

12. Numa-мультипроцессоры
NUMA- мультипроцессоры с неодно-
родным доступом к памяти (NonUniform Memory Access, NUMA). Как и UMA-
мультипроцессоры, они предоставляют единое адресное пространство для всех
процессоров, но, в отличие от UMA-машин, доступ к локальным модулям памя-
ти происходит быстрее, чем к удаленным. Следовательно, все UMA-программы
смогут без изменений работать на NUMA-машинах, но производительность бу-
дет хуже, чем на UMA-машине с той же тактовой частотой.
NUMA-машины имеют три ключевые характеристики, которые в совокупно-
сти отличают их от других мультипроцессоров:
♦ существует единое адресное пространство, видимое всеми процессорами;
+ доступ к удаленной памяти производится командами LOAD и STORE;
+ доступ к удаленной памяти выполняется медленнее, чем доступ к локаль-
ной.
Если время доступа к удаленной памяти не замаскировано кэшированием (кэш
отсутствует), такая система называется NC-NUMA (No Caching NUMA —
NUMA без кэширования). Если присутствуют согласованные кэши, то система
называется CC-NUMA (Coherent Cache NUMA — NUMA с согласованными кэ-
шами). Программисты часто называют такую систему аппаратной распределен-
ной общей памятью, поскольку она, по сути, аналогична распределенной общей
памяти (DSM), реализованной программно, однако поддерживается аппаратно
с использованием страниц маленького размера.
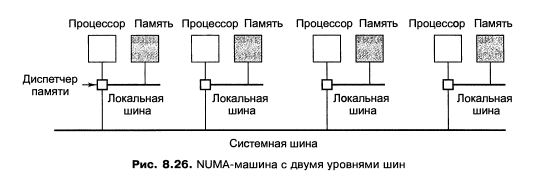
Рис. 8.26. NUMA-машина с двумя уровнями шин
Согласованность памяти в NC-NUMA-машине гарантирована, поскольку в ней
отсутствует кэш-память. Каждое слово памяти может находиться только в одном
месте, поэтому нет никакой опасности появления копии с устаревшими данны-
ми — здесь вообще нет копий. То, в каком именно модуле памяти находится та
или иная страница, имеет большое значение, поскольку от этого зависит произ-
водительность.
13. Мультикомпьютеры mpp и cow (now).
Мультикомпьютеры тоже можно разделить на две дополнительные категории.
К категории МРР (Massively Parallel Processor — процессор с массовым парал-
лелизмом) относятся дорогостоящие суперкомпьютеры, которые состоят из
большого количества процессоров, связанных высокоскоростной внутренней
коммуникационной сетью. В качестве хорошо известного коммерческого приме-
ра можно назвать суперкомпьютер SP/3 компании IBM.
Вторая категория мультикомпьютеров включает обычные персональные
компьютеры или рабочие станции (иногда смонтированные в стойки), которые
связываются в соответствии с той или иной коммерческой коммуникационной
технологией. С точки зрения логики принципиальной разницы здесь нет, но
мощный суперкомпьютер стоимостью в миллионы долларов безусловно исполь-
зуется иначе, чем собранная конечными пользователями компьютерная сеть,
которая обходится во много раз дешевле любой МРР-машины. Эти «доморощен-
ные» системы иногда называют сетями рабочих станций (Network Of Work-
stations, NOW), кластерами рабочих станций (Cluster Of Workstattions, COW),
или просто кластерами (cluster).
