

6.1. Теоретичні основи роботи
Правила, які виявляють взаємозв'язок між двома та більше подіями називаються асоціативними правилами.
Асоціативне правило складається з двох наборів предметів, що називають умовою (англ.antecedent) і наслідком (англ. consequent) і записується це у вигляді X →Y, що читається «з X слідує Y ». Таким чином, асоціативне правило формулюється у вигляді «Якщо умова - то наслідок».
Таким чином ключовими поняттями в асоціативних правилах є:
• Умова.
• Наслідок.
• Транзакція - деяка множина подій, що відбуваються одночасно.
Асоціативні правила характеризуються наступними показниками:
1. Показник підтримки асоціативного правила - це число транзакцій, які містять як умову, так і наслідок.
![]()
2.Показник достовірності асоціативного правила А→В є мірою точності правила і визначається як відношення кількості транзакцій, що містять як умову, так і наслідок, до кількості транзакцій, що містять тільки умову, тобто:
![]()
3.Ліфт - це відношення частоти появи умови в транзакціях, які також містять і наслідок, до частоти появи наслідку в цілому. Значення ліфту більші за одиницю показують, що умова частіше з'являється в транзакціях у парі з наслідком, ніж самостійно. Можна сказати, що ліфт є узагальненою мірою зв'язку двох наочних наборів: при значеннях ліфта >1 зв'язок позитивний, при 1 він відсутній, а призначеннях <1 - негативний.
![]()
Левередж - це різниця між підтримкою асоціації (тобто, частотою, з якою умова та наслідок з'являються спільно в транзакції ), і добутком підтримки умови та наслідку окремо.
![]()
Загальні методичні рекомендації
В Deductor Studio для вирішення завдань асоціації використовується обробник «Ассоциативные правила». Працює він на алгоритмі а рriori.
Для роботи обробника потрібно на вхід подати два поля: ідентифікатор транзакції і елемент транзакції. Наприклад, ідентифікатор транзакції - це номер чека або код клієнта. А елемент - це найменування товару в чеку або послуга, замовлена клієнтом.
Важливою особливістю є те, що обидва поля - як ідентифікатор, так і елемент транзакції - повинні бути дискретного типу.
На даній лабораторній роботі поставимо перед собою завдання провести аналіз по стимулювання продаж інтернет-магазину.
Дискретні дані є значеннями, загальне число яких, як правило, нескінченне, але може бути підраховано за допомогою натуральних чисел від одного до безкінечності. З дискретними даними не можуть бути проведені жодні арифметичні дії, бо вони не мають сенсу. Дискретними даними є всі дані строкового і логічного типу. Дискретними можуть бути і числові дані. Наприклад, поле «Код товару», що набуває значень цілого типу, дискретно, оскільки операції додавання, віднімання, множення над «Кодом товару» не мають сенсу.
Компанія займається дистрибуцією спортивних (серія Sport), гірських (Mountain) та дорожніх (серія Road) велосипедів та комплектуючих до них.
Відділ маркетингу компанії зацікавлений в поліпшенні свого web-сайту, на якому розташований інтернет-магазин. Поставлено завдання прогнозу того, які товари можуть вибрати покупці залежно від того, що вже є в їхніх товарних кошиках. Окрім підвищення і стимулювання рівня продаж, ці прогнози допоможуть найбільш правильно організувати структуру сайту, щоб товари, що купуються разом, і на сайті розташовувалися поряд.
Отож, перейдемо до практичної реалізації даного завдання:
• Запустіть Deductor Studio.
• Імпортуєте файл «bicycle_sales.txt:».
• Застосуйте до імпортованої гілки обробник «Ассоциативные правила».
• На 2 кроці майстра (рис. 6.1) вкажіть, що поле «ID» є транзакція, а «ІТЕМ» - елементом.
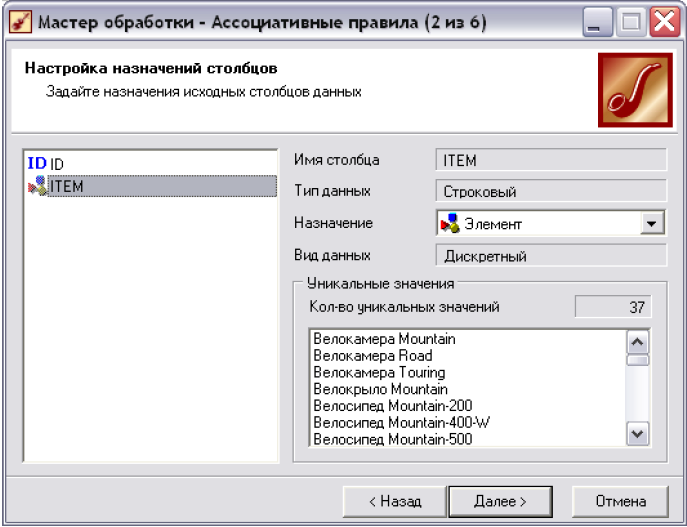
Рис. 6.1. Другий крок майстра «Ассоциативные правила».
