

3. Принятие решений с использованием моделей массового обслуживания
3.1 Методы разработки математических моделей в смо
Трудности использования стандартных моделей, разработанных в ТМО, можно преодолеть одним из следующих способов. Во-первых, можно модифицировать структурно-функциональные характеристики обслуживающей системы так, чтобы чисто логическим путем достичь желательных операционных показателей этой системы и одновременно сделать рассматриваемую СМО поддающейся анализу одной из стандартных математических моделей. Во-вторых, можно признать справедливым некоторые упрощающие предположения относительно реальной обслуживающей системы и, следовательно, возможно представить ее с помощью математической модели без риска получить существенные ошибки в численных оценках операционных характеристик исследуемой системы. Второй из указанных способов представляет собой более перспективным, поскольку за счет его реализации увеличивается круг задач, решение которых может быть обеспеченно путем использования разработанных в ТМО математических моделей и методов.
3.2.Подготовка исходных данных и проверка статистических гипотез
Выбор того или иного метода для исследования функциональных характеристик обслуживающей системы независимо от того, является ли он аналитическим или же относится к категории имитационных, в каждом конкретном случае определяется законом распределения моментов поступления требований и продолжительностей обслуживания. Чтобы установить, какой характер имеют упомянутые выше распределения, необходимо осуществить наблюдения за реально функционирующей СМО и зарегистрировать ряд чисел, получаемых в ходе наблюдений. В связи с накоплением данных, характеризующих процесс массового обслуживания, как правило возникают следующие вопросы:
Когда осуществлять наблюдение за системой?
Каким образом систематизировать данные?
В большинстве случаев СМО характеризуются так называемыми периодами повышенной загруженности, когда интенсивность потока требований по сравнению с другими интервалами рабочего дня существенно возрастает. Отметим, например, что интенсивность потоков транспортных средств на магистральных автострадах при въезде в крупные города достигает пиковых значений в интервалах времени около 8 ч утра и 5ч вчера. В таких случаях сбор информации об исследуемом процессе необходимо осуществлять именно в периоды наибольшей загруженности. Можно расценить такую стратегию сбора данных как чрезмерно "консервативную"; однако следует помнить, что заторы на крупных автомагистралях возникает именно в течение периодов повышенной загруженности обслуживающей системы. Поэтому системы такого рода должны проектироваться с учетом тех экстремальных условий, которые могут возникнуть в процессе их функционирования.
Сбор данных о входном и выходных потоках в СМО может осуществляться одним из указанных ниже способов, а именно:
а) путем регистрации временных интервалов между последовательными поступлениями заявок на обслуживание и последовательными выходами обслуженных "клиентов" из системы;
б) путем подсчета числа поступивших в единицу времени заявок на обслуживание и числа выходящих из системы (в единицу времени) обслуженных клиентов.
Первый способ ориентирован на определение распределений временных отрезков между последовательными поступлениями требований и распределений продолжительностей обслуживания, тогда как второй способ позволяет получить распределение числа прибытий в систему заявок на обслуживание и числа выбытий обслуженных "клиентов" из системы.
Процедура сбора данных может основываться как на примитивном способе фиксации наблюдателем времени с помощью обычного секундомера, так и на использовании автоматических регулирующих устройств.
После того как с помощью одного из упомянутых выше способов требуемая информация оказывается в распоряжении исследователя, ее необходимо систематизировать и обобщить, с тем чтобы получить возможность построить в результате интересующие исследователя распределение вероятностей. Обычно это достигается путем представления результатов анализа накопленных данных в виде частотных гистограмм. Затем выбирается "териотическое" распределение, которое хорошо подходит для описания полученных данных. Далее с целью проверки степени пригодности выбранного распределения для описания реального процесса применяется одна из стандартных тестовых процедур.
