

Лабораторна робота № 4 Групова обробка. Управління розташуванням вікон.
Мета роботи: навчитися працювати з груповою обробкою і отримати навики в управлінні розташуванням вікон Deductor.
Загальні методичні рекомендації
Вузол Групова обробка працює схожим на Скрипт чином. Основною відмінністю від нього є те, що вхідний набір ділиться на частини по вказаних групах, і потім кожна група окремо «проганяється» через копію ланцюжка вузлів обробки.
Якщо аналогом скрипта є процедура в мові програмування, то аналогом групової обробки - цикл. Групова обробка дозволяє створювати дуже гнучкі сценарії, особливо вона незамінна в тих випадках, коли потрібно обробляти окремі «пачки» даних усередині одного набору залежно від статистичних характеристик кожній такої «пачки» (сума, середнє, кількість записів і так далі).
Розглянемо групову обробку на конкретному прикладі. Імпортуємо в Deductor текстовий файл Trade.txt (за умовчанням він розташований в каталозі /Samples). Фрагмент набору даних приведений нижче в таблиці.
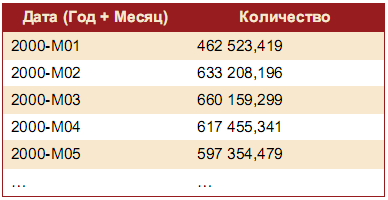
Відсортуємо його за збільшенням по полю Дата (Рік + Місяць). Далі з цього поля вузлом Калькулятор виділимо рік, створивши нове поле з функцією
SUBSTR(COL1;1;4).
Хай перед нами коштує завдання: розрахувати для кожного місяця кожного року (тобто, по суті, рядки набору даних) частку і частку з накопиченням від річної суми в межах одного року. Ситуація характеризується тим, що у нас не один рік, а декілька: з 2000 по 2004.
Скористаємося Груповою обробкою. Для наочності спочатку виконаємо всі необхідні дії над однією групою, скажімо, 2000 рік, а потім «розповсюдимо» ці дії на весь початковий набір даних.

Спершу ми виділили цю групу фільтром і послідовно додали два поля двома калькуляторами: Частка (PART):
ROUND(COL2/Stat("COL2';"SUM')*100;2)
і частка, що Накопичується (CUM_PART):
Cumulativesum(“PART”).
Далі додамо до початкового набору даних вузол Групова обробка. На першому кроці потрібно вказати поля для визначення груп при обробці даних. У нашому випадку це поле Рік (рис.4.1).
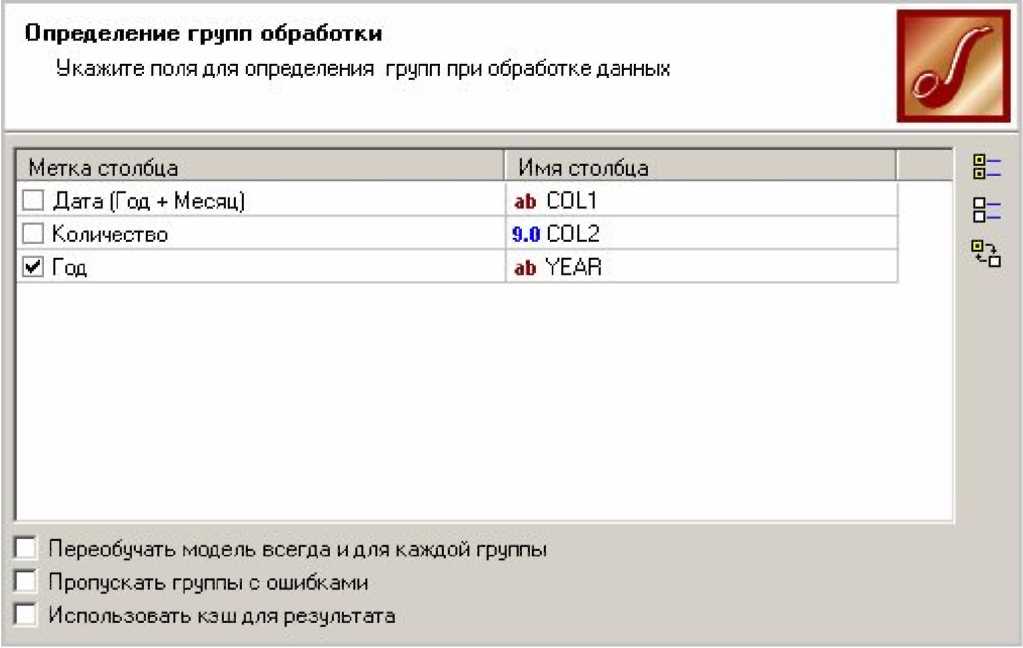
Рис. 4.1. Вікно визначення груп обробки
На наступній вкладці вкажемо початковий етап обробки - вузол з міткою Калькулятор: Частка (рис. 4.2).
