

Загальні методичні рекомендації
Постановка задачі - сегментація клієнтів.
На прикладі завдання по сегментації клієнтів телекомунікаційної компанії розберемо послідовність побудови та інтерпретації карт Кохонена в Deductor Studio.
В такій високотехнологічній галузі, як телекомунікації, методи і підходи Data Mining отримали широке застосування. В білінгових системах телекомунікаційних компаній накопичуються великі об'єми даних. Насамперед, це інформація про абонентів і статистика використаних послуг. Аналіз такої інформації ручними і напівручними методами малоефективний.
Цілями сегментації є:
1. побудова типових груп абонентів шляхом виявлення їх схожої поведінки в частоті, тривалості і часу дзвінків, а також щомісячних витрат;
2. оцінка найбільш і найменш прибуткових сегментів.
Ця інформація може надалі використовуватися для:
• розробки маркетингових акцій, направлених на певні групи клієнтів;
• розробки нових тарифних планів;
• оптимізації витрат по адресній sms-розсилці про нові послуги і тарифи;
• запобігання відтоку клієнтів в інші компанії.
Всі дані взяті з білінгової системи. Кожен клієнт характеризується наступними атрибутами:
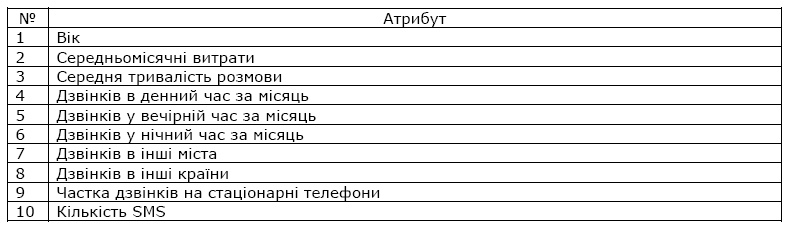
Отож, послідовність задачі сегментації абонентів буде вирішено способом, що включає в себе два кроки:
• кластеризація об'єктів алгоритмом Кохонена;
• побудова та інтерпретація карти Кохонена.
В Deductor алгоритм кластеризації і карта Кохонена реалізовані в однойменному обробнику Карта Кохонена.
Однак перед його застосуванням потрібно імпортувати файл «mobile.txt», який був створений. При імпорті файлу врахуйте особливості, з якими Ви ознайомились в попередніх роботах.
Після
цього запустіть Майстер обробки за
допомогою кнопки
![]() та виберіть обробник «Карта Кохонена».
та виберіть обробник «Карта Кохонена».
По-кроково виконайте всі наступні інструкції:
• На 2 кроці встановіть призначення всіх полів «Входное», крім «Код», якому слід встановити значення поля «Назначение» - «Информационное» (рис. 5.4).
Важлива примітка! Встановивши призначення поля, як «Вьіходное», можна прогнозувати його значення в майбутньому. Детальніше з цим Ви познайомитеся коли виповнятимете свій варіант завдання до даної лабораторної роботи.
• На 3 кроці вкажіть, що всі наявні значення будуть навчальними (рис. 5.5).
• На 4 кроці Майстра, де задається розмір та форма карти Кохонена, залиште всі параметри без змін. Пізніше ми з ними поексперементуємо і переконаємося, що вони мають суттєвий вплив на результат кластеризації.
• На 5 кроці Обробника вказуємо кількість епох (ітерацій 50). Зауважимо лише, що тут задаються параметри зупинки алгоритму, зокрема рівень помилки та максимальна кількість епох (ітерація або кроків прогонки даних), після чого алгоритм кластеризації зупиниться, навіть якщо і не досягне заданого рівня помилки.
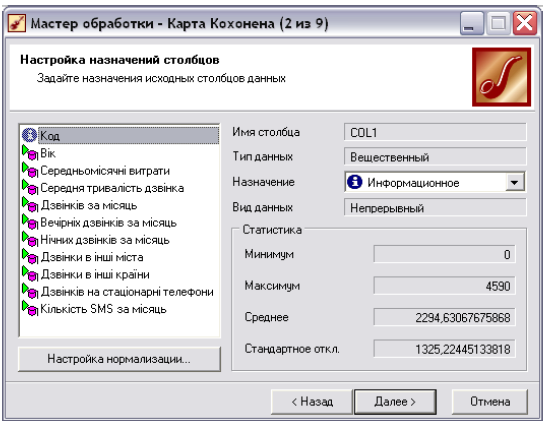
Рис. 5.4. Другий крок обробника «Карта Кохонена».