Пример. Для регистрации интенсивности транспортных потоков на перекрестке используется специальный автомат-регистратор. Это устройство регистрирует моменты прибытия к перекрестку транспортных средств (для определенности будем говорить об автомобилях) на непрерывной временной шкале, имеющей нулевую точку отсчета. В табл 1. приведены результаты регистрации моментов прибытия (в минутах) для первых шестидесяти автомобилей.
Таблица 1.
Порядковый номер прибытия |
Время прибытия, мин |
Порядковый номер прибытия |
Время прибытия, мин |
Порядковый номер прибытия |
Время прибытия, мин |
Порядковый номер прибытия |
Время прибытия, мин |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
1 |
5,2 |
16 |
67,6 |
31 |
132,7 |
46 |
227,8 |
2 |
6,7 |
17 |
69,3 |
32 |
142,3 |
47 |
233,5 |
3 |
9,1 |
18 |
78,6 |
33 |
145,2 |
48 |
239,8 |
4 |
12,5 |
19 |
86,6 |
34 |
154,3 |
49 |
243,6 |
5 |
18,9 |
20 |
91,3 |
35 |
155,6 |
50 |
250,5 |
6 |
22,6 |
21 |
97,2 |
36 |
166,2 |
51 |
255,8 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
7 |
27,4 |
22 |
97,9 |
37 |
169,2 |
52 |
256,5 |
8 |
29,9 |
23 |
111,5 |
38 |
169,5 |
53 |
256,9 |
9 |
35,4 |
24 |
116,7 |
39 |
172,4 |
54 |
270,3 |
10 |
35,7 |
25 |
117,3 |
40 |
175,3 |
55 |
275,1 |
11 |
44,4 |
26 |
118,2 |
41 |
180,1 |
56 |
277,1 |
12 |
47,1 |
27 |
124,1 |
42 |
188,8 |
57 |
278,1 |
13 |
47,5 |
28 |
127,4 |
43 |
201,2 |
58 |
283,6 |
14 |
49,7 |
29 |
127,6 |
44 |
218,4 |
59 |
299,8 |
15 |
67,1 |
30 |
127,8 |
45 |
219,9 |
60 |
300,0 |
Данные, приведенные в табл 1. можно использовать для нахождения распределения числа прибытий в единицу времени. Для этого прежде всего выбирается единица измерения времени. В рассматриваемом примере за единицу времени принимается 1ч. из табл 1. видно, что в течение первого часа зарегистрировано 14 прибытий, второго часа - 12 прибытий, третьего часа - 14 прибытий, в течение четвертого часа - 8 прибытий, в течение пятого часа - 12 прибытий. Это означает, что в рассматриваемом пятичасовом интервале число прибытий в 1 ч оказалось равным 8с с частотой 1, 12 с частотой 2 и 14 с частотой 2.
Теперь представим себе, что мы имеем полную информацию относительно времени каждого из наблюдавшихся прибытий и для каждого числа прибытий в час n определена соответствующая частота fn (табл 2). Наша цель заключается в том, чтобы с помощью c2- критерия проверить, что эти данные соответствуют конкретному закону распределения.
Таблица 2.
n fn |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
3 |
3 |
|
n fn |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
³17 |
6 |
5 |
9 |
10 |
11 |
8 |
6 |
1 |
0 |
Допустим, что нам хотелось бы проверить справедливость гипотезы о том, что выборка, содержащаяся в табл 2, соответствует пуассоновскому распределению вероятностей. Проверка заключается в сопоставлении наблюдаемой частоты fn с ожидаемым значением частоты, получаемой при допущении, что имеет место пуассоновское расспределение вероятностей.
