

Повторить с п.2 для всех элементов входного множества.
Цикл обучения продолжается до достижения системой нужного состояния. В качестве критериев останова процесса обучения можно использовать следующие:
 Топологическая
упорядоченность карты признаков
(матрицы весов).
Топологическая
упорядоченность карты признаков
(матрицы весов).Изменения весов становятся незначительными.
Выход сети стабилизируется, т.е. входные вектора не переходят между кластерными элементами.
В данном случае количество циклов обучения было просто ограничено константой N = 50 . P , где P - количество элементов во входном множестве.
25. Методы кластеризации. Алгоритм четкой кластеризации.
Кластеризация (или кластерный анализ) — это задача разбиения множества объектов на группы, называемые кластерами. Внутри каждой группы должны оказаться «похожие» объекты, а объекты разных группы должны быть как можно более отличны. Главное отличие кластеризации от классификации состоит в том, что перечень групп четко не задан и определяется в процессе работы алгоритма.
Применение кластерного анализа в общем виде сводится к следующим этапам:
Отбор выборки объектов для кластеризации.
Определение множества переменных, по которым будут оцениваться объекты в выборке. При необходимости – нормализация значений переменных.
Вычисление значений меры сходства между объектами.
Применение метода кластерного анализа для создания групп сходных объектов (кластеров).
Представление результатов анализа.
![]() После
получения и анализа результатов возможна
корректировка выбранной метрики и
метода кластеризации до получения
оптимального результата.
После
получения и анализа результатов возможна
корректировка выбранной метрики и
метода кластеризации до получения
оптимального результата.
Четкая (непересекающаяся) кластеризация - кластеризация, которая каждый Xj из ж относит только одному кластеру. При четкой кластеризации каждой точке ставится в соответствие номер класса. 2-е свойство – совокупность всех кластеров должна исчерпывающе охватывать все объекты входной совокупности.
Кластеры взаимоисключающи, ни один из объектов не может принадлежать двум кластерам одновременно.
Метод k-means (i - среднее)
 – объекты с
характерным набором признаков в n-мерном
пространстве. Каждый объект принадлежит
отдельному кластеру. Каждый кластер
характеризуется набором признаков.
Центроидом каждого кластера является
центр с параметрами.
– объекты с
характерным набором признаков в n-мерном
пространстве. Каждый объект принадлежит
отдельному кластеру. Каждый кластер
характеризуется набором признаков.
Центроидом каждого кластера является
центр с параметрами.
 Алгоритм:
Алгоритм:
Каждому
объекту ставится в соответствие

Выявление и нахождение кластеров во множестве данных должно удовлетворять требованиям :
Каждый кластер должен представлять концепт однородности и содержать объекты с близкими значениями свойств и признаков.
Совокупность кластеров должна исчерпывающе охватывать все объекты исследуемой совокупности
Кластеры должны быть взаимоисключающие – ни один из объектов не должен принадлежать двум кластерам сразу
Сложность задачи – выбор различных наборов исходных данных и набора кластеров дают различные результаты.


26. Методы кластеризации. Алгоритм нечеткой кластеризации.
Нечеткая
кластеризация - кластеризация,
при которой для каждого х4
из ж
определяется![]() -
вещественное значение, показывающее
степень принадлежности х4
к кластеру j. Пример:
-
вещественное значение, показывающее
степень принадлежности х4
к кластеру j. Пример:
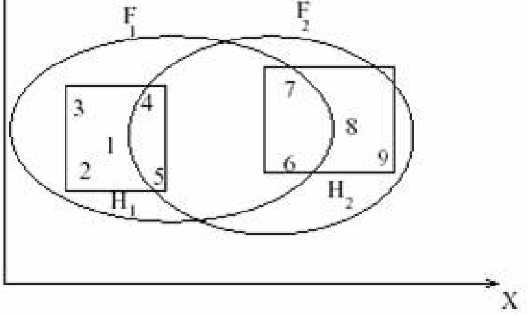
F = {(1,0.9), (2,0.8), (3,0.7), (4,0.6), (5,0.55), (6,0.2), (7,0.2), (8,0.0), (9,0.0)}
F2 = {(1,0.0), (2,0.0), (3,0.0), (4,0.1), (5,0.15), (6,0.4), (7,0.35), (8,1.0), (9, 0.9)}
Алгоритм нечеткой кластеризации называют FCM-алгоритмом (Fuzzy Classifier Means, Fuzzy C-Means). Целью FCM-алгоритма кластеризации является автоматическая классификация множества объектов, которые задаются векторами признаков в пространстве признаков. Другими словами, такой алгоритм определяет кластеры и соответственно классифицирует объекты. Кластеры представляются нечеткими множествами, и, кроме того, границы между кластерами также являются нечеткими.