Рис. 5.5. Третій крок обробника «Карта Кохонена».
• На 6 кроці Обробника задається ряд важливих параметрів, серед них (рис. 5.6):
■ «Способ начальной инициализации карты» - параметр визначає яким чином будуть встановлені початкові значення нейронів алгоритму Кохонена. Параметр може набувати декілька значень: «случайными значениями», «из обучающего. множества» і «из собственных векторов». При виборі кожного з цих значень потрібно аналізувати три речі: об'єм навчальної вибірки, кількість епох відведених для навчання, розмір карти Кохонена. При цьому потрібно слідувати наступним правилам: 1) Якщо об'єм навчальної вибірки значно (у 100 і більше разір.) перевищує число точок карти, і час навчання не грає першочергову роль, то краще вибрати ініціалізацію «случайными значениями», оскільки це дасть меншу вірогідність попадання в локальний мінімум помилки кластеризації. 2) Якщо об'єм навчальної вибірки не дуже великий, обмежений час навчання або необхідно зменшити вірогідність появи після навчання порожніх точок (у яких не потрапило жодного екземпляра навчальної вибірки), то слід використовувати ініціалізацію «из обучающего множества». 3)Ініціалізацію «из собствєнных векторов» можна використовувати при будь-якому значені об'єму вибірки, кількості епох та розміру карти, однак є єдине зауваження: вірогідність появи порожніх точок на карті після навчання вища, ніж при ініціалізації прикладами «из обучающего множества».
■ «Скорость обучения» - задається швидкість навчання на початку і в кінці навчання мережі Кохонена. Рекомендовані значення: 0,1 - 0,3 на початку і 0,05 - 0,005 в кінці навчання.
■ «Клестеризация» - в цій секції вказуються параметри алгоритму k-means, який запускається після алгоритму Кохонена для кластеризації точок на карті. Тут потрібно тільки визначити, дозволити алгоритму автоматично визначити число кластерів або ж відразу зафіксувати його. Слід запам'ятати, що автоматично підібране число кластерів не завжди приводить до бажаного результату - число кластерів може бути дуже великим, тому розраховувати на цю опцію можна тільки на етапі дослідження даних.
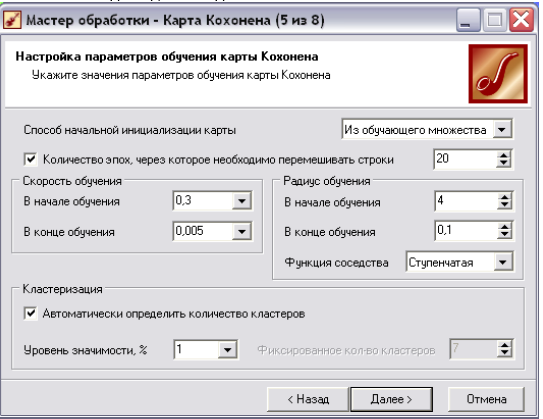
Рис. 5.6. Шостий крок обробника «Карта Кохонена».
•
На
7 кроці
Обробника слід просто натиснути кнопку
![]() і прослідкувати за процесом роботи
алгоритмом Кохонена. Зауважимо лише,
що даний процес потребує великого
процесорного ресурсу, тому на ПК в
лабораторії може зайняти деякий час.
і прослідкувати за процесом роботи
алгоритмом Кохонена. Зауважимо лише,
що даний процес потребує великого
процесорного ресурсу, тому на ПК в
лабораторії може зайняти деякий час.
До речі, в процесі роботи алгоритму Ви можете спостерігати на графіку, як зменшуємся помилка алгоритму (рис. 5.7).