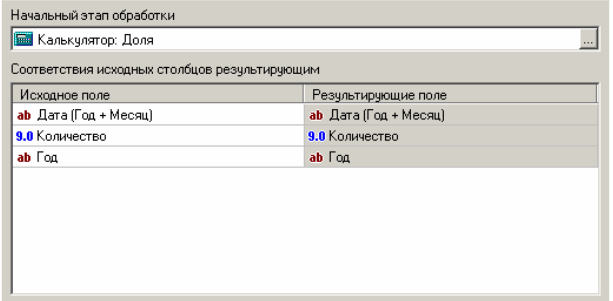
Рис. 4.2. Вікно калькулятора етапу обробки
Кінцевим вузлом буде Калькулятор: Частка, що накопичується (рис. 4.3).
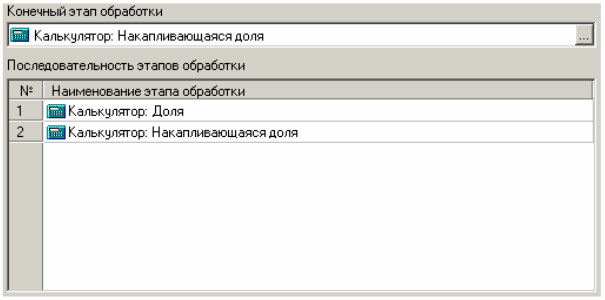
Рис. 4.3. Кінцевий етап калькулятора
В результаті групової обробки отримаємо наступний набір даних (на малюнку зображений фрагмент набору) (рис.4.4).
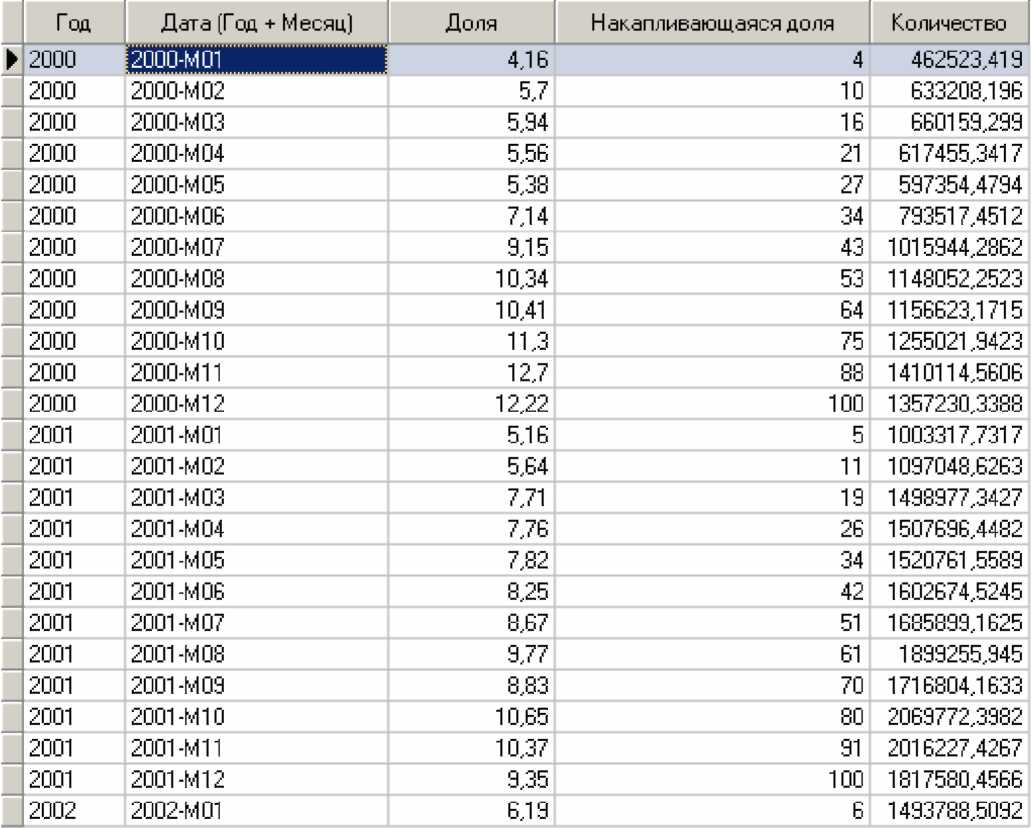
Рис. 4.4. Фрагмент набору
Зверніть увагу - частка, що накопичується, доходить до 100% в кожному році, і «скидається» з початком нового року. Таким чином, ми отримали бажаний результат. групової обробки отримати це було б набагато складніше.
На першій вкладці майстра настройки вузла були доступні три опції. Розберемо їх детальніше.
Прапор Перенавчати модель завжди і для кожної групи актуальний, коли в ланцюжку вузлів, на які посилається групова обробка, є які-небудь моделі - лінійна регресія, нейронна мережа і так далі. Тому у разі простих дій - Калькулятор, Фільтр, Заміна даних, Сортування та інші - на даний прапор не потрібно обертати уваги.