FCM-алгоритм кластеризации предполагает, что объекты принадлежат всем кластерам с определенной ФП. Степень принадлежности определяется расстоянием от объекта до соответствующих кластерных центров. Данный алгоритм итерационно вычисляет центры кластеров и новые степени принадлежности объектов.
Для заданного множества К входных векторов хk и N выделяемых кластеров сjпредполагается, что любой хк принадлежит любому сj с принадлежностью µjkинтервалу [0,1], где j – номер кластера, а k – номер входного вектора.
Принимаются во внимание следующие условия нормирования для µjk:
Цель
алгоритма – минимизация суммы всех
взвешенных расстояний ![]() :
:
![]() ,
,
где q – фиксированный параметр, задаваемый перед итерациями.
Для достижения вышеуказанной цели необходимо решить следующую систему уравнений:
![]()
Совместно с условиями нормирования µjk данная система дифференциальных уравнений имеет следующее решение:
 ;
;
(взвешенный центр гравитации) и
Алгоритм нечеткой кластеризации выполняется по шагам
1. Инициализация.
Выбираются следующие параметры:
• необходимое количество кластеров N, 2 < N < К;
• мера расстояний, как Евклидово расстояние;
• фиксированный параметр q (обычно 1,5);
• начальная
(на нулевой итерации) матрица
принадлежности ![]() объектов хk с
учетом заданных начальных центров
кластеров сj.
объектов хk с
учетом заданных начальных центров
кластеров сj.
2. Регулирование
позиций  центров
кластеров.
центров
кластеров.
На t-м
итерационном шаге при известной матрице
 , вычисляется
в
соответствии с вышеприведенным решением
системы дифференциальных уравнений.
, вычисляется
в
соответствии с вышеприведенным решением
системы дифференциальных уравнений.
3. Корректировка значений принадлежности µjk.
Учитывая
известные
,
вычисляются
,
если  , в
противном случае:
, в
противном случае:
![]()
4. Остановка алгоритма.
Алгоритм нечеткой кластеризации останавливается при выполнении следующего условия:
![]()
где || || – матричная норма (например, Евклидова норма);
![]() –
заранее задаваемый
уровень точности.
–
заранее задаваемый
уровень точности.
34.Рекурсия
При работе с данными часто требуется произвести такие действия, как поиск элементов в базе данных или вывод данных на экран, выполнить несколько раз. Система Visual Prolog не содержит встроенных предикатов для выполнения повторяемых (циклических) действий, подобных операторам for, while и repeat..until (do{…}while) декларативных языков. В Прологе существует два способа реализации правил, выполняющих одну и ту же задачу многократно: повторение и рекурсия.
Правило, содержащее в своем теле в качестве компоненты само себя, называется правилом рекурсии. Вид правила, выполняющего рекурсию, следующий:
рекурсивное_правило:- /* правило рекурсии */
<предикаты и правила>,
рекурсивное_правило.
Последней подцелью тела правила рекурсивное_правило является само правило.
Рекурсия является естественным способом описания любой проблемы, содержащей внутри себя другую проблему такого же вида. Логически рекурсивные алгоритмы имеют структуру индуктивного математического доказательства. Правила повтора и рекурсии могут приводить к одинаковым результатам, однако алгоритмы их выполнения не одинаковы. Каждое из них имеет свои преимущества в конкретной ситуации. Правила повтора эффективны и позволяют сэкономить память, однако переменные в таких правилах освобождаются после каждой итерации и их значения теряются. Рекурсия, например, позволяет сохранить в переменных некоторые значения, но она не всегда эффективно использует память и, соответственно, может потребовать больше системных ресурсов, т.к. всякий раз при выполнении рекурсивного вызова новые копии используемых значений помещаются в стек (область памяти, используемая в основном для передачи значений между правилами). Значения в стеке сохраняются до тех пор, пока правило не завершится (успешно или неуспешно). Использование стека оправдано в тех случаях, когда промежуточные значения должны храниться в определенном порядке для дальнейшего использования. Метод организации рекурсивной обработки данных подходит для целого ряда применений, начиная с обработки файлов и заканчивая математическими вычислениями (например, вычисление факториала).
пример рекурсивного правила:
напечатать_строку:- write("Демонстрация простой рекурсии"),
nl,
напечатать_строку.