• На передостанньому кроці - 8-ому - відмічаємо карти вхідних атрибутів (Вік тощо), що потрібно вивести на екран, а також додаткові карти, серед яких:
■ «Матрица расстояний» - застосовується для візуалізації структури кластерів, отриманих в результаті навчання карти. Велике значення точки говорить про те, що вона сильно відрізняється від тих, що її оточують і відноситься до іншого класу.
■ «Матрица ошибок квантования» - відображає середню відстань від розташування прикладів до центру осередку. Відстань вважається як евклідова відстань. Матриця помилок квантування показує, наскільки добре навчена мережа Кохонена. Чим менше середня відстань до центру осередку, тим ближче до неї розташовані приклади, і тим краще модель.
■ «Матрица плотности попадання» - відображає кількість об'єктів (абонентів), що потрапили в точку на карті.
■ «Кластеры» - точки карти Кохонена, об'єднані в кластери алгоритмом k-means.
■ «Проекция Саммона» - матриця, що є результатом проектування багатовимірних даних на площину. При цьому дані, розташовані поряд в
початковій багатовимірній вибірці, будуть розташовані поряд і на площині.
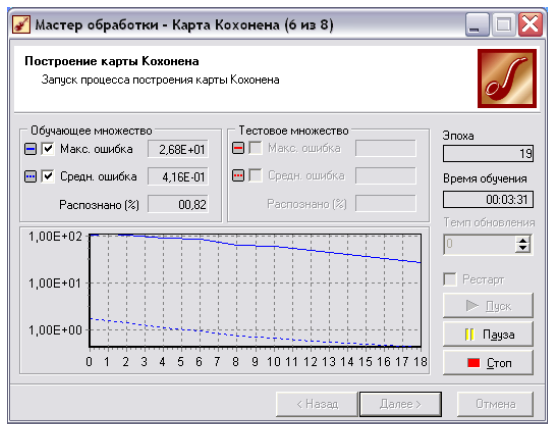
Рис. 5.7. Сьомий крок обробника «Карта Кохонена».
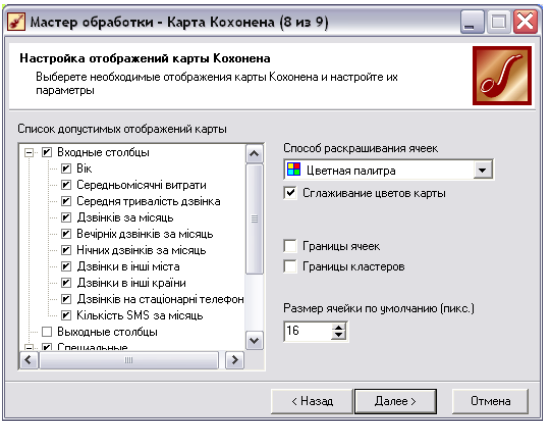
Рис. 5.8. Восьмий крок обробника «Карта Кохонена».
Крім того на рис. 5.8 справа показано ще ряд налаштувань, які допоможуть в роботі:
■ «Способ раскрашивания ячеек» - кольорова палітра або градація сірого. Кольорова палітра більш наочна, проте, якщо Вам потрібно помістити карту Кохонена на звіт з його подальшим друком на паперовий носій, то краще-вибрати сіру кольорову схему.
■ «Сглаживание цветов карты» - кольори на картах будуть згладжені, тобто буде плавний перехід кольорів. Це допоможе усунути випадкові викиди.
■ «Границы ячеек» - встановлення даної опції увімкне відображення границь точок на карті.
■ «Границы кластеров» - встановлення даної опції увімкне відображення границь кластерів на всіх картах, що дозволить зручно аналізувати структуру кластера.
■ «Размер ячейки» - вказує розмір точки на карті в пікселях (по замовчуванню 16).
Увага!!!
Змінити налаштування, що описані вище
(на рис. 5.4 – 5.8) можна, скориставшись
кнопкою
![]() .
.
Увага!!! Для вивчення базових принципів роботи з картами Кохонена перегляньте відеоролик «Vіdео_Коxоnеn.avi».
