. |
. |
К |
Р |
А |
||
<0, 0, ‘C’> |
«С» |
. |
. |
. |
. |
К |
Р |
А |
С |
||
<0, 0, ‘H’> |
«Н» |
. |
. |
. |
К |
Р |
А |
С |
Н |
||
<5, 1, ‘Я’> |
«АЯ» |
. |
К |
Р |
А |
С |
Н |
А |
Я |
||
<0, 0, ‘ ’> |
« » |
К |
Р |
А |
С |
Н |
А |
Я |
|
||
<0, 4, ‘K’> |
«КРАСК» |
А |
Я |
|
К |
Р |
А |
С |
К |
||
<0, 0, ‘A’> |
«А» |
Я |
|
К |
Р |
А |
С |
К |
А |
||
Наведемо процедури кодування та декодування за алгоритмом LZ77 .
Кодер:
While (lookAheadBuffer not empty)
get a pointer(position, match) to the longest match
in the window for the lookahead buffer;
if (lehgth>Minimum_Match_Length)
output a(position, length) pair;
shift the window length characters along;
else
output the first character in the lookaheadbuffer;
shift the window 1 character along.
Декодер:
Whenever a(position, length) pair is encountered,
go to that (position) in the window and copy (length) bytes to the output.
Недоліки алгоритму LZ77:
1) із збільшенням розміру словника швидкість роботи алгоритму кодера пропорційно сповільнюється;
2) кодування поодиноких символів дуже неефективне.