

Взаємодія вузлів один з одним
У Deductor взаємодія вузлів один з одним спроектована на рівні програмного ядра, тому принцип взаємодії єдиний і не залежить від типу вузла.
Кожен вузол можна представити «чорним ящиком», на вхід якого подається структурований набір даних з полями, а на виході доступний один або декілька оброблених вузлом наборовши даних. Обробка може вестися будь-яка - від простій сортування до моделювання. Вихідний набір, у свою чергу, можна знову подати на вхід вузла. Так конструюється сценарій (рис.1.7).
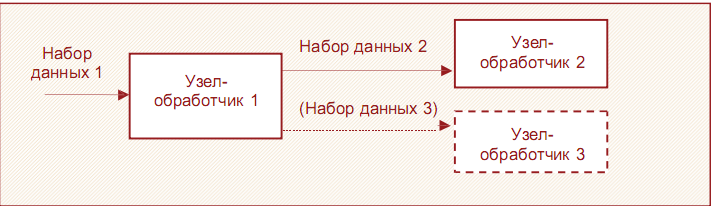
Рис. 1.7. Представлення вузла в Deductor
Але іноді на виході вузла може бути присутнім не один набір, а декілька (на малюнку такий додатковий набір даних позначений пунктирною стрілкою). Наприклад, в результаті роботи вузла Лінійна регресія утворюються два набори даних: один-таблиця розрахованих результатів, а інший - коефіцієнти регресії. Ці коефіцієнти можна проглянути у візуалізаторе під такою ж назвою, але іноді потрібно використовувати коефіцієнти в сценарії для подальшої обробки. Тому при додаванні будь-якого вузла з'являється можливість «перемкнутися» на інший набір даних, якщо він присутній в попередньому вузлі. От як це виглядає в майстрові обробки (рис. 1.8):
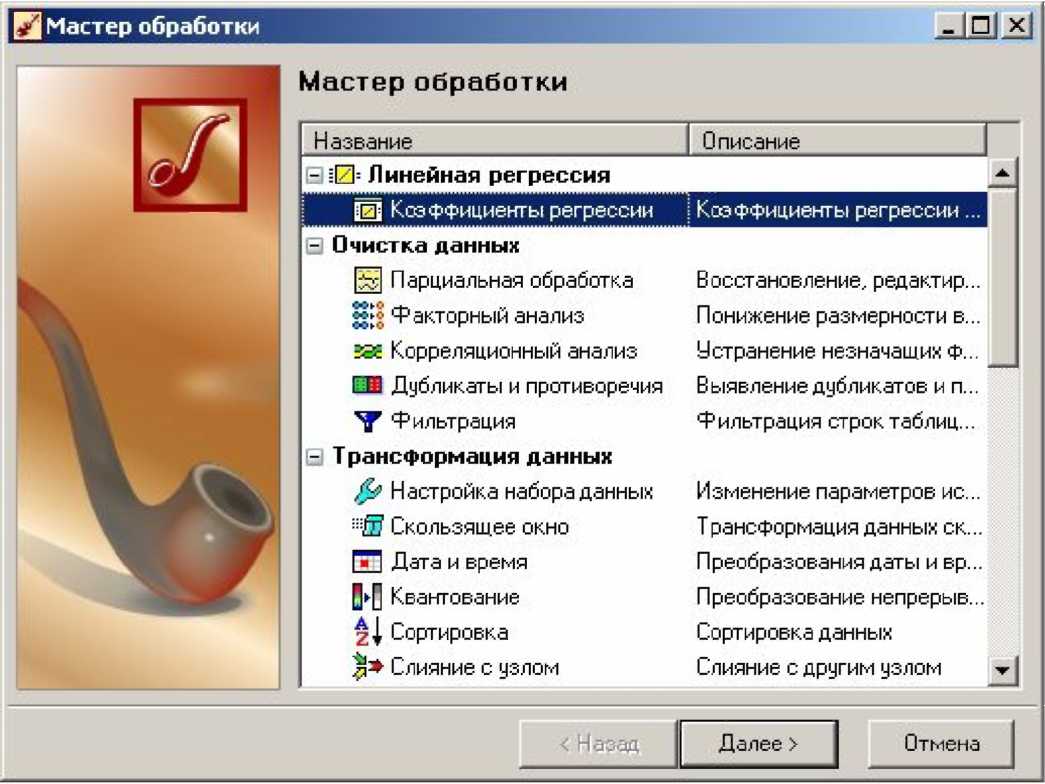
Рис. 1.8. Вікно майстра обробки
У Deductor Studio 5.2 вузлами, які видають на виході більш одного набору даних, є: Лінійна регресія, Логічна регресія, Асоціативні правила, Кореляційний аналіз.