В результаті побудови карти Кохонена за описаним вище алгоритмом ми отримали карти, що зображені на рис. 5.9.
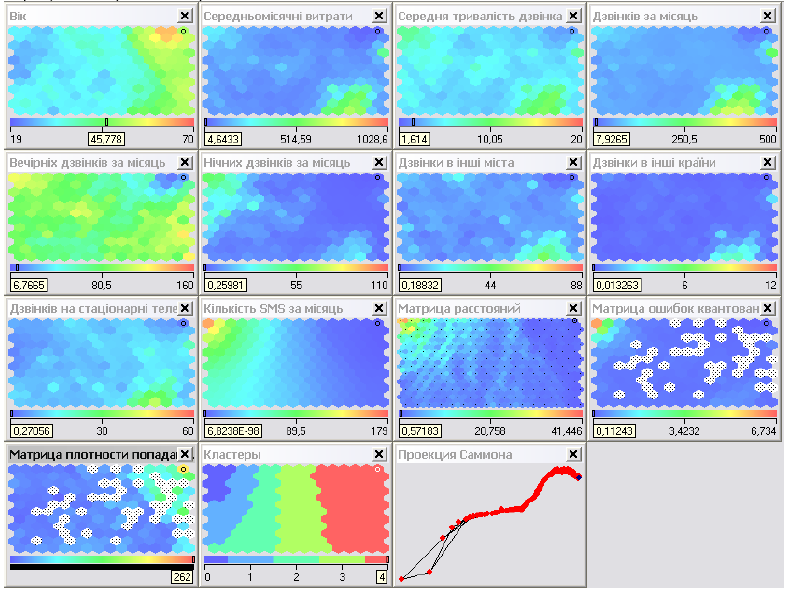
Рис. 5.9. Карти Кохонена розміром 16*12.
Відразу виникає питання: як оцінити якість проведеної кластеризації і чи є вона задовільною. Відмітимо, що одназначної відповіді тут немає, оскільки процес кластеризації є суб'єктивним і багато що залежить від вихідних даних.
В нашому випадку, виділивши оранжеву точку на «Матрице плотности попадання», ми переконаємось, що в одну точку на карті попало одночасно 262 об'єкта-абонента (рис. 5.10).

Рис. 5.10. «Матрица плотности попадання» для карт Кохонена розміром 16*12.
В той час, як в інші точки попало об'єктів-абонентів в інтервалі 10-40. Такі перепади кажуть про те, що деякі кластери можуть бути дуже загальними.
Отож, спробуймо побудувати нові карти Кохонена. Всі параметри будуть аналогічні, які і в першому випадку, але на 3 кроці роботи Майстра (рис. 5.11) слід вказати розмірність карти 24*18 (щоб збільшити кількість точок на карті), а на 5 кроці (рис. 5.16) в полі «Способначальной инициализации карты» слід залишити «Из обучающей выборки».
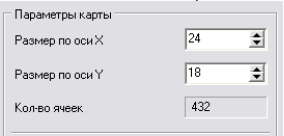
Рис. 5.11. Розмір карти 24*18
В результаті отримаємо новий результат кластеризації у вигляді карт, що зображені на рис. 5.12.
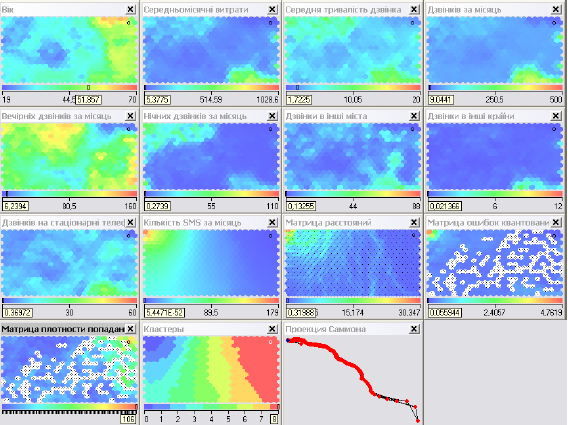
Рис. 5.12. Карти Кохонена розміром 24*18.