• На наступному - третьому - кроці налаштуємо параметри побудови асоціативних правил. Фактично це є параметри алгоритму а рriori (рис. 6.2). Поки-що всі налаштування на даному кроці залишаємо без змін.
а. Минимальная й максимальная поддержка, % - обмежують простір пошуку наборів, що часто зустрічаються. Асоціативні правила шукаються тільки в деякій множині всіх транзакцій. Для того, щоб транзакція увійшла до цієї множини вона повинна зустрічатися в початковій вибірці ту кількість разів, що більше мінімальної підтримки і менше максимальної. Наприклад, мінімальна підтримка дорівнює 1%, а максимальна - 20%. Кількість елементів «Хліб» і «Молоко» стовпця «Товар» з однаковим значенням стовпця «Номер чека» зустрічаються в 5% всіх транзакцій (номерів чека). Тоді ці два рядки увійдуть до шуканої множини.
Ь. Минимальная й максимальная поддержка достоверность, % - в результуючий набір потраплять тільки ті асоціативні правила, які задовольняють умовам мінімальної і максимальної достовірності.
с. Максимальная мощность искомьіх часто встречающихся множеств -параметр обмежує довжину k-предметного набору. Якщо цей параметр вказаний, то максимальна потужність (кількість елементів) множин, що часто зустрічаються, буде не більше значення цього параметра. Отже, будь-яке результуюче правило складатиметься не більш, ніж з <максимальна потужність> елементів. Наприклад, при установці значення 4, крок генерації популярних наборів буде зупинений після отримання безлічі 4-наочних наборів. Зрештою це дозволяє уникнути появи довгих асоціативних правил, які важко інтерпретуються.
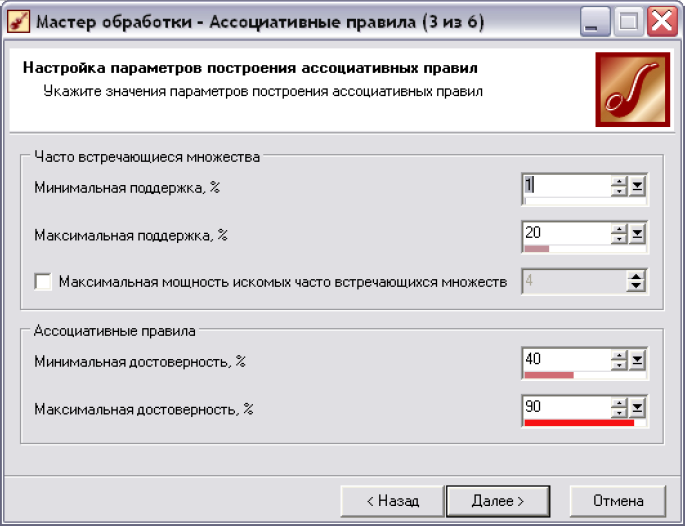
Рис. 6.2. Третій крок майстра «Ассоциативные правила».
• На
слідуючому 4 кроці натискаємо кнопку
![]() (рис.
6.3) і таким чином запустимо алгоритм
пошуку асоціативних правил а
рriori.
Після виконання алгоритму у вікні
майстра (рис. 6.3)
в полях буде наступна інформація:
(рис.
6.3) і таким чином запустимо алгоритм
пошуку асоціативних правил а
рriori.
Після виконання алгоритму у вікні
майстра (рис. 6.3)
в полях буде наступна інформація:
а. Количество множеств - число популярних наборів, що задовольняють заданий рівень мінімальної підтримки та достовірності.
Ь. Количество правил - кількість згенерованих асоцітиативних правил.
с Мощность часто встречающихся множеств - на діаграмі у верхній частині вікна відображається потужність знайдених множин. Потужність множини - це кількість елементів, з яких вона складається. Число уздовж горизонтальної осі графіка показує потужність множин, що часто зустрічаються, тобто з скількох елементів складається елемент множини. Наприклад, одноелементні множини - (Товар5, Товар9, Товар23...), двоелементні множини - ((Товар2 і Товар5), (Товар19 і Товар4), (Товар15 і Товар14),...) і так далі. Вздовж вертикальної осі - кількість елементів в множинах.
Зауваження!!!
Якщо в результаті роботи алгоритму були знайдені тільки одноелементні множини, то правила не можуть бути отримані. Слід повернутися на попередній крок і зменшити мінімальну і/або збільшити максимальну підтримку.