Імпорт з текстових файлів з роздільниками
Структурований текстовий файл з роздільниками - один з найпоширеніших форматів зберігання даних. Таким файлом є звичайний текстовий файл, стовпці даних в якому розділені однотипними символами-роздільниками, наприклад символами табуляції, пропуски, крапки з комою і так далі
Процес імпорту даних з текстового з роздільниками файлу в майстрові імпорту (категорія Текстової файл (Direct)) містить наступні кроки:
● вказати ім'я файлу;
● настройка параметрів імпорту;
● настройка полів, що імпортуються;
● запуск процесу імпорту;
● вибір способу візуалізації;
● завдання відомостей про вузол.
На
кроці Вказати ім'я файлу, натиснувши
кнопку
![]() ,
необхідно вибрати ім'я текстового файлу
(розширення *.txt,
*.csv),
з якого слід виконати імпорт даних.
Після цього в полі «Ім'я файлу» вікна
Майстра імпорту з'явиться ім'я вибраного
файлу і шлях. Допускається вручну ввести
шлях до файлу в рядку поля Ім'я файлу.
,
необхідно вибрати ім'я текстового файлу
(розширення *.txt,
*.csv),
з якого слід виконати імпорт даних.
Після цього в полі «Ім'я файлу» вікна
Майстра імпорту з'явиться ім'я вибраного
файлу і шлях. Допускається вручну ввести
шлях до файлу в рядку поля Ім'я файлу.
Є можливість використовувати як абсолютні, так і відносні шляхи для файлів. Вони указуються щодо поточної директорії Deductor. При відкритті Deductor поточною директорією є директорія файлу проекту. Тому, якщо файл проекту і текстові файли розташовуються в одній папці, то використання відносних шляхів в Майстрові імпорту дозволить не перенастроювати вузли імпорту при зміні розташування папки на жорсткому диску (рис. 1.9).
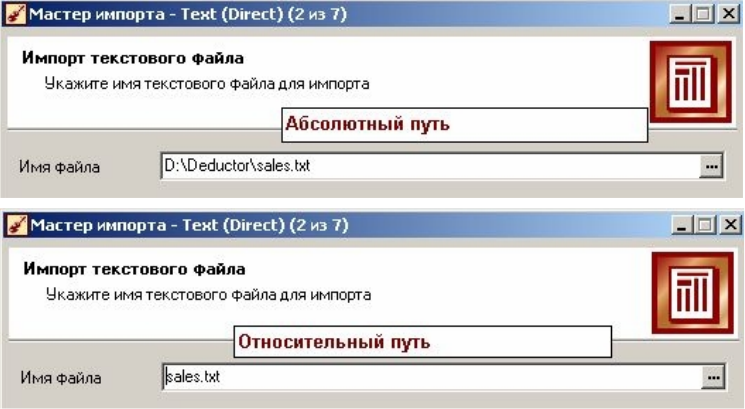
Рис. 1.9. Імпорт текстового файла в Deductor
Тут також доступні настройки:
• почати імпорт з рядка - номер рядка, починаючи з якого робитиметься імпорт даних з файлу.
• прапор Перший рядок є заголовком - установка прапорця означає, що вузол імпортуватиме дані з урахуванням того, що всі записи першого рядка є заголовками стовпців.
• кодування - ANSI (Windows) або ANCII (MS DOS).
На кроці Настройка параметрів імпорту потрібно надаштувати параметри імпорту даних з текстового файлу, оскільки існує декілька форматів структурованих текстових файлів. Доступні опції:
● перемикач Формат початкових даних, який визначає символ-роздільник у файлі (наприклад: символ табуляції, пропуск, кома). Роздільник найчастіше присутній. Якщо ж немає, то потрібно вибрати перемикач Фіксірованної ширини (поля мають задану ширину), а пізніше встановити ширину кожного поля;
● обмежувач рядків - при завданні даного параметра необхідно вказати, який саме обмежувач строкового значення потрібно використовувати при імпорті даних з текстового файлу. Зазвичай таким обмежувачем є символ подвійні лапки ";
● роздільник дробової і цілої частини числа - при завданні даного параметра необхідно вказати символ, що розділяє дріб і цілу частини в числових значеннях, що містяться у файлі.