Это правило состоит из трех подцелей. Первые две выдают строку "Демонстрация простой рекурсии" и переводят курсор в начало следующей строки. Третья подцель - это само правило. Так как правило напечатать_строку содержит само себя, то для того, чтобы быть успешным, оно должно само себя удовлетворить. Удовлетворение третьей подцели приводит к новому вызову первых двух. Этот процесс продолжается бесконечно, и в результате строка выдается на экран бесконечное число раз. Однако при возникновении бесконечной рекурсии количество элементов данных, используемых рекурсивным процессом, непрерывно растет и в некоторый момент стек переполнится. Возникновение переполнения во время выполнения программы нежелательно, так как в результате могут оказаться утерянными существенные данные.
Возникновения бесконечной рекурсии можно избежать. Для этого следует ввести предикат завершения, содержащий условие выхода. Формулировка условия выхода для правила напечатать_строку может иметь вид: "Продолжать печать строки до тех пор, пока счетчик печати не превысит число 7, после чего остановить процесс". Определение условий выхода и включение их в правило рекурсии является очень важным элементом программирования на Прологе.
30. Структура программы Visual Prolog.
Как реализация принципов логического программирования язык PROLOG вносит
интересный и существенный вклад в решение задач искусственного интеллекта. Наиболее
важное значение имеет декларативная семантика (declarative semantics) — средство
прямого выражения взаимосвязей в задачах искусственного интеллекта, а также
встроенные средства унификации и некоторые приемы проверки соответствия и поиска.
40. Інструментальні засоби розробки систем штучного інтелекту.
Экспертные системы (ЭС) - это системы искусственного интеллекта, предназначенные для решения плохоформализованных и слабоструктурированных задач в определенных проблемных областях, на основе заложенных в них знаний специалистов-экспертов. В настоящее время СИИ внедряются в различные виды человеческой деятельности, где использование точных математических методов и моделей затруднительно или вообще невозможно. К ним относятся: медицина, обучение, поддержка принятия решений и управление в сложных ситуациях, деловые различные приложения и т. д.
Основными компонентами СИИ являются базы данных (БД) и знаний (БД), блоки поиска решения, объяснения, извлечения и накопления знаний, обучения и организации взаимодействия с пользователем. БД, БЗ и блок поиска решений образуют ядро СИИ.
Для конструирования СИИ используются различные инструментальные средства: универсальные языки программирования, языки искусственного интеллекта, инструментальные системы и среды и системы-оболочки. Системы-оболочки являются наиболее простым средством формализации, практически не требующие участия посредников в лице инженера по знаниям или программиста при их использовании. Инженер по знаниям только помогает эксперту выбрать наиболее подходящую для его проблемной области оболочку.
Известны три основные разновидности исполнения экспертных систем:
- системы, в виде отдельных программ, на алгоритмическом языке, база знаний которых является непосредственно частью этой программы. При построении таких систем применяются традиционные процедурные языки C++, Java и др., и специализированные языки СИИ: LISP, PROLOG.
- Оболочки - программный продукт, обладающий средствами представления знаний для определенных предметных областей. Задача пользователя заключается не программировании, а в формализации и вводе знаний. Примером могут служить ИНТЕРЭКСПЕРТ, РС+, VP-Expert.
- Генераторы - мощные программные продукты, предназначенные для получения оболочек, ориентированных на представление знаний в зависимости от рассматриваемой предметной области. Примеры - системы KEE, ART.
Системы EXSYS и GURU относятся к системам дедуктивного продукционного типа, причем система GURU по сути является инструментальной средой, поддерживающей различные режимы конструирования прикладных СИИ и обладающей достаточно развитыми средствами обработки фактора неопределенности. Экспертная система Exsys представляет собой СИИ, которая может быть использована для разработки базы знаний в любой предметной области. При этом знания представляются в виде правил.
Среди наиболее распространенных в настоящее время СИИ и их оболочек можно выделить следующие: INSIGT, LOGIAN, NEXPERT, RULE MASTER, KDS, PICON, KNOWLEDGE CRAFT, KESII, S1, TIMM.
Cистема VP-Expert представляет собой "пустую" оболочку, получившую достаточно широкое распространение. Важной особенностью оболочки, существенно расширяющей ее возможности, является совместимость с файлами созданными dBASE II, dBASE III и dBASE III+.
MATLAB. Нынешний MATLAB - это высокоэффективный язык инженерных и научных вычислений. Он поддерживает математические вычисления, визуализацию научной графики и программирование с использованием легко осваиваемого операционного окружения. В этой среде существуют пакеты прикладных программ, для моделирования СИИ, распознавиния графики, создания модели нейронных сетей.