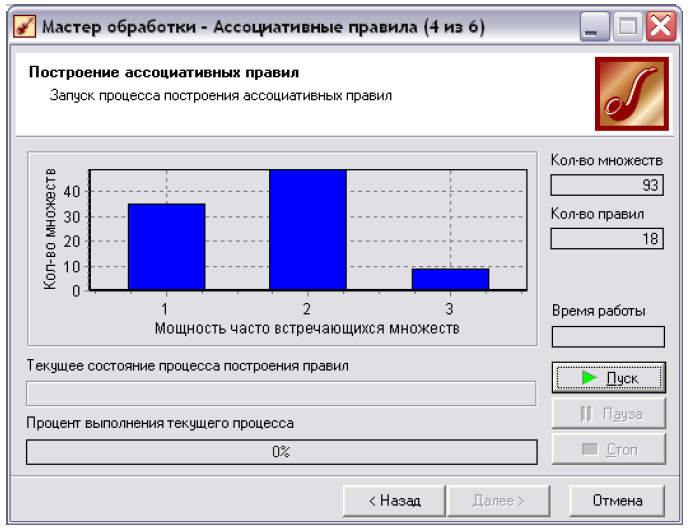
Рис. 6.3. Четвертий крок майстра «Ассоциативные правила».
• На п'ятому кроці майстра задаємо візуалізатори для знайдених асоціативних правил, як це показано на рис. 6.4.
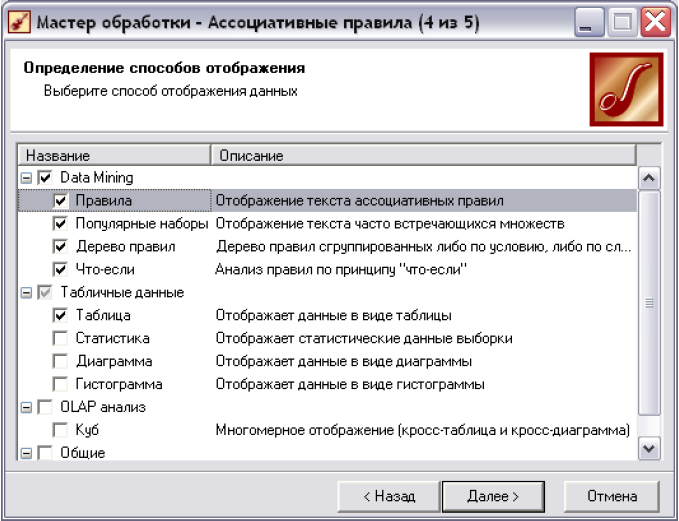
Рис. 6.4. П'ятий крок майстра «Ассоциативные правила».
• Шостий крок майстра завершіть самостійно.
Тепер розглянемо візуалізатори, які були утворені внаслідок побудови асоціативних правил, їх є 4: «Правила», «Популярнвые наборы», «Дерево правил», «Что-если» (рис. 6.5).
![]()
Рис. 6.5. Закладки візуалізаторів.
Слід зауважити, що всі візуалізатори, крім «Что-если», відображають результати роботи-алгоритму а рriori в різних формах:
• Правила - візуалізатор відображає асоціативні правила у вигляді списку правил.
• Популярные
наборы
- відображається множина знайдених
популярних наборів у вигляді списку.
Кнопка
![]() пропонує на вибір декілька варіантів
сортування списку, а кнопка
пропонує на вибір декілька варіантів
сортування списку, а кнопка
![]() викликає вікно настройки фільтру множин.
Наприклад, задавши у фільтрі мінімальне
значення підтримки 6% і відсортувавши
їх по спаданню підтримки, отримаємо
наступні 16 популярних наборів (рис.
6.6).
викликає вікно настройки фільтру множин.
Наприклад, задавши у фільтрі мінімальне
значення підтримки 6% і відсортувавши
їх по спаданню підтримки, отримаємо
наступні 16 популярних наборів (рис.
6.6).
Фильтр: Поддержка >= 6,00%
Итого множеств: 16
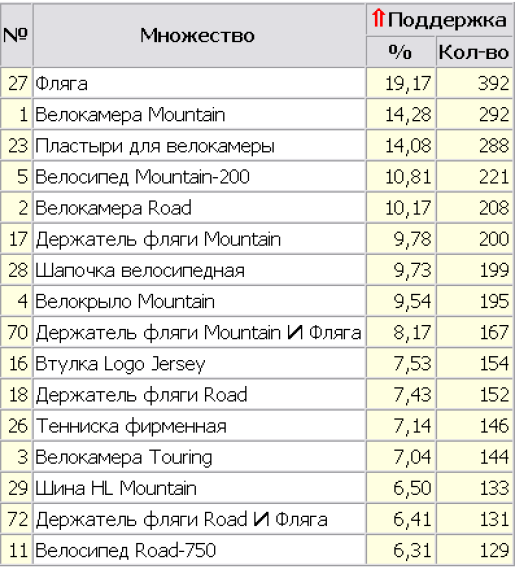
Рис.6.6 .Популярні набори з рівнем підтримки більше-рівне 6%
• Дерево правил - ще один зручний спосіб відображення асоціативних правил, який будується або по умові, або по наслідку. При побудові дерева правил по умові, на першому (верхньому) рівні знаходяться вузли з умовами, а на другому рівні - вузли із наслідком. В дереві, побудованому по наслідку, навпаки, на першому рівні розташовуються вузли із наслідком. Праворуч від дерева розташований список правил, побудований по вибраному вузлу дерева (рис. 6.7).