● роздільник компонентів дати - указується символ, що розділяє компоненти дати у відповідних значеннях, що містяться у файлі.
● роздільник компонентів часу - указується символ, що розділяє компоненти часу у відповідних значеннях, що містяться у файлі.
● формати Дати/Часу - указуються формати дати/часу, використані у файлі, що імпортується.
Представлення значень - опція для полів логічного типу, яке може приймати одне з трьох значень - істина (true), брехня (false) і порожнє значення (null). Визначає регламент запису в ці значення. Так, при настройках за умовчуванням для будь-якого логічного поля значення Та сприйматиметься як істина, Ні – як брехня (рис.1.10).

Рис. 1.10. Настройки форматів імпорту из файла
В якості роздільників, представлених значень і форматів за умовчанням завжди пропонуються системні настройки операційної системи. Тому при імпорті необхідно звертати увагу на їх відповідність формату в текстовому файлі, що імпортується.
Наступне вікно майстра залежить від встановленого перемикача в прапорці Формат початкових даних. Якщо був вибраний формат З роздільниками, то з'явиться вкладка, на якій потрібно явно вказати символ-роздільник (за умовчанням - табуляція). Тут же знаходиться прапор Рахувати послідовні роздільники одним - у разі послідовних символів-роздільників, що йдуть, вони сприйматимуться за один. Таке буває, наприклад, коли символом-роздільником виступають декілька пропусків.
Перегляд текстового файлу у вигляді таблиці внизу (завантажуються тільки перші 10 рядків) дозволяє переконатися в коректності вибору настройок імпорту навіть не запускаючи його (рис. 1.11).
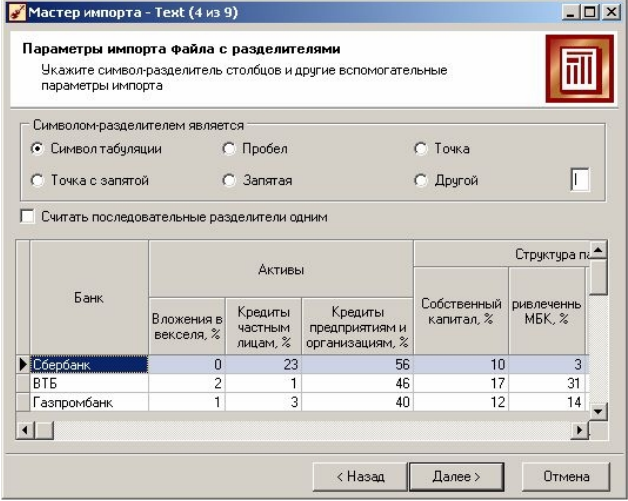
Рис. 1.11. Вікно параметрів файла з роздільниками
Якщо був вибраний прапор формат Фіксованої ширини, то з'явиться вкладка, на якій потрібно задати межі кожного поля. Створення, як і видалення маркера межі проводиться одним клацанням миші. Рухаючи маркери меж стовпців, можна змінювати їх, якщо вони розставлені неправильно. Дані, розподілені по стовпцях, показуються в області попереднього перегляду (рис. 1.12).
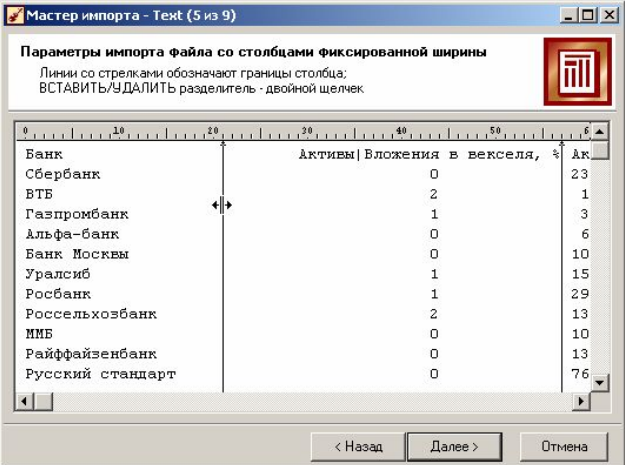
Рис. 1.12. Вікно імпорту файла з фіксованою шириною
На кроці Настройка параметрів стовпців потрібно налаштувати наступні параметри стовпців даних, що імпортуються, вказавши відповідні значення в полях (рис. 1.13).