Prolog — язык логического программирования, основанный на логике дизъюнктов Хорна, представляющей собой подмножество логики предикатов первого порядка. Целью разработки языка Prolog было предоставить возможность задания спецификаций решения и позволить компьютеру вывести из них последовательность выполнения для этого решения, а не задание алгоритма решения задачи, как в большинстве языков.
В настоящее время Пролог, несмотря на неоднократные пессимистические прогнозы, продолжает развиваться и вбирает в себя новые технологии и концепции, парадигмы императивного программирования. В частности, одно из направлений развития языка реализует концепцию интеллектуальных агентов.
Пролог реализован практически для всех известных операционных систем и платформ (в том числе для Java и .NET). В число операционных систем входят OS для мэйнфреймов, всё семейство Unix, Windows, OS для мобильных платформ.
31. Правила в Visual Prolog.
Для решения задач система Prolog использует механизм логического вывода новых утверждений из уже известных. Для того чтобы воспользоваться этим методом, необходимо иметь четкое описание задачи в виде фраз Хорна, выраженных на языке Prolog, т.е. в виде правил и фактов. Логика предикатов позволяет выразить логические понятия в письменной форме. В логике предикатов элементарным объектом, обладающим истинностным значением, является предикат (формула). Предикат представляет собой отношение между объектами (сущностями рассматриваемой предметной области) и состоит из 2-х частей: имени (обозначения) предиката и списка аргументов(термов).
Программа на языке Prolog содержит описание структуры прикладной задачи, состоящее из множества фраз, которое можно рассматривать как сеть отношений, существующих между объектами. Фраза – это либо факт, либо правило. Факт представляет собой утверждение о том, что некоторое отношение является истинным. Он записывается как имя, за которым следует список термов (объектов), заключенный в скобки. Факт – это фраза без условий, показывающая простую взаимосвязь данных. Нижеследующий факт выражает мысль о том, что Дмитрию нравится играть в теннис:
нравится(дмитрий, теннис).
Правило - это предложение, истинность которого зависит от истинности одного или нескольких предложений. Обычно правило содержит несколько хвостовых целей, которые должны быть истинными для того, чтобы правило было истинным.
В нотации БНФ(нормальной формой Бэкуса-Наура) правило будет иметь вид:
<Правило>::=<предикат>:-<предикат>[,<предикат>]*.
Правило – это факт, истинность которого зависит от истинности образующих тело правила условий, т.е. правила позволяют получать (выводить) новые факты из уже существующих.
Пример. Известно, что бабушка человека - это мама его мамы или мама его папы.
Соответствующие правила будут иметь вид:
бабушка(X,Y):-
мама(X,Z),мама(Z,Y).
бабушка(X,Y):-
мама(X,Z),папа(Z,Y).
Символ ":-" означает "если", и вместо него можно писать if.
Символ "," - это логическая связка "и" или конъюнкция, вместо него можно писать and.
Первое правило сообщает, что X является бабушкой Y, если существует такой Z, что X является мамой Z, а Z - мамой Y. Второе правило сообщает, что X является бабушкой Y, если существует такой Z, что X является мамой Z, а Z - папой Y.В данном примере X, Y и Z - это переменные.
Условие, входящее в тело правила, называется подцелью. Подцели разделяются запятыми, в конце правила ставится точка. Каждая подцель является обращением к предикату, которое может быть успешным или неуспешным. Для того, чтобы заголовок правила оказался истинным, необходимо, чтобы каждая подцель, входящая в тело, была истинной.
32. Цель Visual Prolog. Представление целей.
Программирование на Prolog сводится к нахождению информации, которая удовлетворяет поставленной цели. Visual Prolog использует механизм логического вывода с поиском и возвратом - сопоставляет шаблон, содержащийся в целевом запросе, с информацией, заключенной в фактах и правилах программы. Пролог пытается доказать истинность гипотезы (т.е. ответить на вопрос) путем сравнения ее с заведомо истинными утверждениями, представленными в разделе clauses. Система берет одну из подцелей запроса и просматривает список известных фактов и правил на предмет соответствия подцели; если факт найден, подцель считается истинной. Если истинность запроса доказана (все подцели запроса удовлетворены), гипотеза считается истинной, в противном случае – ложной- и система возвращает либо no (если в запросе нет переменных), либо No solution.
Если цель программы - простой запрос, не содержащий переменных: необходимо найти в программе факт, идентичный представленному в запросе, и в случае успеха выдается положительный ответ (yes). Если запрос составной и в качестве аргументов содержит переменные, каждая переменная должна получить конкретное значение, что происходит путем связывания этой переменной с константой соответствующего запросу факта и правила. Особенность такого поиска: нахождение не одного, а всех возможных решений задачи. Однако, данная особенность не всегда удобна, т.к. она может привести к ненужному поиску: например, возможны случаи, когда требуется найти уникальное решение, или наоборот, когда необходимо вынудить систему продолжать поиск дополнительных решений даже после того, как специфическая цель была удовлетворена. В таких случаях используются предикаты fail (вынуждающий продолжать поиск) и cut (!) ( для завершения перебора с возвратами).