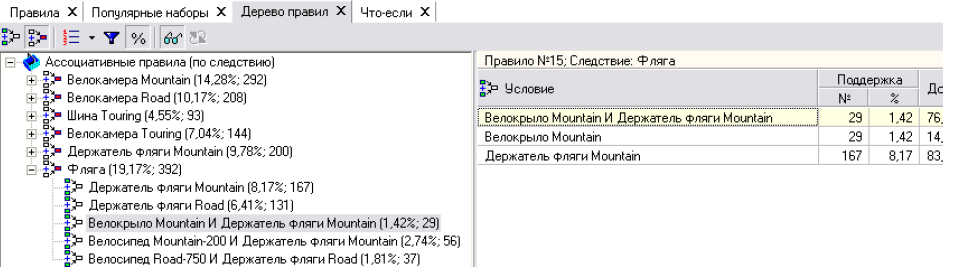
Рис. 6.7. Дерево асоціативних правил.
Для кожного правила відображаються підтримка і достовірність. Якщо дерево побудоване по умові, то вверху списку відображається умова правила, а список складається з його наслідків. Тоді правила відповідають на питання, що буде за такої умови.
Якщо ж дерево побудоване по наслідку, то вверху списку відображається наслідок правила, а список складається з його умов. Ці правила відповідають на питання, що потрібно, щоб отримати заданий наслідок або які товари потрібно продати для того, щоб також продати товар із наслідку.
•
Что-
если
- дозволяє відповісти на питання, що ми
отримаємо як наслідок, якщо виберемо
певні умови, наприклад, які товари
купуються разом з вибраними товарами.
У вікні візуалізатора (рис. 6.8) ліворуч
відображається список всіх товарів,
якими ми оперуємо із вказаною підтримкою,
праворуч вверху - товари-умови, а праворуч
внизу - товари-наслідки. Додати товар в
умову можна за допомогою подвійного
кліку, а вирахувати наслідки - за допомогою
кнопки
![]()
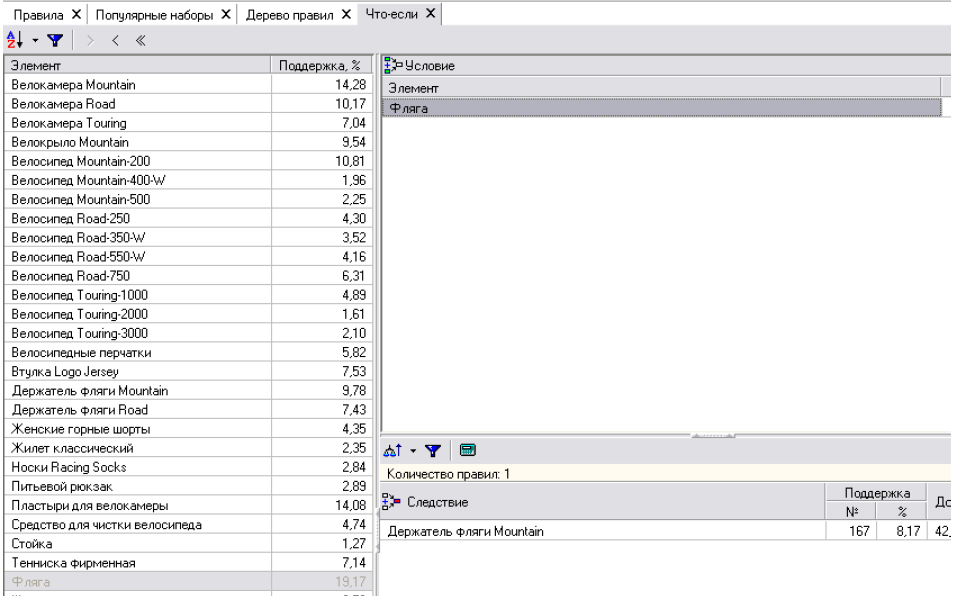
Рис. 6.8. Візуалізатор «Что-если».
Що запропонувати ще нашому клієнту?
В Deductor Studio 5.1 ліфт правил не розраховується, проте знайти цей важливий показник для правила не тяжко:
■
Перш
за все, пригадаймо формулу обчислення
ліфту:![]()
■ Поставимо перед собою завдання обрахувати кількість транзакцій в яких зустрічається кожен наш товар окремо. Для цього:
а.
виділимо в дереві сценаріїв імпортований
файл, кнопкою
![]() відкриємо майстер обробки «Группировка»
і на першому кроці задамо для «ID»
«назначение» - «факт», а «агрегация» -
«количество» (рис. 6.9).