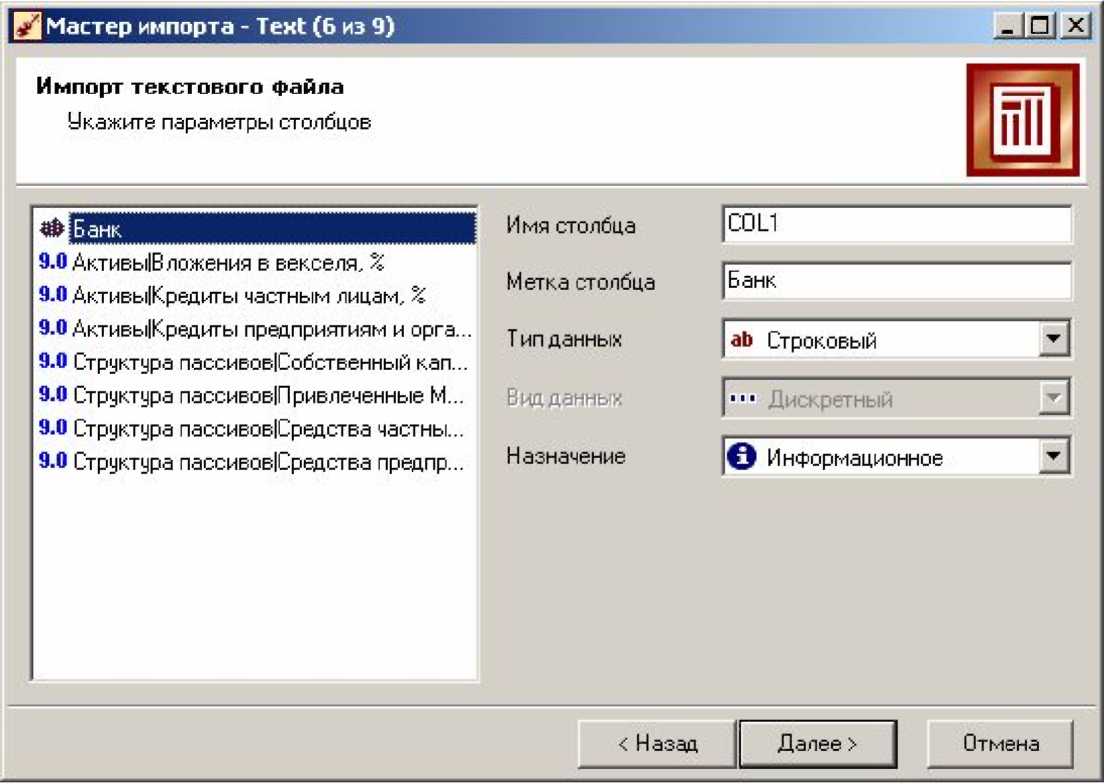
Рис. 1.13. Настройка парамеирів імпорту даних
Ім'я стовпця - вказується ім'я, яке служитиме ідентифікатором стовпця в подальших вузлах. За умовчанням пропонується заголовок стовпця з текстового файлу, якщо на попередньому кроці був встановлений прапорець Перший рядок є заголовком. Тоді будуть запропоновані імена типу COl1, COl2 і так далі. Можна ввести будь-які імена, які семантично відображають вміст стовпця, проте допускаються тільки латинські символи, і ім'я стовпця повинне бути унікальним в межах всіх стовпців файлу, що імпортується.
Мітка стовпця - назва, під якою даний стовпець буде видний у візуалізаторах. Допускаються будь-які символи, унікальність імен не обов'язкова.
Тип даних - вказується тип даних, що містяться в стовпці. Тип вибирається із списку, що відкривається клацанням по кнопці в правій частині поля:

Вузол імпорту завжди намагається автоматично розпізнати тип даних по першому рядку файлу (якщо є заголовки, то по другому рядку). Такий алгоритм спрацьовує не завжди. Наприклад, хай у файлі є стовпець Число утриманців, і в нім дані йдуть в наступному порядку:

Для даного поля автоматично визначитись тип - речовий, але в реальності він строковий.