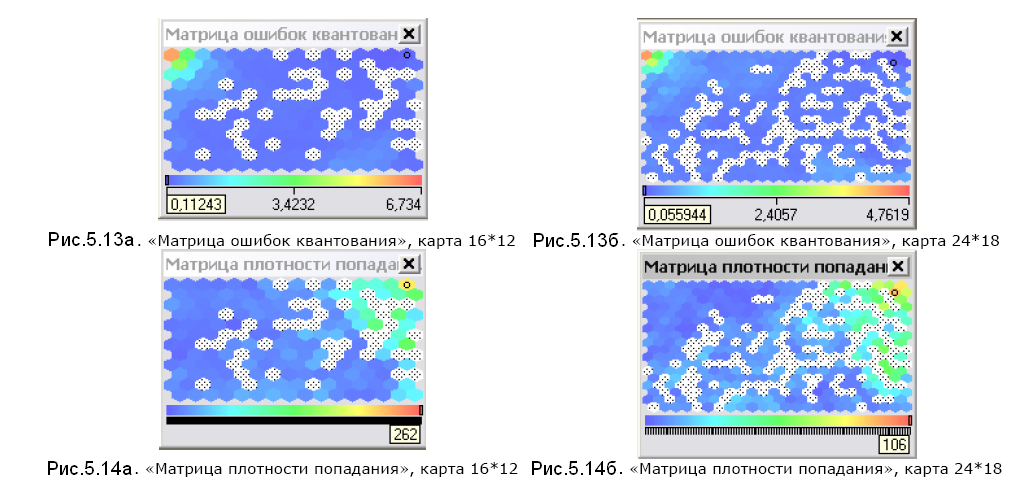
Зазначимо, що якість кластеризації в даному випадку є кращою. Такий висновок ми робимо порівнюючи «Матрицу ошибок квантования» та «Матрицу плотности попадання» для наших двох випадків кластеризації.
На рис. 5.13 видно, що у карти 16*12 помилки в інтервалі [0,45; 6,73], а у карти 24*18 -[0,05; 4,76]. На рис. 5.14 видно, що для карти 16*12 максимальна кількість об'єктів, що припадає на одну точку (оранжевого кольору), становить 262, а в карти 24*18 – 106.
Враховуючи все сказане вище, для подальшого аналізу будемо використовувати карти розміром 24*18.
Аналізуючи карту «Вік», ми можемо виділи 3 великі групи абонентів: старший та пенсійний вік, абоненти середнього віку та молодь (рис. 5.15).
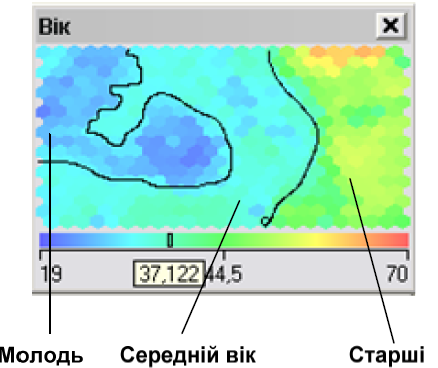
Рис. 5.15. Виділення вікових груп.
Розглянемо детальніше групу молоді. Тут ми можемо виділити декілька кластерів. Абоненти першого з них, характеризуються (рис. 5.16):
• Середнім віком більше 24 років.
• Середній витрати 80-250 грн.
• Часто розмовляють вдень (карта «Дзвінків за місяць»).
• Мають порівняно велику тривалість дзвінків.
• Багато спілкуються вечері і вночі (молодь, яка розважається).
• Багато спілкується через SMS.
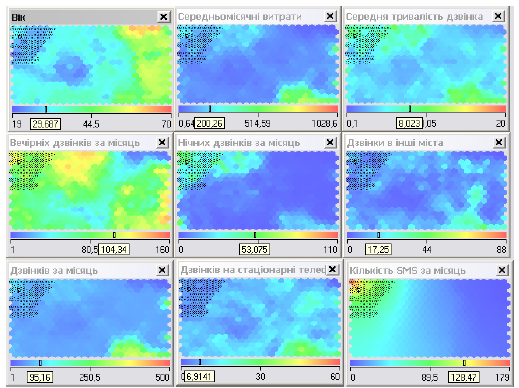
Рис. 5.16. Кластер «Молодь після 24».