відкриємо майстер обробки «Группировка»
і на першому кроці задамо для «ID»
«назначение» - «факт», а «агрегация» -
«количество» (рис. 6.9).
b. тепер додамо до назв товарів лапки. Виділяємо гілку
![]() і
запускаємо обробник «Калькулятор» і
і
запускаємо обробник «Калькулятор» і
на
першому кроці майстра (рис. 6.10):
1) ЛКМ2 по
![]() і
задаємо наступне, як
вказано
на рис. 6.10;
2) в рядку для введення виразів набираємо
і
задаємо наступне, як
вказано
на рис. 6.10;
2) в рядку для введення виразів набираємо
![]()
■ Тепер до таблиці вже знайдених асоціативних правил додамо отриманні значення частоти появи наслідку у транзакціях. Для цього:
а.
Виділимо
гілку
![]() і
запустимо обробку
і
запустимо обробку
«Слияние с узлом». Кроки даної обробки дивись на рис. 6.11а-в.
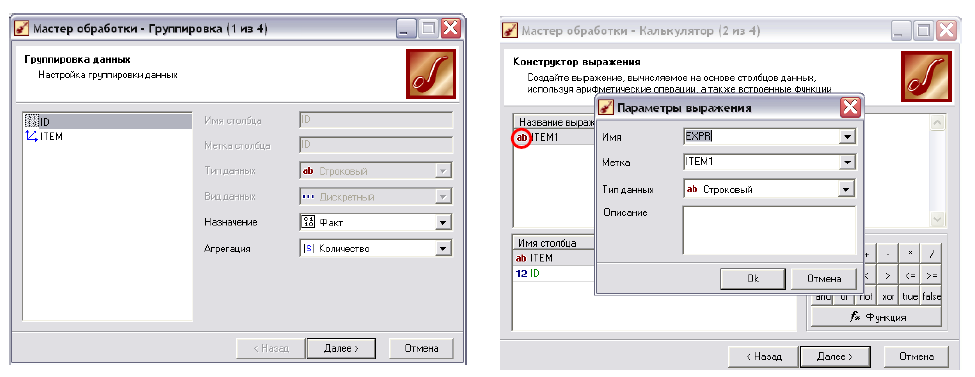
Рис. 6.9. Обробник «Группировка» Рис. 6.10. Обробник «Калькулятор»
 Рис.
11а.Обробник «Слияние с узлом».Крок1
Рис. 11б.Обробник «Слияние с узлом».Крок2
Рис.
11а.Обробник «Слияние с узлом».Крок1
Рис. 11б.Обробник «Слияние с узлом».Крок2
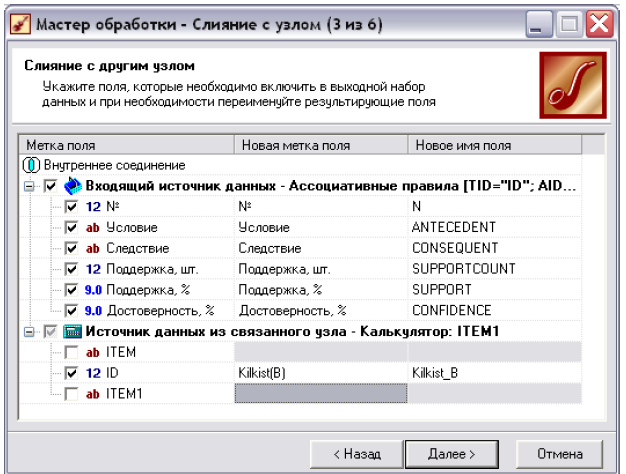
Рис. 11в.Обробник «Слияние с узлом».Крок3
■
Оскільки
наш показники частоти появи наслідку
в транзакціях Kilkist(В)
вимінюється натурально, а достовірність
С(А→В) - у відсотках, то значення Kilkist(В)
також потрібно привести у відсотковий
вигляд. Для цього для гілки
![]() застосуємо
обробник «Калькулятор»
з
наступними параметрами рис. 6.12.
застосуємо
обробник «Калькулятор»
з
наступними параметрами рис. 6.12.
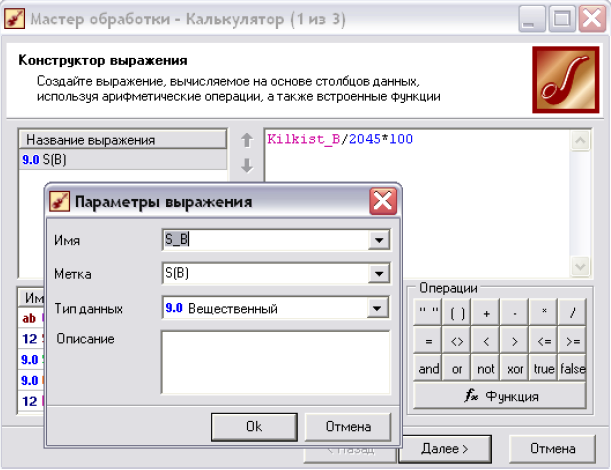
Рис. 6.12. Обробник «Калькулятор» для обчислення S(В).