Очевидно, что системой управляет цель программы, которая обеспечивает выполнение последовательности определенных задач. Обычно цель программы содержит одну или несколько подцелей, которые могут быть либо фактами, либо правилами.
Если правило не может быть успешно вычислено, Пролог выполняет откат, чтобы найти другие возможные пути вычисления этого правила. Откат - это механизм, использующийся системой для нахождения дополнительных фактов и правил, необходимых для вычисления цели, если текущая попытка вычислить цель оказалась неудачной. По мере того, как Пролог успешно заканчивает попытки вычисления подцелей слева направо, маркеры (указатели) отката расставляются во всех точках, которые могут привести к решению. Если некоторая подцель оказывается неуспешной, то система откатывается влево и останавливается у ближайшего указателя отката. Если все попытки удовлетворить одну из подцелей потерпели неудачу, цель программы считается неистинной и система возвращает ответ No solution.
Программа на Прологе может содержать вопрос в программе (так называемая внутренняя цель). Если программа содержит внутреннюю цель, то после запуска программы на выполнение система проверяет достижимость заданной цели.
Если внутренней цели в программе нет, то после запуска программы система выдает приглашение вводить вопросы в диалоговом режиме (внешняя цель). Программа, компилируемая в исполняемый файл, обязательно должна иметь внутреннюю цель.
33. Структура программы в Visual Prolog.
в разделе constants описываются константы, которые в дальнейшем могут использоваться вместо неудобных термов языка (длинных строк, больших чисел и т.д. );
раздел databasе содержит утверждения, которые являются предикатами динамической базы данных (если программа такой базы данных не требует, то этот раздел может быть опущен);
раздел domains содержит определения доменов (типов), которые описывают различные классы объектов, используемых в программе;
в разделе predicates объявляются используемые в программе предикаты;
в раздел clauses заносятся априорно известные факты и правила, используемые системой при попытке удовлетворить цель программы (о содержимом этого раздела можно говорить как о данных, необходимых для работы программы);
раздел goal содержит формулировку цели создаваемой программы.
DOMAINS % объявление доменов
argument_type1, ..., argument_typeN = <standard domain>
PREDICATES % объявление предикатов
predicateName(argument_type1, argument_type2, ..., argument_typeN)
CLAUSES % объявление фактов и правил
clauses (rules and facts)
GOAL % задание цели программы
subgoal_1,
subgoal_2 , …
subgoal_N .
37. Динамическая база данных.
В Прологе существуют специальные средства для организации внутренних и внешних баз данных. Эти средства рассчитаны на работу с реляционными базами данных. Внутренние подпрограммы унификации осуществляют автоматическую выборку фактов из внутренней (динамической) базы данных с нужными значениями известных параметров и присваивают значения неопределенным параметрам. Раздел программы facts в Visual Prolog предназначен для описания предикатов динамической (внутренней) базы данных. База данных называется динамической, так как во время работы программы из нее можно удалять любые факты, а также добавлять новые факты. В этом состоит ее отличие от статических баз данных, где факты являются частью кода программы и не могут быть изменены во время исполнения. Иногда бывает полезно иметь часть информации базы данных в виде фактов статической БД - эти данные заносятся в динамическую БД сразу после активизации программы. В общем случае, предикаты статической БД имеют другое имя, но ту же самую форму представления данных, что и предикаты динамической БД. Добавление латинской буквы d к имени предиката статической БД - обычный способ различать предикаты динамической и статической БД.
Следует отметить два ограничения, объявленные в разделе facts :
• в динамической базе данных Пролога могут содержаться только факты;
• факты базы данных не могут содержать свободные переменные.
Допускается наличие нескольких разделов facts , тогда в описании каждого раздела facts нужно явно указать его имя, например facts – mydatabase. В двух различных разделах facts нельзя использовать одинаковые имена предикатов. Также нельзя использовать одинаковые имена предикатов в разделах facts и predicates. Если имя базы данных не указывается, то ей присваивается стандартное имя dbasedom. Программа может содержать локальные безымянные разделы фактов, если она состоит из единственного модуля, который не объявлен как часть проекта. Среда разработки компилирует программный файл как единственный модуль только при использовании утилиты TestGoal. Иначе безымянный раздел фактов должен быть объявлен глобальным, то есть как global facts.
