

4. Мультипроцессоры (системы с общей памятью).
Мультипроцессор — это подкласс многопроцессорных компьютерных систем, где есть несколько процессоров и одно адресное пространство, видимое для всех процессоров. В таксономии Флинна мультипроцессоры относятся к классу SM-MIMD-машин. Мультипроцессор запускает одну копию ОС с одним набором таблиц, в том числе тех, которые следят какие страницы памяти свободны.
По ролям, которые играют процессоры в мультипроцессорной системе, различают: симметричные мультипроцессоры (SMP) - все процессоры играют одинаковую роль и имеют одинаковый доступ к памяти и периферии, и асимметричные мультипроцессоры (AMP) - процессоры играют разные роли или по-разному обращаются к периферийным устройствам. Технология AMP была лишь переходной в 60-ых годах до того момента, когда была отработана технология SMP.
По способу адресации памяти различают несколько типов мультипроцессоров, среди которых: UMA (Uniform Memory Access), NUMA (Non Uniform Memory Access) и COMA (Cache Only Memory Access).
Помимо этого мультипроцессоры могут быть гомогенного типа, когда все процессоры в системе одинаковы, или гетерогенного типа - когда процессоры в системе разного типа.
5. Мультикомпьютеры (системы с распределенной памятью).
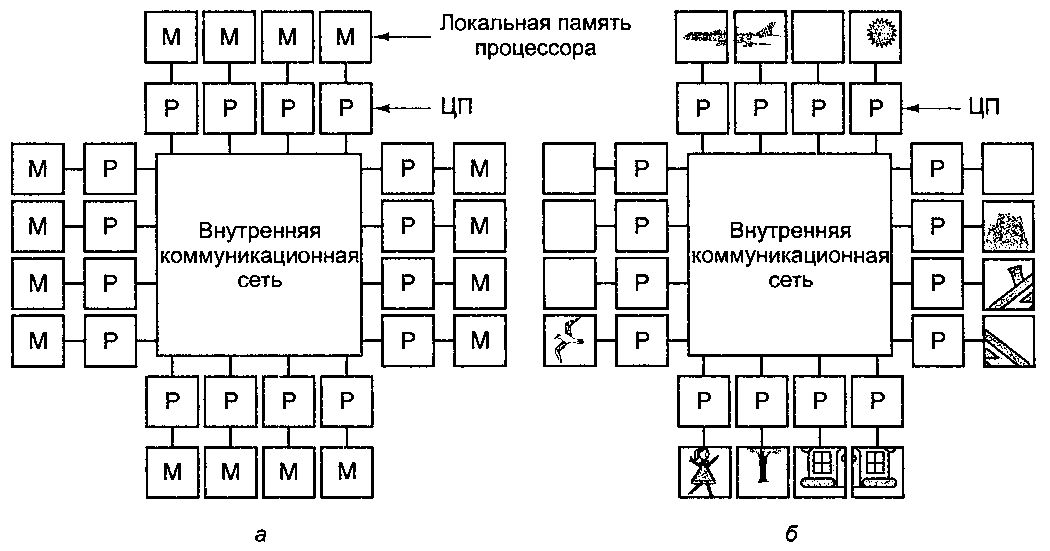
Каждый процессор имеет собственную память, доступную только этому процессору. Мультикомпьютеры содержат отдельные физические адресные пространства для каждого процессора. Поскольку процессоры в мультикомпьютере не могут взаимодействовать друг с другом простыми обращениями к общей памяти, процессоры обмениваются сообщениями через связывающую их коммуникационную сеть. При отсутствии общей памяти, реализованной аппаратно, предполагается определенная программная структура.
В мультикомпьютере для взаимодействия между процессорами часто используются примитивы send и receive. Поэтому программное обеспечение мультикомпьютера имеет более сложную структуру, чем программное обеспечение мультипроцессора. При этом основной проблемой становится правильное распределение данных и разумное их размещение.
Мультипроцессоры сложно разрабатывать, но легко программировать, а мультикомпьютеры легко строить, но трудно программировать. В результате постоянно предпринимаются попытки создания гибридных систем.