■ Для обчислення ліфту знову ж застосуємо обробник «Калькулятор» з наступним параметрами(рис. 6.13):
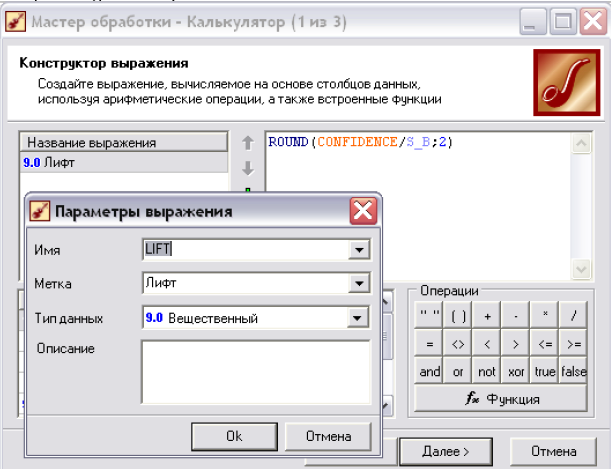
Рис. 6.13. Обробник «Калькулятор» для обчислення ліфту.
Результатом роботи має бути таблиця зображена на рис. 6.14.
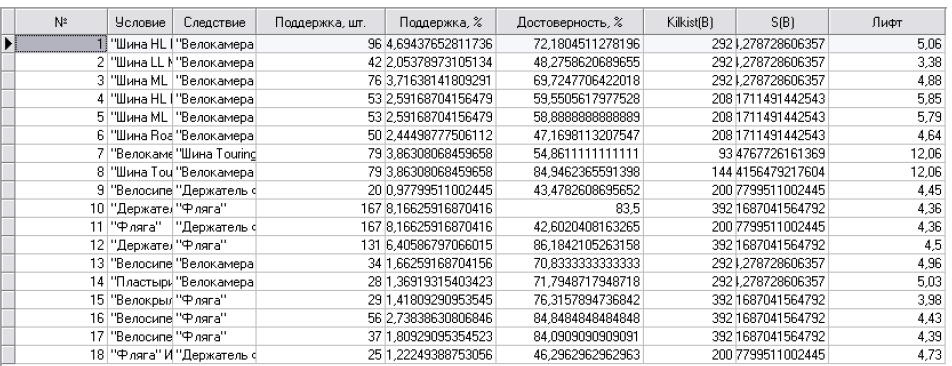
Рис. 6.14. Результуюча таблиця обчислення ліфту асоціативних правил.
Варто відмітити, що дуже зручно робити порівняння асоціативних правил в ОLАР-кубі. Для цього ми до отриманих даних застосуємо сортування (це робиться для зручності порівняння) та побудуємо ОLАР -куб:
■
До
гілки
![]() застосуємо
обробник «Сортировка» і задамо параметри,
що зображені на рис. 6.15.
застосуємо
обробник «Сортировка» і задамо параметри,
що зображені на рис. 6.15.
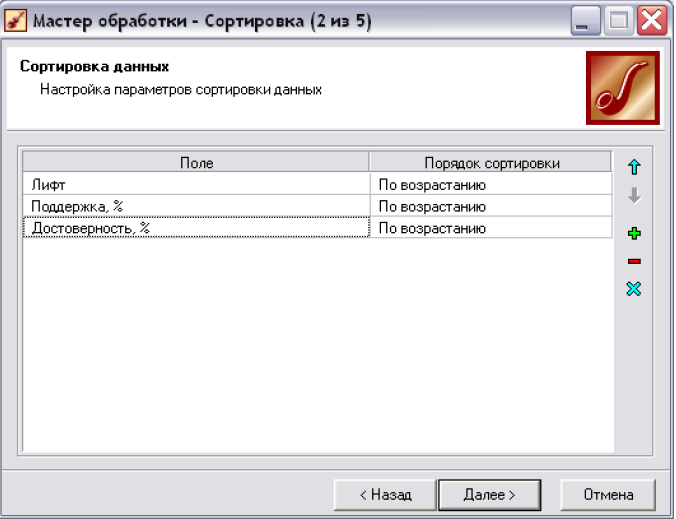
Рис. 6.15. Обробник «Сортировка».
■ На етапі вибору візуалізатора для вузла сортування, крім таблиці, виберемо також «ОLАР -анализ - Куб» і в параметрах ОLАР -кубу задамо наступні параметри (рис. 6.16а-в).
■
Після
побудови ОLАР
-кубу за допомогою кнопки
![]() задайте, щоб в кубі взагалі не виводилися
підсумки («Итоги»).
задайте, щоб в кубі взагалі не виводилися
підсумки («Итоги»).
Наш результат зображений на рис. 6.17. За допомогою такого ОLАР -кубу досить легко та зручно аналізувати правила. Однак тут постає трудність: проаналізувати отриманні правила ми можемо, але як їх інтерпретувати і зробити практичні висновки в контексті поставленої задачі - стимулювання продажу інтернет-магазину.
