

Квантитативное изучение разных уровней языка
Квантитативное изучение фонетики
При квантитативном исследовании лексико-фонетических групп ставится задача выявить особенности количественного распределения слов по их фонетическому строению (по началу и концу слова, по фоно- и графемо-тактике, по моделям дистрибуции звуков, фонем и графем, по длине слова) с учетом взаимосвязи с другими подуровнями лексики.
Знание особенностей строения слова с точки зрения его начала и конца важно не только для изучения типологии языков, но и для решения вопросов автоматической обработки текстов. Буквенный состав концов слов, коррелирующий с грамматическими признаками, помогает определению классов слов и, в конечном счете, выведению формальной модели языка. Слово может иметь разные типы звуковой структуры, состоящей из соотношения согласных и гласных. В типологических исследованиях часто обращаются к канонической форме, чтобы можно было на более общей основе проводить сопоставительный анализ структуры слова разных языков.
C – CONSANANT, V – VOWEL. Структуры слогов, слева направо – от самых часто распространенных к наиболее нераспространенным.
Русский |
CVC |
CCVC |
CVCC |
CCVCC |
CV |
Немецкий |
CVC |
CVCC |
CCVC |
CCVCC |
CV |
Английский |
CVC |
CVCC |
CCVC |
CV |
CCVCC |
Казахский |
CVC |
VC |
CVCC |
CV |
VCC |
Турецкий |
CVC |
CVCC |
VC |
- |
- |
Венгерский |
CVC |
CVCC |
VC |
- |
- |
Эстонский |
CVC |
CVCC |
CV |
CCVC |
CVCCC |
В тексте распределение частот таких структур может сильно различаться со словарным распределением. В русском языке 80% составляют слоги со структурой: CV, CVC, VC, CVCC.
Интерес может представлять также квантитативное определение степени симметричности системы фонетических структур слов. Система симметрична, если зеркальная структура встречается одинаково часто (VC-CV, VCC-CCV, CCVC-CVCC, CCVCC – автосимметричная структура). Симметричность увеличивается, если сами структуры сами собой автосимметричны. Такие структуры покрывают в немецком языке около 40% всего словаря, в русском – около 45%.
Важным количественным показателем структуры текста и его словаря является длина слова и распределение по длине слов в тексте и в словаре. Длина представляет собой систему образующий фактор, определяющий условие разбиения лексики на группы слов разной формационной структуры. Также распределение слов по длине указывает на статистическую взаимосвязь между словами разной длины в процессе порождения речи. Опыт показывает, что средняя длина словоформы и распределение по длине в тексте и словаре существенно различаются. Для английского языка средняя длина слова в тексте составляет 4,74 буквы; в словаре – 8,13. Короткие словоформы (до 4 букв) покрывают 35% английского текста. В словаре – всего 4% таких слов.
Средняя длина словоформы варьируется в зависимости от стиля текста. В художественной прозе средняя длина – 4,8 буквы; в научно-технической литературе – 7,1 буквы.
Опытным путем установлено, что распределение словоформ по длине в словаре хорошо выражается через лого-нормальное распределение.
Примеры лого-нормального распределения.


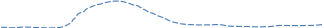
Это свойство длины слова отвечает принципам оптимального кодирования информации и отражает стремление к ясному и безошибочному различению слов.
Лого-нормальное распределение означает также, что выбор слова определенной длины при порождении речи зависит в некоторой степени от длины предшествующего слова. Благодаря этому в тексте чередуются длинные, короткие и средние по длине слова. Измерение длины слова в слогах имеет значение при выявлении так называемой «глубины слова». Эти данные используются в педагогике, стилистике, психолингвистике, в типологических исследованиях языков.
Особенно ярко проявляется дифференциация языков при сравнении словоформ по длине в тексте. Например, односложные словоформы в английском языке покрываются 66,8% английского текста; в русском – 33%; в турецком – 18,8%.
66
%