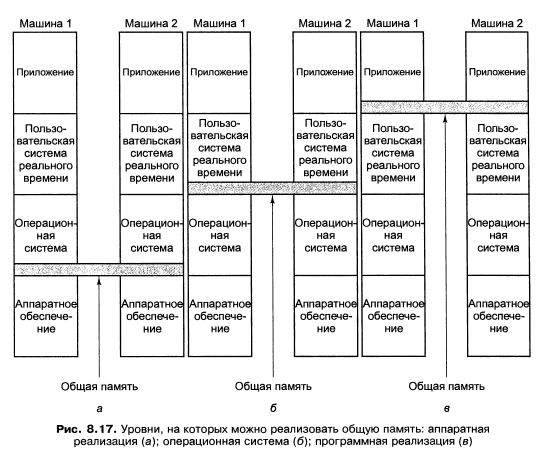
Один из подходов основан на том, что современные компьютерные системы не монолитны, а имеют многоуровневую структуру. Это дает возможность реализовать общую память на любом из нескольких уровней, как показано на рис. 8.17.
На рис. 8.17, а мы видим общую память, реализованную аппаратно, как в "настоящем" мультипроцессоре. В данной разработке имеется одна копия операционной системы с одним набором таблиц, в частности таблицей распределения памяти.
Второй подход - использовать аппаратное обеспечение мультикомпыотера и операционную систему, которая будет моделировать общую память, предоставляя единое виртуальное адресное пространство, разбитое на страницы. При таком подходе получается распределенная общая память (Distributed Shared Memory, DSM), в которой каждая страница расположена в одном из модулей памяти (см. рис. 8.16, б), а каждая машина содержит собственную виртуальную память и собственные таблицы страниц [127].
Третий
подход - реализовать общую память
программно пользовательской системой
реального времени. При таком подходе
абстракцию общей памяти создает язык
программирования, и эта абстракция
реализуется компилятором.
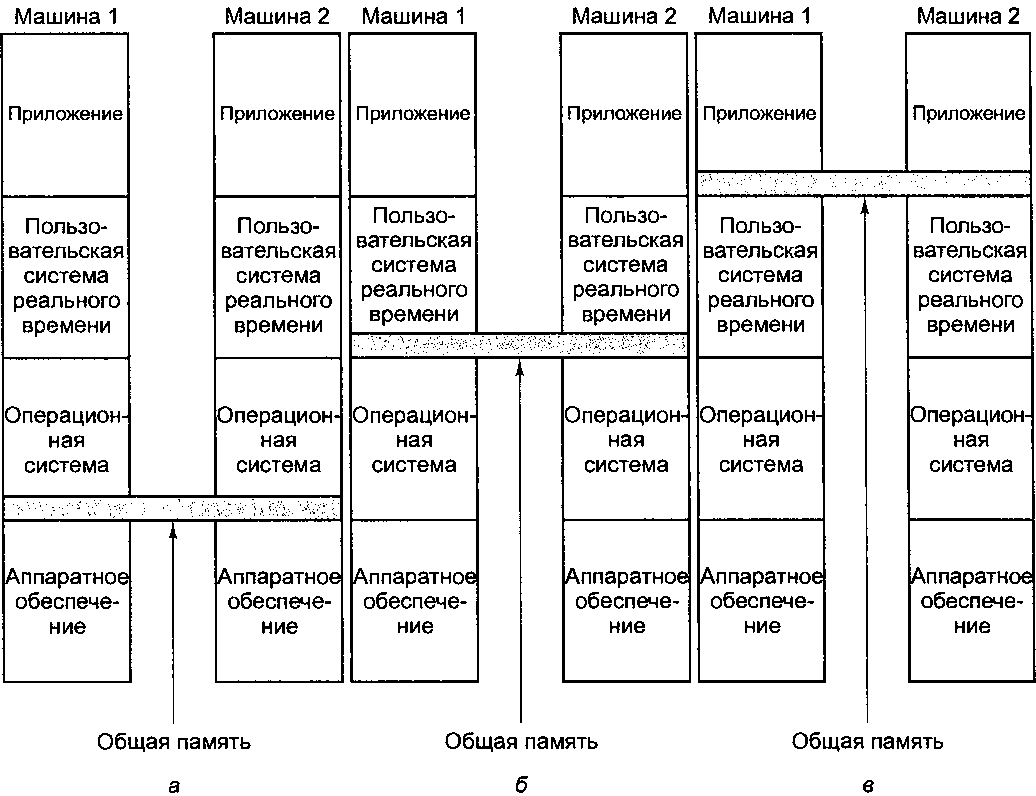
Рис. 8.17. Уровни, на которых можно реализовать общую память: аппаратная реализация (а); операционная система (б); программная реализация (в)
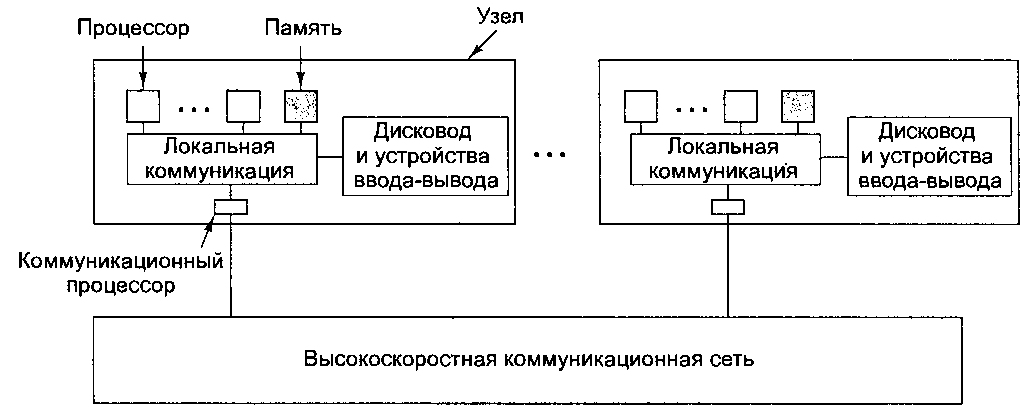
Каждый узел в мультикомпьютере состоит из одного или нескольких процессоров, ОЗУ (общего для процессоров только данного узла), дисковода и (или) других устройств ввода-вывода, а также коммуникационного процессора. Коммуникационные процессоры связаны между собой высокоскоростной коммуникационной сетью.
6. Способы реализации общей памяти в компьютерных системах как многоуровневых структурах.
Таненбаум 5-е издание 639 стр
7.Классификация параллельных компьютерных систем
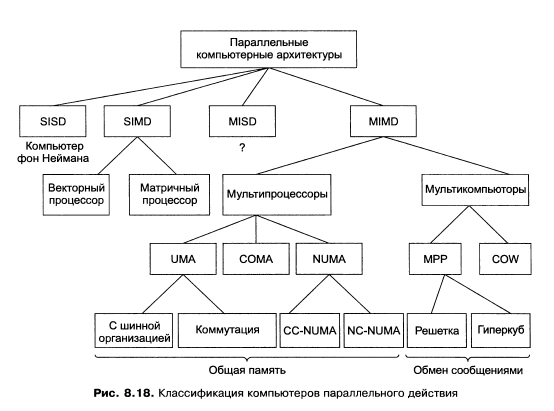
Таненбаум 5-е издание 641 стр