Рис. 6.16а. Побудова ОLАР –кубу Рис. 6.16б. Побудова ОLАР –кубу
Рис. 6.16в. Побудова ОLАР –кубу
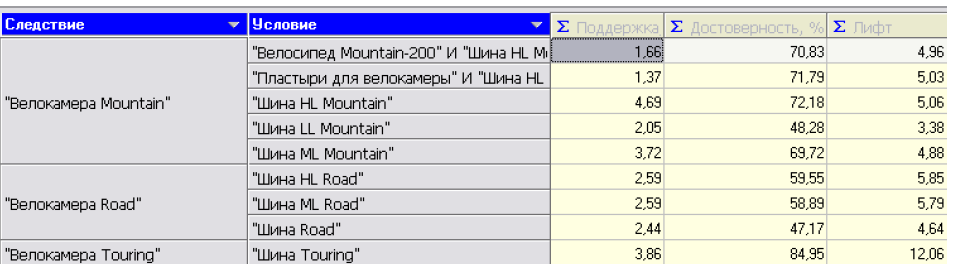
Рис. 6.17. Фрагмент ОLАР -кубу для асоціативних правил.
ЦЕ ВАЖЛИВО ПРОЧИТАТИ І ЗРОЗУМІТИ!!!
Асоціативні правила самі по собі, як результат роботи деякого алгоритму, ще не готові до використання. Їх потрібно проінтерпретувати, тобто зрозуміти, які з асоціативних правил представляють інтерес, чи дійсно правила відображають закономірності або навпаки є артефактами. Це вимагає ретельної роботи аналітика і розуміння наочної області, в якій вирішується завдання асоціації.
Всю множину асоціативних правил можна розділити на три види:
• Корисні правила - містять інформацію, яка раніше була невідома, але має логічне пояснення. Такі правила можуть бути використані для ухвалення ефективних та корисних рішень.
• Тривіальні правила - містять інформацію, яка вже відома чи її можна легко з'ясувати. Такі правила навряд чи можуть принести користь, оскільки відображають або відомі закони в досліджуваній області, або результати минулої діяльності. При аналізі ринкових корзин в правилах з найвищою підтримкою і достовірністю опиняться товари-лідери продаж. Практична цінність таких правил вкрай низка.
• Незрозумілі правила - містять інформацію, яка не може бути пояснена. Такі правила можуть бути отримані або на основі аномальних значень, або глибоко прихованих знань. Безпосередньо такі правила не можна використовувати для ухвалення рішень, оскільки їх невизначеність може привести до непередбачуваних результатів. Для кращого розуміння потрібний додатковий аналіз.
Варіюючи верхню і нижню межу підтримки та достовірності, можна позбутися очевидних і нецікавих закономірностей. Як наслідок, правила, що генеруються алгоритмом, стають більш реалістичними. Поняття «верхня» і «нижня» межа дуже сильно залежать від предметної області, тому не існує чіткого алгоритму їх вибору. Але є ряд загальних рекомендацій.
Корисні поради:
• Велика величина параметра «Максимальная поддержка» означає, що алгоритм знаходитиме добре відомі правила, або вони будуть настільки очевидними, що в них немає ніякого сенсу. Тому ставити поріг максимальної підтримки дуже високим (більше 20%) не рекомендується.
• Більшість цікавих правил знаходяться саме при низькому значенні порогу підтримки, хоча дуже низьке значення підтримки веде до генерації статистичне необґрунтованих правил. Тому правила, які здаються цікавими, але мають низьку підтримку, додатково аналізуйте, розраховуючи для них ліфт, левередж і покращення.
• Обмежуйте потужність множин, що часто зустрічаються, - правила з великим числом предметів в умові важко інтерпретуються і сприймаються.
• Зменшення порогу достовірності приводить до збільшення кількості правив. Значення мінімальної достовірності не повинне бути дуже маленьким, оскільки цінність правила з достовірністю 5% найчастіше настільки мала, що це і правилом вважати не можна.
• Правило з дуже великою достовірністю (>85-90%) практичної цінності в контексті вирішуваного завдання не має, оскільки товари, що входять в наслідок, покупець, швидше - а все, вже й так купив.
Отож, інтерпретація правил в контексті поставленої задачі.
При налаштуваннях алгоритму а рriori по замовчуванні ми отримали 18 правил.
Наприклад перше правило:
![]()
Це означає наступне:
•
очікувана
ймовірність покупки набору
![]() дорівнює 4,7%;
дорівнює 4,7%;
•
якщо
клієнт поклав в кошик
![]() ,
то з вірогідністю 72,2% він купить і
,
то з вірогідністю 72,2% він купить і
![]() ;
;
Артефакт (від латів. artefactum - штучно зроблене) - явище, процес, предмет, властивість предмету або процесу, поява якого в спостережені неможлива або малоймовірна. Поява артефакту є ознакою цілеспрямованого втручання в процес або наявність якихось неврахованих чинників. В моделюванні і Data Mining артефактом можна назвати появу помилкових знань про досліджуваний процес, причиною чого є вплив засобів проведення експерименту на процес, що вивчається, дефекти методики, вплив суб'єктивного чинника, некоректне застосування аналітичних методів.