Другим кластером серед молоді будуть ті, хто мало використовують мобільний (рис. 5.17).

Рис. 5.17. Кластер «Неактивна молодь».
Для них характерно: низькі витрати на мобільний зв'язок, низьку тривалість дзвінків, невелику кількість дзвінків як в день, так і у вечері, і вночі. Припустимо, що до цієї групи відноситься більшість студентів.
Далі цікаво проаналізувати групу людей старшого віку. Тут є цікаві спостереження.
Кластер, що знаходиться в правому нижньому кутку (рис. 5.18). В цьому кластері по всім характеристикам, крім SMS, спостерігаються високі показники. Це так звані УІР-клієнти: бізнесмени, керівники, топ-менеджери. Вони переважно зрілого віку, дуже багато розмовляють вдень і у вечірній час (скоріше за все по роботі), часто телефонують на стаціонарні телефони та в інші міста. Відповідно цей кластер має високі витрати на послуги мобільного зв'язку.
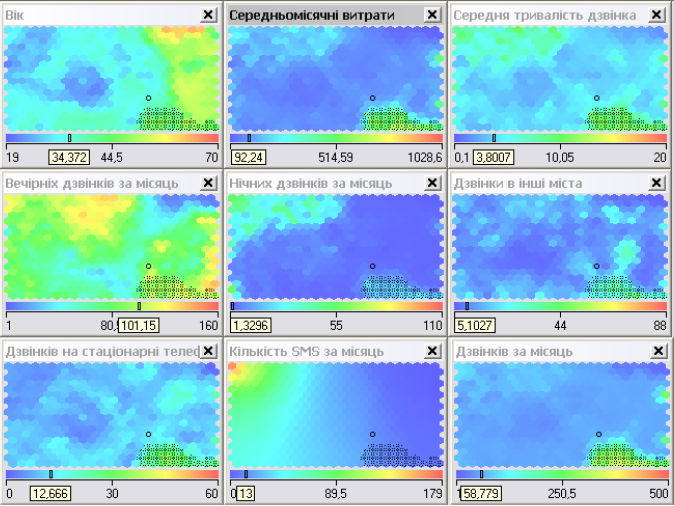
Рис. 5.18. Кластер «УІР-клієнти».
Протилежно даному кластеру, в самому верху знаходиться інша група людей зрілого віку (рис. 5.19), для яких характерна мала кількість дзвінків вдень, ввечері та вночі, відісланих SMS повідомлень. Відповідно цей кластер має низькі витрати на мобільний зв'язок. З високою долею ймовірності можна стверджувати, що до цього кластеру відносяться пенсіонери та люди похилого віку, які в основному використовують телефон лише для прийому дзвінків.
Для
підтвердженням нашої гіпотези виділимо
цей кластер, як показано на рис. 5.19.
На панелі інструментів натиснемо кнопку
«Показать/скрыть окно данных (F4)»
![]() На панелі інструментів таблиці, що
з'явилася в нижній частині вікна натиснемо
кнопку
На панелі інструментів таблиці, що
з'явилася в нижній частині вікна натиснемо
кнопку
![]() і виберемо
і виберемо
![]() .
Після цього клацнувши ПКМ по таблиці
виберемо «Настройка параметров» і з
усіх можливих значень залишимо тільки
«Среднее». В результаті отримаємо
таблицю (рис. 5.20), на якому показано
середні показники, що характеризують
виділений кластер і підтверджують нашу
гіпотезу.
.
Після цього клацнувши ПКМ по таблиці
виберемо «Настройка параметров» і з
усіх можливих значень залишимо тільки
«Среднее». В результаті отримаємо
таблицю (рис. 5.20), на якому показано
середні показники, що характеризують
виділений кластер і підтверджують нашу
гіпотезу.