8. Отличительные признаки UMA-, NUMA- и COMA-мультипроцессоров
Существует три типа мультипроцессоров. Они отличаются друг от дру-
га механизмом доступа к общей памяти и называются UMA (Uniform Memory
Access — однородный доступ к памяти), NUMA (NonUniform Memory Access —
неоднородный доступ к памяти) и СОМА (Cache Only Memory Access — доступ
только к кэш-памяти). Такое разбиение на подкатегории имеет смысл, посколь-
ку в больших мультипроцессорах память обычно делится на несколько модулей.
В UMA-машинах каждый процессор имеет одно и то же время доступа к любому
модулю памяти. Иными словами, каждое слово может быть считано из памяти с
той же скоростью, что и любое другое слово. Если это технически невозможно,
самые быстрые обращения замедляются, чтобы соответствовать самым медлен-
ным, поэтому программист не заметит никакой разницы. Это и значит «однород-
ный» доступ. Такая однородность делает производительность предсказуемой,
а этот фактор очень важен для создания эффективных программ.
NUMA-машина, напротив, не обладает свойством однородности. Обычно у каж-
дого процессора есть один из модулей памяти, который располагается к нему
ближе, чем другие, поэтому доступ к этому модулю памяти происходит гораздо
быстрее, чем к другим. В этом случае с точки зрения производительности очень
важно, где окажутся программа и данные. Доступ к СОМА-машинам тоже ока-
зывается неоднородным, но по другой причине. Подробнее каждый из вариантов
мы рассмотрим позднее, когда будем изучать соответствующие подкатегории.
9. UMA-мультипроцессоры с общей шиной
Самые простые мультипроцессоры имеют всего одну шину (рис. 8.21, а). Два
или более процессора и один или несколько модулей памяти используют эту
шину для взаимодействия. Если процессору нужно считать слово из памяти, он
сначала проверяет, свободна ли шина. Если шина свободна, процессор помещает
адрес нужного слова на шину, устанавливает несколько управляющих сигналов
и ждет, когда память поместит на шину запрошенное слово.