Прапор Пропускати групи з помилками виключить з результуючого набору групи, «прогоні» яких через ланцюжок вузлів виникла помилка. У переважній більшості випадків це буває також за наявності в ланцюжку вузлів яких-небудь моделей, тому при простих діях прапор ставити не потрібно.
Прапор Використовувати кеш для результату визначає один з двох варіантів функціонування вузла: «без використання кешування» і «з використанням кешування».
Кеш - це підбірка даних, дублюючих оригінальні значення, збережені десь або обчислені раніше, коли оригінальні дані труднодоступні із-за великого часу доступу або для обчислення. Багато програм записують куди-небудь проміжні або допоміжні результати роботи, щоб не обчислювати їх кожного разу, коли вони знадобляться. Це прискорює роботу, але вимагає додаткової пам'яті (оперативною або дисковою).
Кеш потрібний для економії пам'яті. Це необхідно, коли груп обробки багато і кожна група вимагає великих обчислювальних витрат. Великі обчислювальні витрати, як правило, виникають при перенавчанні моделей - перерахунку коефіцієнтів регресії, підборі вагів нейронної мережі і так далі. Тому тут порада наступна. Коли груп небагато і в ланцюжку вузлів «прогону» груп немає моделей, то кеш не потрібний. У інших випадках краще поставити прапор з кешем.
За замовчуванням при відкритті Deductor Studio панель управління розташовується зліва, а область візуалізаторів - справа. Проте за допомогою миші можна відстикувати панель управління і розташувати в будь-якому місці екрана.
У меню ВІКНО доступні наступні команди по відображенню вікон:
• каскадом -вікна розташовуються одне за іншим але так, що для всіх вікон видно рядок заголовка. Клацання по ній робить вікно активним і переводить його на передній план.
• горизонтально-в результаті цієї команди відкриті вікна з даними розташовуються поруч без перекриття по горизонталі.
• вертикально - розташувати вікна зданими вертикально. Вікна розташовуються поруч без перекриття по вертикалі.
• згорнути все - згортає всі вікна з даними до розмірів кнопок в нижній частині вікна програми. Щоб повернути вікно в попередній стан досить клацнути по відповідній кнопці йому.
• закрити все - закриває всі вікна в області візуалізаторів.
Кожен відкритий визуализатор вузла займає певну кількість перативної пам'яті комп'ютера. Тому на комп'ютерах з невеликою кількістю оперативної пам'яті не рекомендується відкривати одночасно багато візуалізаторів (рис.4.5).
Рис. 4.5. Доступні компоненти
В Deductor Studio є безліч механізмів імпорту, експорту, обробки та візуалізації, а також джерел даних, але не у всіх з них є потреба при розробці сценаріїв. Іноді бажано відключити видимість тієї чи іншої компоненти, причому це стосується тільки доступності методів при виклику майстрів налаштування. Тобто якщо в сценарії вже використовується якийсь із прихованих механізмів, то він все одно буде відображений і виконаний, але при виклику майстра для додавання нового дії в сценарій цей механізм не буде відображатися.
Відключаючи непотрібні в даний момент дії можна значно спростити роботу з побудови сценаріїв.
Налаштувати доступні компоненти можна в меню Сервіс→Компоненти ... видимість можна як у окремих компонентів, так і у цілої групи.
За замовчуванням всі компоненти видимі.
Обрані вузли.
Дуже часто при створенні сценаріїв значна частина роботи ведеться з декількома ключовими вузлами, в яких і визначаються найбільш важливі параметри обробки. Для спрощення роботи з ними, зокрема для того, щоб їх було легше знайти у великих проектах в Deductor Studio реалізована робота з обраними вузлами. Обраним може бути любий сценарій.

Для того щоб додати виділений вузол у Вибране:
• «Схопити» вузол мишкою та перетягнути його в область вибраних на головній панелі програм, виділений на малюнку червоним.
• Контекстне меню Додати у вибране на вкладці Сценарії.
• Головне меню Вибране →Додати у вибране.
При додаванні вузла у Вибране існує можливість задати йому закладку - текстовий опис. За замовчуванням закладка збігається з міткою вузла.
Для переходу до вибраного вузла:
• Вибрати його із списку на головній панелі інструментів.
• Викликати
кнопкою
![]() вікно Вибране,
вибрати вузол і натиснути кнопку Перейти.
вікно Вибране,
вибрати вузол і натиснути кнопку Перейти.
Файли конфігурації.
У файлі конфігурації зберігається інформація про налаштованих джерелах даних. За замовчуванням файл конфігурації називається Connections.sys і знаходиться в каталозі Мої документь\Deductor. Ці установки можна перевизначити, відкривши вікно командою головного меню Сервіс→Налаштування ...
Документація і демоприклади Deductor Studio.
У постачанні Deductor Studio, крім довідкової системи, йде комплект документації та демоприкладів. Відкрити список документації можна з меню Windows Пуск→Deductor→Документація. Основним документом для аналітика є Керівництво аналітіка. При вирішенні завдань консолідації та збору інформації аналітику може знадобитися Керівництво з імпорту та експорту.
Демоприклади розташовуються в директорії \ Samples каталогу установки Deductor.