Таблица 3
n |
pn |
N |
pn |
N |
pn |
0 |
0.0000 |
6 |
0.0303 |
12 |
0.1138 |
1 |
0.0001 |
7 |
0.0504 |
13 |
0.1020 |
2 |
0.0006 |
8 |
0.0734 |
14 |
0.0848 |
3 |
0.0023 |
9 |
0.0950 |
15 |
0.0659 |
4 |
0.0067 |
10 |
0.1106 |
16 |
0.0479 |
5 |
0.0156 |
11 |
0.1172 |
17 |
0.0834 |
Д
 ля
получения ожидаемого значения частоты
в предположении, что закон распределения
является пуассоновским, сначала оценим,
что распределение n
для пуассоновское распределения по
данной выборке. При этом получаем
ля
получения ожидаемого значения частоты
в предположении, что закон распределения
является пуассоновским, сначала оценим,
что распределение n
для пуассоновское распределения по
данной выборке. При этом получаем
З
![]() атем
вычистим вероятности pn
для пуассоновского распределения со
средним значением n=11,65
автомобиля в 1 ч. результаты вычислений
приведены в табл 3. заметим, что
атем
вычистим вероятности pn
для пуассоновского распределения со
средним значением n=11,65
автомобиля в 1 ч. результаты вычислений
приведены в табл 3. заметим, что
П![]() оскольку
полное число наблюдений равняется 63,
ожидаемое значение частоты определяется
по формуле
оскольку
полное число наблюдений равняется 63,
ожидаемое значение частоты определяется
по формуле
Т![]() еперь
нетрудно вычислить значения c2
по
формуле
еперь
нетрудно вычислить значения c2
по
формуле
Потребуем, чтобы fn были не менее пяти. В противном случае образуем группы последовательных значений fn, для которых это условие окажется выполненным. Так, например, в табл 3. Следует объединить в одну группу последовательность значений n от нулю до восьми, в результате чего для наблюдаемой частоты будем иметь значение, равное 7=(1+3+3); образуя группу для всех n, превышающих 14, получим для fn значение, также равное 7=(6+1). Теперь обратимся к таблице 4 , иллюстрирующей полученные значения c2.
Таблица 4.
n |
Fn |
en |
(fn-en)2 en |
0 |
0 |
|
|
5 |
1 |
|
|
6 |
0 7 |
11,3 |
1,636 |
7 |
3 |
|
|
8 |
3 |
|
|
9 |
6 |
5,99 |
0,000 |
10 |
5 |
6,97 |
0,557 |
11 |
9 |
7,17 |
0,356 |
12 |
10 |
6,43 |
1,117 |
13 |
11 |
5,34 |
3,248 |
14 |
8 |
|
1,325 |
1 |
6 |
|
|
16 |
1 7 |
12,42 |
2,365 |
³17 |
0 |
|
|
Суммарные значения |
63 |
63 |
10,6(значения c2) |

 -4
-4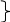 5
5
С![]() равним
теперь полученные значения c2
с
критическим значением для c2-распределения.
Для этого требуется задать уровень
значимости a
и число степеней свободы n.
Величина n
задается соотношением
равним
теперь полученные значения c2
с
критическим значением для c2-распределения.
Для этого требуется задать уровень
значимости a
и число степеней свободы n.
Величина n
задается соотношением
![]() В
рассматриваемом примере мы имеем восемь
составных интервалов. Поскольку среднее
значение для пуассоновского распределения
вероятностей оценивалось на заданной
выборке, имеем n=8-1-1=6.
Положив уровень значимости a
равным 0,05, из таблицы значений c2
получаем критическое значение
В
рассматриваемом примере мы имеем восемь
составных интервалов. Поскольку среднее
значение для пуассоновского распределения
вероятностей оценивалось на заданной
выборке, имеем n=8-1-1=6.
Положив уровень значимости a
равным 0,05, из таблицы значений c2
получаем критическое значение
При использовании c2-критерия выдвигаемая гипотеза относительно характера распределения при заданном уровне значимости a принимается, если значение c2£c2n(a). Поскольку это условие в нашем примере выполняется, принимается гипотеза о том, что приведенная выше выборка соответствует пуассоновскому закону распределения со средним n, равным 11,65 прибытий в 1ч.