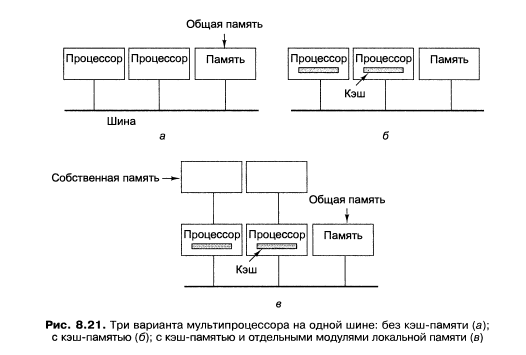
Если шина занята, процессор просто ждет, когда она освободится. С этой схе-
мой связана одна проблема. При наличии двух или трех процессоров доступ
к шине регулировать не сложно, трудности возникают, когда процессоров 32
или 64. Производительность системы в этом случае полностью определяется
пропускной способностью шины, и многим процессорам большую часть времени
приходится простаивать.
Чтобы разрешить проблему, нужно добавить к каждому процессору кэш-
память, как показано на рис. 8.21, б. Кэш-память может находиться внутри мик-
росхемы процессора, рядом с микросхемой процессора, на плате процессора.
Допустимы любые комбинации этих вариантов. Поскольку в этом случае считы-
вать многие слова можно будет из кэша, трафик на шине снизится, и система
сможет обслуживать большее количество процессоров. Таким образом, кэширо-
вание дает в данном случае значительный эффект.
В следующей схеме каждый процессор имеет не только кэш, но и собствен-
ную локальную память, к которой он получает доступ через выделенную локаль-
ную шину (рис. 8.21, в). Чтобы оптимально задействовать эту конфигурацию,
компилятор должен поместить в локальные модули памяти весь программный
код, строки, константы и другие данные, предназначенные только для чтения,
а также стеки и локальные переменные. Общая память потребуется только для
хранения совместно используемых переменных. В большинстве случаев такое
разумное распределение значительно снижает интенсивность трафика на шине
и не требует активного содействия со стороны компилятора.
10. UМА-мультипроцессоры с перекрестной коммутацией
Из-за наличия всего одной шины в ИМА-мультипроцессоре даже после оптимизации не может быть больше 16 или 32 процессоров. Чтобы процессоров стало больше, требуется другой тип коммуникационной сети. Самая простая схема соединения п процессоров с к блоками памяти - перекрестная коммутация
(рис. 8.23). Перекрестная коммутация на протяжении многих десятилетий используется в телефонных коммутаторах, позволяющих произвольным образом связывать группы входящих и исходящих линий.
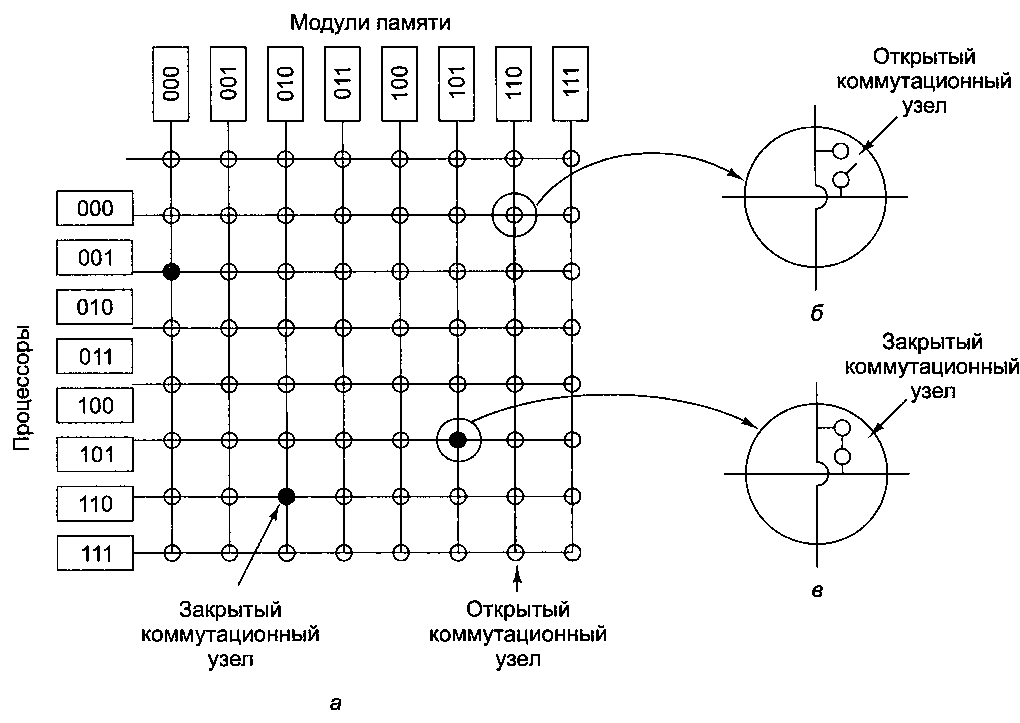
Рис. 8.23. Перекрестная коммутация 8x8 (а); открытый узел (б); закрытый узел (б)
На каждом пересечении горизонтальной (входящей) и вертикальной (исходящей) линии находится коммутационный узел (ш^ротт.), который можно открыть или закрыть в зависимости от того, нужно соединить горизонтальную и вертикальную линии или нет. На рис. 8.23, а мы видим, что три узла закрыты, благодаря чему одновременно устанавливается связь между следующими парами процессор-память (001, ООО), (101, 101) и (110, 010). Возможны и другие комбинации. Число комбинаций равно числу вариантов расстановки восьми ладей на шахматной доске так, чтобы ни одна из них не находилась под боем другой.