20

20
20
Длина слова

20
20
20
20
Существует закономерная связь между числом слогов и числом звуков в слове. С удлинение словоформы отношение числа звуков к числу слогов уменьшается, т.е. чем длиннее слово, тем короче слоги в нем. Закономерность вывел лингвист Мендцерат. Тот факт, что короткие слова более частотны, чем длинные, свидетельствует о действии принципа экономии в процессе коммуникации. Французский ученый П. Гиро сформулировал закономерность, согласно которой для каждого языка можно определить константу «С», указывающую на связь между длиной слова «Х» и его рангом в частотном списке «i».
Закономерность: С = lg2i/X.
Зависимость между длиной слова и его частотой является взаимной, однако можно утверждать, что решающую роль играет частота употребления, т.е. если частотность слова возрастает, то слово часто подвергается редукции. Пример, ретроспективный – в стиле ретро; кинотеатр – кино; университет – универ.
Квантитативное изучения словообразования и морфология
План:
Основные проблемы квантитативного изучения словообразования и морфологии
Классификация лексики по словообразовательной структуре
Количественная оценка словообразовательных классов слов
Квантитативное исследование словообразовательных гнезд
Типологическая классификация языков на основе морфологических признаков. Количественные критерии типологии
Типы морфемного устройства слова и их количественная оценка
1.
При квантитативном изучение словообразования и морфологии решаются следующие проблемы:
- возможность классификации лексики на основе грамматических признаков;
- выявление закономерности и распределения полученных классов (лексических групп) в словаре и в тексте;
- выделение лексико-формационных групп по признаку морфемного строения слова;
- типологическая классификация языков мира на основе способов выражения грамматических значений.
2.
Типы классификации. Наиболее общий способ классификации слов по словообразовательной структуре – это их распределение по основным структурным типам: корневые (корень, корень + окончание), производные простые слова (корень + словообразовательный аффикс), производные сложные слова (два и более корней).
Количественное распределение лексики разных языков на основе словаря (парадигматическом уровне).
Табл. «Распределение слов по словообразовательной структуре в словаре различных языках»
|
Русский |
Английский |
Немецкий |
Эстонский |
Корневые |
13% |
18% |
5% |
5% |
Простые производные |
79% |
69% |
9% |
35% |
Сложные производные |
8% |
15% |
83% |
60% |
Табл. «Распределение слов по словообразовательной структуре в текстах»
|
Русский |
Английский |
Немецкий |
Эстонский |
Корневые |
81% |
75% |
70% |
67% |
Простые производные |
16% |
23% |
18% |
13% |
Сложные производные |
3% |
2% |
12% |
20% |
Джозеф Гринберг предложил использовать индексы, выражающие отношения количества определенного типа морфем к количеству слов текста. Данный индекс получил название индекс словосложения. Он показывает отношение числа корневых морфем к числу слов текста – Y=R/W.
Получены следующие индексы для разных языков:
В русском – 1,03. На 100 слов встречается 3 сложных слова.
В английский – 1,02.
В немецком – 1,12.
В швецком – 1,13.
В венгерском – 1,21,
Словообразовательный класс определяется списком суффиксов при сочетании суффиксов, совместимых со словообразовательной основой слова. В русском обнаружено около 1250 словообразовательных классов. 10 наиболее частотных охватывает около 60% всех слов русского языка.
Здесь применяется принцип концентрации языковых единиц, который приводит к образованию ядра и периферии распределения языковых объектов.
Пример (самые частые 3 класса):
- нулевой суффикс – суффикс «н».
- нулевой суффикс – «о» – «ост»: слабый – слабо – слабость.
- нулевой суффикс – «ов»: порт – портов.
Один из самых редких: нулевой суффикс – «б» (ходить – ходьба, стрелять – стрельба).
Распределение производных слов по их словообразовательным формантам позволяет выявить наиболее продуктивные и употребительные типы слов.
Количество словоформ на 100 000 слов:
- ный/ной – 9800 слов;
- ость – 3500;
- ние/ие – 3200;
- ка/очка – 3000;
- ский/ской – 2700.
Наиболее частотные форманты в английском языке (на 100 000 слов)
|
Частота в словаре (Fc) |
Частота в тексте (Fт) |
Fc/Fт |
|
186 |
3650 |
19.6 |
|
296 |
4991 |
16.9 |
- ion (noun) |
794 |
12772 |
16.1 |
|
183 |
3486 |
16 |
|
396 |
4691 |
15.9 |