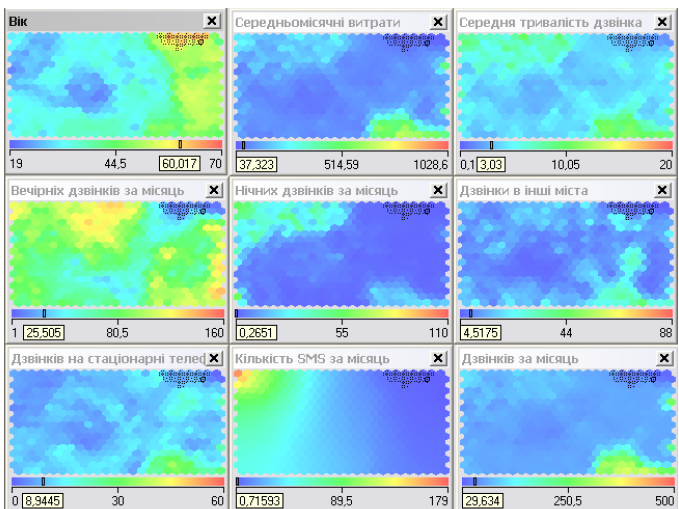
Рис. 5.19. Кластер «Пенсіонери
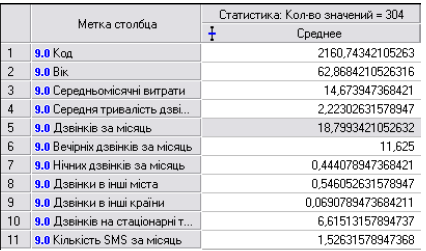
Рис. 5.20. Середні значення характеристик абонентів, що попали в кластер «Пенсіонери».
Таким чином можна продовжувати аналіз карт Кохонена, допоки вся площина карти не буде поділена по кластерах.
Варто зазначити, що Deductor дозволяє самостійно утворювати кластери з точок на карті Кохонена. Робиться це за допомогою алгоритму k-середніх. Утворені кластери відображаються на окремій карті, яка так і називається «Кластеры» (рис. 5.21).
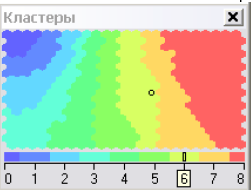
Рис. 5.21. Карта «Кластеры».
Як
видно з рис. 5.21, не всі кластери, що
утворені автоматично програмою,
відповідають тим, які виділили ми раніше.
Проте тут також можна експериментувати.
Для цього слід скористатися кнопкою
«Настроить кластеры»
![]() .
У вікні, що з'явиться можна задати не
автоматичне визначення кількості
кластерів, а їх примусову кількість.
.
У вікні, що з'явиться можна задати не
автоматичне визначення кількості
кластерів, а їх примусову кількість.

Увага!!! Виділення кластерів користувач здійснює самостійно на основі власних міркувань та гіпотез, а також кластерів, які утворила програма. Ще раз наголосимо, що утворені програмою кластери можуть бути різні, в залежності від того, як побудуємо карти Кохонена з самого початку.
Порядок виконання роботи
Створіть або загрузіть в Deductor свій варіант завдання.
Побудуйте карти Кохонена, зробіть аналіз по всі крокам.
Побудуйте карти Кохонена розміром 24*18 і 16*12. Проаналізуйте отримані результати.
Зробіть аналіз по карті «Кластери»
Побудуйте «Матрица плотности попадання» для карт Кохонена.
Звіт про лабораторну роботу
Звіт містить наступні результати:
1.Титульний лист.
2.Мета роботи.
3.Варіант студента.
4.Опис кожного зробленого завдання згідно свого варіанту;
5.Скриншоти кожного зробленого завдання згідно свого варіанту;
6.Висновки.
Контрольні запитання
1.Що таке кластеризації?
2.Дайте визначення картам Кохонена?
3.Назвіть цілі сегментації?
4. Що таке «Скорость обучения»?
5. Що таке «Кластеризация»?
6. Що таке «Кластер»?
7. «Проекция Саммона» - це ?
Лабораторна робота № 6.
Знаходження асоціативних правил в аналітичній платформі Deductor.
Мета роботи: навчитися знаходити асоціативні правила і будувати за допомогою засобів аналітичної платформи Deductor.