В Прологе есть специальные встроенные предикаты для работы с динамической базой данных: assert; asserta; assertz; retract; retractall; save; consult.
Предикаты assert, asserta, assertz, - позволяют занести факт в БД, а предикаты retract, retractall - удалить из нее уже имеющийся факт. Предикат assert заносит новый факт в БД в произвольное место, предикат asserta добавляет новый факт перед всеми уже внесенными фактами данного предиката, assertz добавляет новый факт после всех фактов данного предиката. Предикат retract удаляет из БД первый факт, который сопоставляется с заданным фактом, предикат retractall удаляет из БД все факты, которые сопоставляются с заданным фактом. Предикат save записывает все факты динамической БД в текстовый файл на диск, причем в каждую строку файла заносится один факт. Если файл с заданным именем уже существует, то старый файл будет затерт. Предикат consult записывает в динамическую БД факты, считанные из текстового файла, при этом факты из файла дописываются в имеющуюся БД.
Факты, содержащиеся в текстовом файле должны быть описаны в разделе
domains.
Пример : Написать программу, генерирующую множество 4-разрядных двоичных чисел и записывающих их в динамическую БД.
facts
dbin (byte, byte, byte, byte)
predicates
cifra (byte)
bin (byte, byte, byte, byte)
clauses
cifra (0).
cifra (1).
bin (A, B, C, D):- cifra (A), cifra (B), cifra (C), cifra (D),
assert (bin (A, B, C, D)).
goal
bin (A, B, C, D).
Пример: Написать программу, подсчитывающую число обращений к программе.
facts
dcount (word)
predicates
modcount
clauses
dcount (0).
modcount:- dcount (N), M=N+1, retract (dcount (N)),asserta (dcount (M)).
goal
modcount.
38. Представление знаний в Visual Prolog..
В рамках направления "Представление знаний" решаются задачи, связанные с формализацией и представлением знаний в памяти интеллектуальной системы (ИС). Для этого разрабатываются специальные модели представления знаний и языки для описания знаний, выделяются различные типы знаний. Изучаются источники, из которых ИС может черпать знания, и создаются процедуры и приемы, с помощью которых возможно приобретение знаний для ИС. Проблема представления знаний для ИС чрезвычайно актуальна, т.к. ИС - это система, функционирование которой опирается на знания о проблемной области, которые хранятся в ее памяти.
Формы представления знаний.
Невозможно создать универсальный язык, удовлетворяющий всем требованиям одновременно. В практике решаются задачи ИИ:
Логические.
Семантические сети.
Фреймы.
Системы продукции.
Реляционные.
Основное назначение— формальное описание предметной области с целью возможности применения механизмов вывода из этого описания новых сведений.
1) Может быть описана четверкой (T, P, A, F).
Т— множество базовых элементов.
Р— множество исходных истинных утверждений.
А— множество синтаксических правил построения выражений из Т.
F— множество правил вывода.
В рамках логической модели существуют разделы:
Логика высказываний.
Исчисление высказываний.
Логика предикатов.
Исчисление предикатов.
1. Базовые понятия:
Высказывание— некоторое утверждение (истинное или ложное). Высказывание является элементарным неделимым понятием, в нем рассматривается свойство быть истинным или ложным. Обозначение: А, В, С. Ложь—0, 1— истина. Из простых высказываний могут быть образованы сложные высказывания с помощью логических операций: ¬, , , , и др. Для описания сложных высказываний используются формулы— выражения, построенные из логических переменных, логических констант и логических операций. Выводится индуктивно. Формула в некоторой интерпретации истинна, а в некоторой— ложна.
Приписывание логическим переменным истинного или ложного значения— интерпретация. Число интерпретаций— 2?, где n- число логических переменных. Формула, принимающая значение ложь для всех интерпретаций— тождественная ложь или противоречие.
Тавтология— тождественная истина. Формула, имеющая одну единственную интерпретацию называется выполнимой. Тождественно истинные формулы выражают логические законы.
Пример: формализации. "Если станок закончит работу, робот грузит кассету с деталями на робокар, который перевозит ее на склад, где их укладывает штабелер".
А1— станок закончил работу.
А2— робот грузит.
А3—робокар перевозит кассету на склад.
А4— штабелер укладывает.
Если, то: А1А2А3А4.
Законы (лобовое доказательство— перебор интерпретаций):
АВВА
(АВ) отрицаниеА отрицаниеВ отрицание.
(АВ) отрицаниеА отрицаниеВ отрицание.