Одним из самых симпатичных свойств сети с перекрестной коммутацией является то, что она неблокирующая. Это означает, что процессор всегда сможет соединиться с нужным модулем памяти, даже если некоторые линии или узлы уже заняты (предполагается, что сам модуль памяти доступен). Более того, никакого предварительного планирования не требуется. Даже если уже установлено семь произвольных соединений, всегда можно соединить оставшийся процессор с оставшимся модулем памяти. Далее мы рассмотрим схемы взаимного соединения, которые не обладают такой возможностью.
Одним из худших свойств перекрестной коммутации является то, что число узлов растет как п2. Для средних по размеру систем перекрестная коммутация является хорошим решением, и далее в этой главе мы рассмотрим одно из таких решений - NUMA-мультипроцессор Sun Fire Е25К. Однако для 1000 процессоров и 1000 модулей памяти понадобится миллион узлов, что неприемлемо. Необходимо нечто совершенно иное.
11. UMA-мультипроцессоры с многоступенчатой коммутацией
В основе этого "совершенно иного" лежит небольшой коммутатор 2x2 (рис. 8.24, а) с двумя входами и двумя выходами. Сообщения, приходящие на любую из входных линий, могут переключаться на любую выходную линию. В нашем примере сообщения будут содержать до четырех частей (рис. 8.24, б). Поле модуля показывает, какой модуль памяти запрашивается. Поле адреса определяет адрес в этом модуле памяти. В поле кода операции указывается одна из доступных операций, например, READ или WRITE. Наконец, дополнительное поле значения может содержать операнд, например, 32-разрядное слово, которое нужно записать при выполнении операции WRITE. Коммутатор проверяет поле модуля и с его помощью определяет, через какую выходную линию нужно отправить сообщение: через X или через Y.

Рис. 8.24. Коммутатор 2x2 (а); формат сообщения (б)
Наши коммутаторы 2x2 можно компоновать различными способами и получать сети с многоступенчатой коммутацией. Один из возможных вариантов - сеть omega (рис. 8.25). Здесь 8 процессоров соединены с 8 модулями памяти через 12 коммутаторов. Для п процессоров и п модулей памяти понадобится log2n ступеней и п/2 коммутаторов на каждую ступень, то есть, всего (n/2)log2n коммутаторов, что намного меньше, чем п2 коммутационных узлов при перекрестной коммутации, особенно для больших значений п.
Схему разводки проводов сети omega часто называют полной перетасовкой (perfect shuffle), поскольку смешение сигналов на каждой ступени напоминает тасование колоды карт. Чтобы понять, как работает сеть omega, предположим, что процессору 011 нужно считать слово из модуля памяти 110. Процессор посылает сообщение READ, чтобы переключить коммутатор 1D, который содержит 110 в поле модуля. Коммутатор берет первый (то есть крайний левый) бит от 110 и по нему узнает направление (0 указывает на верхний выход, 1 - на нижний). Поскольку в данном случае этот бит равен 1, сообщение отправляется через нижний выход к коммутатору 2D.