Вид даних - характер даних, що містяться в стовпці:

Безперервними можуть бути тільки числові дані. Дискретний характер носять, як правило, строкові дані, але не завжди. Дискретними можуть бути призначені, залежно від контексту вирішуваного завдання, дані цілого типу, рідше - речового. Вид даних стовпця впливає на:
► алгоритм розрахунку статистики по стовпцю;
► роботу аналітичних алгоритмів.
Призначення - визначає порядок використання поля набору даних, отриманого в результаті імпорту стовпця (поля), при подальшій обробці імпортованих даних:
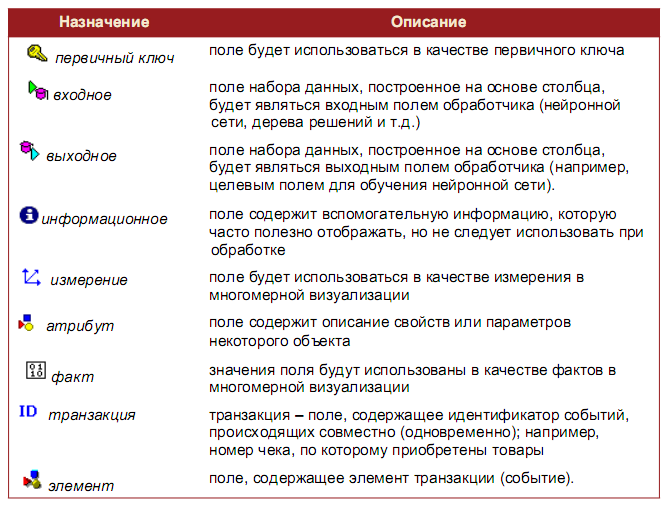
Змінити призначення групи стовпців однією операцією можна таким чином:
■ утримуючи клавішу Shift, виділити мишкою або клавішами Ctrl+↓, Ctrl +↑ перший і останній стовпці групи стовпців і змінити їх призначення;
■ утримуючи клавішу Ctrl, виділити мишкою тільки потрібні стовпці і змінити їх призначення.
Зауваження!!!
Установка призначення стовпця набору даних при імпорті не є обов'язковою дією (за умовчанням при імпорті встановлено призначення «інформаційне»). Проте це може понизити об'єм рутинних дій при подальшому конструюванні сценарію. Наприклад, при побудові моделей (група вузлів обробки Data Mining) за умовчанням вихідним полем, як правило пропонується останнє поле, і, якщо це не так, доведеться кожного разу перевизначати призначення полів в кожному новому вузлі.
На кроці Запуск процесу імпорту стартує сам процес імпорту даних з раніше настроєними параметрами. Хід процесу імпорту відображається за допомогою індикатора. Якщо процес імпорту зупинився, це сигналізує про можливі помилки при читанні даних. В цьому випадку з'являється вікно з повідомленням про помилку.
У разі виникнення помилок невідповідності типів процес імпорту буде продовжений, але після його закінчення буде відображений журнал реєстрації помилок з інформацією про місце і причину їх появи:
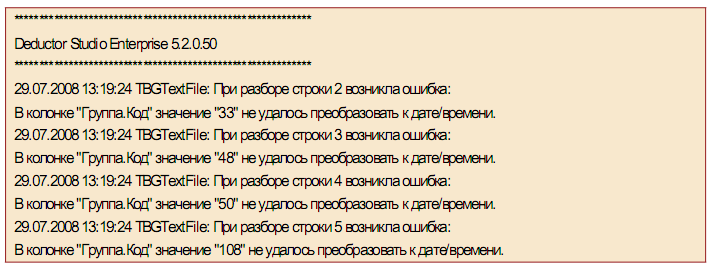
Для управління процесом імпорту передбачені наступні кнопки:
► Пуск - запускає процес вперше або відновлює після паузи.
► Пауза - тимчасово припиняє імпорт.
► Стоп - зупиняє процес без можливості його продовження.
На двох кроках майстра імпорту, що залишилися, буде запропоновано вибрати візуалізатор набору даних (за умовчанням пропонується Таблиця) і задати відомості про вузол.