ААВА
А(АВ)А
А (ВС)АВАС
АВС(АВ) (АС)
АВА отрицаниеВ
АВ(АВ) (ВА)
ААА
ААА
Этапы:
А) АС
В) СВ
С) А
Д) В
Вопрос: истинно ли С?
А, В, С, D— К.
АВСDК, если для всех интерпретаций АВСD=1. Тогда К следует.
22.09.2000 ¹4.
A=>Bне АB; не (A1A2…An)B=не A1не A2…не AnB.
Не (A1A2…An=>B)— тождественно ложная формула, тогда
A1A2…Anне B.
35 Встроенные предикаты.
Именем отношения между объектами является ПРЕДИКАТ. Например: name_predicates(О1,О2, .. ,ОN).
Это имя, которое записывается перед круглыми скобками. Вся запись типа name(O1,O2,..,O3) называется предикатной структурой или предикатным термом.
ТЕРМ - единообразная структура для описания данных и предикатов на языке Пролог.
Все встроенные предикаты из системной библиотеки и предикаты-процедуры, созданные при помощи других языков программирования и скомпонованные в единый рабочий модуль, выполняются как детерминированные.
Встроенные предикаты выполняют стандартных функций в других языках. Такие предикаты не нужно объявлять в разделе predicates.
Встроенные предикаты предоставляют возможности, которые нельзя реализовать с помощью описаний на чистом Прологе. Они также могут предоставлять удобные средства, избавляя программиста от необходимости самому определять эти предикаты. Примеры встроенных предикатов – предикаты для ввода и вывода, оператор cut (!), fail, и not.
Предикаты для ввода-вывода показывают, что встроенные предикаты могут иметь «побочные эффекты». Это значит, что при доказательстве согласованности целевого утверждения, содержащего такой предикат, помимо конкретизации аргументов предиката могут возникнуть дополнительные изменения. Это, естественно, не может случиться с предикатами, определенными на чистом Прологе. Другой важный факт, касающийся встроенных предикатов, состоит в том, что они могут быть определены только для аргументов конкретного вида. Например, рассмотрим предикат '‹' определенный таким образом, что Х‹Y выполняется, если число X меньше, чем число Y . Подобное отношение не может быть определено в Прологе без помощи посторонних средств, использующих некоторые знания о числах. Таким образом, ‹ – это встроенный предикат, а его определение использует некоторые операции вычислительной машины, на которой реализована Пролог-система, для определения относительной величины чисел.
Хотя основные средства механизма выполнения программ в большинстве Пролог-систем действуют одинаково, специальные встроенные предикаты могут все-таки различаться. Иногда это выражается в том, что для тех возможностей, которые легко обеспечить на данной ЭВМ, вводятся дополнительные предикаты. Иногда одни и те же основные возможности реализуются с помощью предикатов, которые дают несколько отличающиеся результаты. Например, для любой Пролог-системы было бы достаточно располагать предикатами functor и arg или предикатом '=..'. Действительно, первые два могут быть выражены через третий и обратно. Некоторые Пролог-системы могут предоставлять библиотеки полезных программ, обеспечивающих дополнительные возможности сверх тех, что дают встроенные предикаты.
39. Создание экспертной системы в Visual Prolog.
Экспертные системы (ЭС) – это сложные программные комплексы, аккумулирующие знания специалистов в конкретных предметных областях и тиражирующие этот эмпирический опыт для консультаций менее квалифицированных пользователей.
Построим небольшую экспертную систему, которая будет определять одну из нескольких рыб по признакам, указанным пользователем. Система будет задавать вопросы и строить логические выводы на основе полученных ответов.
Первым шагом построения такой системы является обеспечение ее знаниями, необходимыми для выполнения рассуждений. Программа должна во время консультаций выводить заключения из информации, имеющейся в базе знаний, а также использовать новую информацию, полученную от пользователя. Поэтому минимальная ЭС должна включать:
- базу знаний;
- механизм вывода;
- пользовательский интерфейс.
Разработку любой ЭС следует начать с исследования предметной области. Пусть на основе бесед с экспертом были получены следующие эмпирические правила:
Для хранения информации, полученной от пользователя, используются предикаты yes и no, составляющие внутреннюю базу фактов. Предикат yes служит для хранения фактов, соответствующих положительному ответу, а предикат no – для хранения отрицательных ответов. Т.е. предикат yes утверждает наличие какого-либо признака у рыбы, а no – отсутствие указанного признака. Эти предикаты объявляются в разделе внутренней базы фактов:
Добавить новые факты во внутреннюю базу можно с помощью правила add_to_database, состоящего из двух частей. Первая часть добавляет факты, соответствующие положительному ответу (с клавиатуры вводится ‘y’). Вторая часть правила добавляет факты, указывающие на отсутствие данного признака у рыбы.