Все коммутаторы второй ступени, включая 2D, для определения направления используют второй бит. В данном случае он равен 1, поэтому сообщение отправляется через нижний выход к коммутатору 3D, который проверяет третий бит. Он равен 0, следовательно, сообщение проходит через верхний выход и прибывает в модуль памяти 110, чего мы и добивались. Путь, пройденный сообщением, обозначен на рис. 8.25 буквой а.
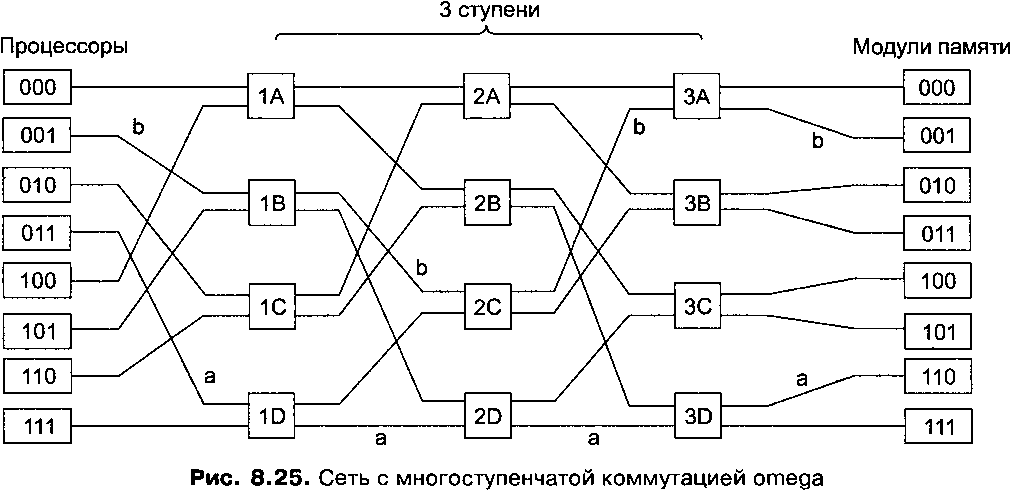
По мере прохождения через сеть сообщение поочередно перестает нуждаться во всех битах номера модуля, начиная с самого левого. Их можно использовать для записи номеров входных линий, чтобы было известно, по какому пути посылать ответ. Для пути а входные линии - это 0 (верхний вход в ID), 1 (нижний вход в 2D) и 1 (нижний вход в 3D) соответственно. Таким образом, при отправке ответа тоже используется последовательность 011, только прочтенная справа налево.Пусть в то время как все это происходит, процессор 001 тоже решает записать слово в модуль памяти 001. Здесь происходит аналогичный процесс. Сообщение отправляется через верхний, верхний и нижний выходы соответственно. На рис. 8.25 этот путь отмечен буквой Ъ. Когда сообщение прибывает в пункт назначения, в его поле модуля содержится последовательность 001, показывая путь, который прошло сообщение. Поскольку эти два запроса проходят через разные коммутаторы, линии и модули памяти, они могут выполняться параллельно.
А теперь посмотрим, что произошло бы, если бы процессору 000 понадобился доступ к модулю памяти 000. Его запрос вступил бы в конфликт с запросом процессора 001 на коммутаторе ЗА, и одному из них пришлось бы ждать. То есть, в отличие от сети с перекрестной коммутацией, сеть omega - это блокирующая сеть. Одновременно может передаваться не всякий набор запросов. Конфликты могут возникать как между запросами (при использовании одной и той же линии или одного и того же коммутатора), так и между запросами (к памяти) и ответами (из памяти).
Совершенно очевидно, что обращения к памяти желательно равномерно распределять по модулям памяти. Один из возможных способов - использовать младшие биты в качестве номера модуля. Рассмотрим адресное пространство с побайтовой адресацией для компьютера, которому в основном требуется доступ к 32-разрядным словам. Два младших бита обычно равны 00, но следующие три бита распределяются равномерно. Если задействовать эти три бита в качестве номера модуля памяти, последовательно адресуемые слова оказываются в последовательно расположенных модулях. Система памяти, в которой последовательные слова находятся в разных модулях памяти, называется расслоенной. Расслоенная память доводит параллелизм до абсолюта, поскольку большая часть обращений к памяти - это обращения по последовательным адресам. Возможна также разработка неблокирующих сетей, в которых для оптимизации трафика предлагаются несколько путей от каждого процессора к каждому модулю памяти.