14. Топология коммуникационных сетей мультикомпьютеров
Топология коммуникационной сети определяет схему размещения линий связи
и коммутаторов . Топологию сетей принято изображать в виде графов, в которых дуги соответствуют линиям связи, а узлы — коммутаторам
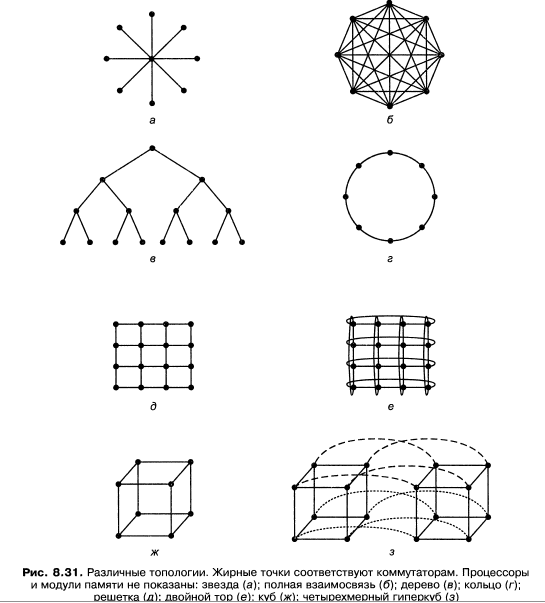
Коммуникационные сети можно характеризовать по их размерности. Размер-
ность определяется числом возможных вариантов перехода от источника к при-
емнику.
Здесь изображены только линии связи и коммутаторы (в виде точек). Модули памяти и процессоры (они на ри- сунке не показаны) соединяются с коммутаторами через интерфейсы.
А) изображена нульмерная конфигурация звезда, в которой процессоры
и модули памяти подключаются к внешним узлам, а переключение совершает
центральный узел. Такая схема очень проста, но в большой системе центральный
коммутатор окажется узким местом системы. С точки зрения отказоустойчиво-
сти это тоже очень неудачная схема, поскольку отказ одного центрального ком-
мутатора вызывает крах всей системы.
Б) изображена другая нульмерная топология — полная взаимо-
связь. Здесь каждый узел непосредственно связан со всеми остальными. В такой
схеме пропускная способность сечения максимальна, диаметр минимален, а от-
казоустойчивость очень высока (даже при утрате шести линий связи система все
равно остается полносвязной). Однако для k узлов требуется k(k - l)/2 каналов,
а это совершенно неприемлемо для больших значений k.
В) дерево - Здесь основная проблема со-
стоит в том, что пропускная способность сечения равна пропускной способности
линии связи. Обычно основной трафик наблюдается у верхушки дерева, поэтому
верхние узлы становятся узким местом всей системы.
Г) Кольцо — это одномерная топология, поскольку каждый отправ-
ленный пакет может пойти направо или налево.
Д) Решетка, или сетка (рис. 8.31, д), — это двухмерная топология, которая применяется во многих коммерческих систе- мах. Она отличается регулярностью и легко масштабируется в сторону увеличе- ния, а ее диаметр составляет квадратный корень от числа узлов (то есть при мас- штабировании системы диаметр увеличивается незначительно).
Ё)Двойной тор является разновидностью решетки, у которой края соединены. Эта
топология характеризуется более высокой отказоустойчивостью и меньшим диа-
метром, чем обычная решетка, поскольку в ней между двумя противоположны-
ми узлами всего два хопа.
Ж) Куб (рис. 8.31, ж) — это регулярная трехмерная топология. На рисунке изо-
бражен куб размером 2 х 2 х 2, но в общем случае это может быть куб размером
k х k x к.
З) Четырехмерный куб, полученный из двух трехмерных кубов, которые связаны между собой. Можно сделать пятимерныйкуб, соединив вместе 4 четырехмерных куба. Чтобы получить 6 измерений, нуж- но продублировать блок из 4 кубов и соединить соответствующие узлы и т. д.
Гиперкубом называется гг-мерный куб (рис. 8.31, з). Эта топология используется
во многих параллельных компьютерных архитектурах, поскольку ее диаметр ли-
нейно зависит от размерности. Другими словами, диаметр — это логарифм по ос-
нованию 2 от числа узлов, поэтому 10-мерный гиперкуб имеет 1024 узла, но диа-
метр равен всего 10, что дает очень незначительные задержки при передаче
данных.