Отношение частотности в тексте к частотности в соответствующем словаре выражает функциональную значимость (нагрузку) рассматриваемого типа производных слов. Чем больше это отношение, тем больше повторяются слова с данным формантов в тексте, но тем меньше их относительное разнообразие.
Квантитативное исследование гнезд подразумевает выделение словообразовательного потенциала отдельных корней, т.е. способности слова быть производящей основой. Для английского языка самый распространенный корень –time (более 100 производных слов). Для русского – -бить (446 слов), -брать (393), -делать (318); -вода (316), -свет (306), -земля (216); -белый (246), -черный (236), -старый (192).
На основе оценки словообразовательного потенциала можно судить о квантитативной структуре словообразовательных гнезд, также можно классифицировать лексику какого-либо языка. Существует статистическая зависимость между оценкой словообразовательного потенциала и частотностью производящих слов, а именно наиболее частотные слова обладают, в среднем, наивысшей оценкой словообразовательного потенциала.
5.
На основе способов выражения грамматических значений в первой половине 20 века была разработана морфологическая типологическая классификация языков.
Основным в данной классификации является индекс синтетичности языка, который вычисляется по формуле Y=M (количество морфоф)/W (количество слов).
Традиционной считается следующая классификация языков:
Изолирующие = аморфные языки. Величина индекса в таких языках – 1-1,5. Грамматические значения определяются служебными словами, порядком слов в предложении или интонацией. Соответственно, в таких языках одно и то же слово может обозначать как предмет, так свойства или действия, в зависимости от контекста. Вьетнамский – 1,06; китайский – 1,21. Пример: Nqua (человек) lám (делать) ruong (земля) tot (хороший). В зависимости от интонации можно различить 4 разных смысла.
Аналитические языки. Величина индекса – 1,5-2. В таких языках аналитические способы выражения грамматических значений преобладают. Пример: It’s getting dark – is (время), it (безличность), dark (прилагательное). Персидский (фарси) – 1,52; в английском – 1,68; голландский (фламандский) – 1,81; датский – 1,98.
Синтетические языки. Величина индекса – 2-3. В таких языках синтетические способы преобладают при выражении грамматических значений. Пример: Кошка (3) запрыгнула на бабушкино кресло – 13 синтетических, 1 аналитический способ. Немецкий язык – 2,02; швецкий – 2,13; эстонский – 2,35; русский – 2,45; санскрит – 2,59.
Полисинтетические = инкорпорирующие языки. Индекс синтетичности – выше 3-х. В таких языках отношения между действием, объектом, субъектом, обстоятельствами выражается не через члены предложения, а через морфы. Таким образом, в этих языках предложения чаще всего равняется к слову, а грамматические значения выражаются единожды в рамках такого предложения слова.
Пример: unikw (огонь) – ihl (дом) – minih (мн.ч.) – is (уменьшаться) – it (пр. вр.) – a (изъявит. наклонение).
К полисинтетическим языкам относятся индейцев Америки и чукотско-камчатские языки. В эскимосском языке индекс синтетичности равен 3,72.
6.
Синтетические и полисинтетические языки делятся на типы по признаку преимущественного использования различных типов аффиксальных морфем. В рамках аффиксации различают две противоположные тенденции: фузионная и агглютинативная.
Фузия – тип морфемного устройства слова, при котором границы между морфемами слова не отчетливы, иногда они проходят внутри слова, иногда некоторые части морфем не просматриваются. Пример: стричь – стр + и + чь (стриг + ть – исторически); принять и взять (исторический общий корень –ять). При этом одна морфема может выражать несколько грамматических значений. Пример: собака (окончание «а» – ж. р., ед. ч., Им. п.)
Агглютинация – тип морфемного устройства слова, при котором границы между морфемами отчетливы, определяется однозначно, а также одна морфема выражает одно значение и наоборот. Пример: китоб-лар-им-да (узбекский язык); китоб – книга, лар – мн. ч., им – притяжательность, да – предлог «в»: «в моих книгах».
Мера агглютинативности языков определяется на основе индекса агглютинации: J = A/S (А – количество агглютинативных конструкций в отрезке текста, т.е. морфом, обладающих единственным значением, только аффиксы; S – количество морфемных швов, т.е. границ между морфемами).
В русском языке фузионный. Пример: «Пойдем-ка поговорим с братом». Индекс – 1/6, агглютинативная конструкция «ка», 6 границ между всеми морфемами.
Индексы: английский – 0,3; англосаксонский – 0,11; санскрит – 0,09; эскимосский – 0,036.