•
клієнт,
що купив
![]() ,
в 5,1 разів частіше вибере
,
в 5,1 разів частіше вибере
![]() ,
ніж будь-який інший товар.
,
ніж будь-який інший товар.
Аналіз наших 18 правил дозволяє дійти до висновку, що вони всі, окрім двох, тривіальні:
• шини, велокамери і велосипеди часто зустрічаються в умовах і наслідках правил, це лідери продаж магазину (див. популярні набори), тому і правила з ними мають високу достовірність (до 85%);
• група правил Шина →Велокамера і навпаки тривіальні самі по собі: люди часто міняють ці запчастини разом;
• правила типу Утримувач фляги→Фляга (і навпаки) теж тривіальні, оскільки нікому не потрібна велосипедна фляга без можливості її закріпити на рамі;
• правила типу Велосипед→Фляга теж тривіальні, хоча воно, можливо, й має цінність - ніколи не буде зайвим при покупці велосипеда запропонувати флягу і утримувач до неї.
А ось правило:
![]()
не зрозуміло: чому пластирі купуються саме до шин Mountain, адже є і інші шини?
Можливо, тому що велокамери Mountain продаються частіше за інші камери, а це, у свою чергу, із-за популярності велосипедів категорії Mountain? Ствердні відповіді на ці питання містяться при аналізі популярних наборів (рис. 6.18).
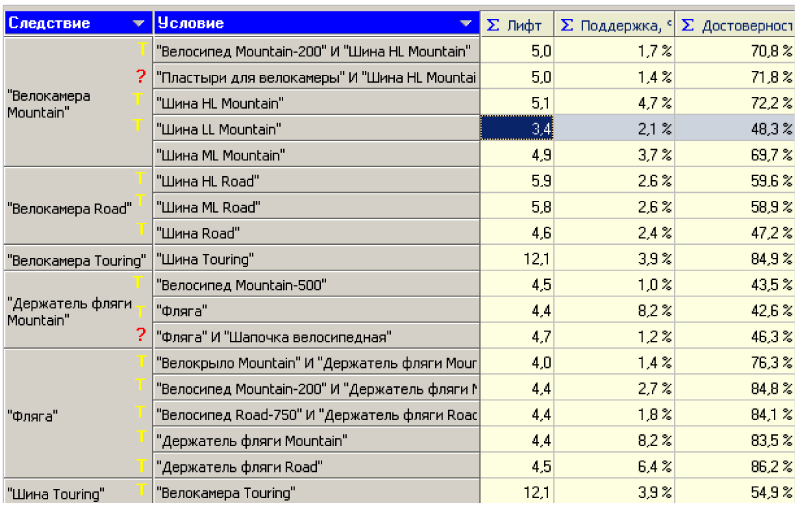
Рис. 6.18. Інтерпретація правил (Т - тривіальні, ? - незрозумілі).
Той факт, що при достовірності 42-43% зустрічаються тривіальні правила, наводить на думку, що при менших значеннях можуть зустрічатися цікаві правила. Тому:
• Запустимо алгоритм побудови асоціативних правил для гілки з імпортованими даними зі значеннями достовірності: min - 25% та max - 40%.
• Обрахуємо ліфт для отриманих правил на основі раніше розроблених процедур та побудуємо OLAP-куб. Для цього виділимо гілку з асоціативними правилами (достовірність 25-40%) запустимо обробник «Скрипт» та виконаємо його налаштування, як це показано на рис. 6.19 а-г.
• Не будемо розглядати умови та наслідки, які містять велосипеди, шини, велокамери та тримачі. Оскільки це знову будуть тривіальні правила. Тобто здійснимо фільтрування OLAP -кубу. В результаті ми отримаємо куб, що зображений на рис. 6.20.
Рис.6.19а.Обробник «Скрипт».Крок1 Рис.6.19б.Обробник «Скрипт».Крок3.
Рис.6.19в.Обробник «Скрипт».Крок5. Рис.6.19г.Обробник «Скрипт».Крок6.

Рис. 20. Результуючий вигляд ОLАР-кубу для правил з достовірністю 25-40%.
Як
видно, всі п'ять правил можна назвати
корисними: вони не очевидні, але зрозумілі.
Наприклад, візьмемо правило
![]() .Розрахуємо
його
покращення:
.Розрахуємо
його
покращення:
![]()
Величина 2,88 > означає, що за допомогою правила передбачити покупку велосипедної шапочки вірогідніше, ніж випадково його вгадати.
Як можна застосувати це правило на практиці? Це залежить від конкретних цілей. Приведемо декілька варіантів:
• Розмістити товари поряд на вітрині.
• Сформувати подарункові набори «Теніска + Шапочка».
• Сформувати подарункові набори «Теніска + Шапочка + Товар, що погано продається».
• Підніміть ціну на одне та зменшіть на інше.
• Замовте теніски та шапочки однакових кольорів тощо.