Путеводитель
Представление знаний. Исчисление высказываний.
Модели представление знаний.
Логическая модель.
Выводы в логике высказываний. Принцип резолюций.
Исчисление предикатов. Метод резолюции.
Извлечение результата на основе метода резолюции.
Унификация. Процедура нахождения решения.
Семантическая модель. Типы объектов.
Семантическая модель. Фундаментальные отношения.
Сценарии. Фреймовая модель.
Продукционная модель знаний.
Методы поиска решений в продукционной модели.
Знания. Data Mining и Knowledge in DB.
Классы систем Data Mining.
Нечеткие множества. Основные определения.
Нечеткие множества. Основные операции.
Нечеткие числа. Основные определения и операции.
Нечеткие отношения. Основные определения и операции.
Лингвистическая переменная. Основные определения и операции.
Структурная схема нечеткой системы. Фаззификация. Нечеткий вывод.
Нейронные сети. Основные понятия.
Правила обучения. Сети с обратным распространением ошибки.
Архитектура и назначение многослойных нейронных сетей.
Самоорганизующаяся сеть Кохонена: назначение и алгоритм.
Методы кластеризации. Алгоритм четкой кластеризации.
Методы кластеризации. Алгоритм нечеткой кластеризации.
Генетические алгоритмы.
Структурная схема экспертной системы.
Нейронные сети. Основные понятия.
Структура программы Visual Prolog.
Правила в Visual Prolog.
Цель Visual Prolog. Представление целей.
Структура программы в Visual Prolog.
Рекурсия.
Встроенные предикаты.
способы представления баз данных в Visual Prolog.
Динамическая база данных.
Представление знаний в Visual Prolog..
Создание экспертной системы в Visual Prolog.
. Інструментальні засоби розробки систем штучного інтелекту.
36. Способы представления баз данных в Visual Prolog.
База данных программы может быть явной (состоит из фактов, аргументами которых являются константы) или неявной (описывается правилом с использованием переменных, значения которых зависят от подцелей тела этого правила).
Существует несколько способов представления баз данных в языке Пролог. Рассмотрим наиболее распространенные из них.
Представление целостных информационных элементов в виде множества фактов.
Простейший способ - множество фактов, каждый из которых соответствует целостному информационному элементу (записи) базы данных. Например служащих компьютерной фирмы:
% имя отдел должность оклад
служащий_1 (борис, 100, программист, 2000).
Представление атрибутов в виде фактов.
В качестве фактов можно использовать отдельные атрибуты (свойства) элементов. При необходимости данные атрибуты можно собрать в единое целое при помощи правила. Один из атрибутов должен быть ключом, объединяющим все остальные свойства объекта. Для базы данных “служащий_1” в качестве ключа можно использовать атрибут “имя ”. Первую запись базы можно представить так:
отдел (борис, 100).
должность (борис, программист).
зарплата (борис, 2000).
Все атрибуты служащего можно объединить с помощью правила:
служащий_2 (Имя, Отдел, Должность, Зарплата):-
отдел (Имя, Отдел),
должность (Имя, Должность),
зарплата (Имя, Зарплата).
Применение атрибутов является более гибким средством представления базы данных, чем применение целостных информационных элементов, поскольку новые атрибуты можно прибавлять без перезаписи заново всей существующей базы данных.
6.3. Представление в виде списка структур.
каждый элемент списка – это целостный информационный элемент:
% имя отдел должность оклад
[ служащий (борис, 100, программист, 2000),
служащий (надежда, 200, редактор, 7100),
служащий (олег, 100, менеджер, 7150) ] .
При таком подходе к структуре базы данных поток целостных информационных элементов не нужно включать в текущую программу, т.к. он может существовать как аргумент запроса, который входит в различные подцели, обрабатывающие этот поток.
Динамическая база данных.
Предикаты,
описывающие внутреннюю базу данных,
объявляются в разделе FACTS
(DATABASE)
и используются так же, как предикаты,
объявленные в разделе PREDICATES.
Система имеет набор встроенных
предикатов, предназначенных для работы
с внутренними базами фактов. Например,
для добавления новых фактов в базу
данных
Обработка фактов, принадлежащих к динамической базе данных, отличается от обработки предикатов, объявленных в разделе PREDICATES: факты внутренней базы данных хранятся в таблицах, что упрощает их модификацию, в то время как обычные предикаты для обеспечения максимального быстродействия компилируются в двоичный код.
DATABASE - моя_база_данных
первое_отношение(integer)
второе_отношение(real, string)
третье_отношение(string)
/* и т. д. */