

Лабораторна робота № 3
Калькулятор. Використання скриптів.
Мета роботи: навчитися працювати з калькультором і скриптами в програмному пакеті Deductor.
3.1. Загальні методичні рекомендації
Калькулятор - призначений для додавання в набір даних нових полів, які розраховуються по певних правилах на основі стовпців даних і вбудованих функцій.
Обробник Калькулятор (рис.3.1) знаходиться в групі вузлів Інше майстри обробки. Вся настройка здійснюється у вікні майстра Конструктор виразу.
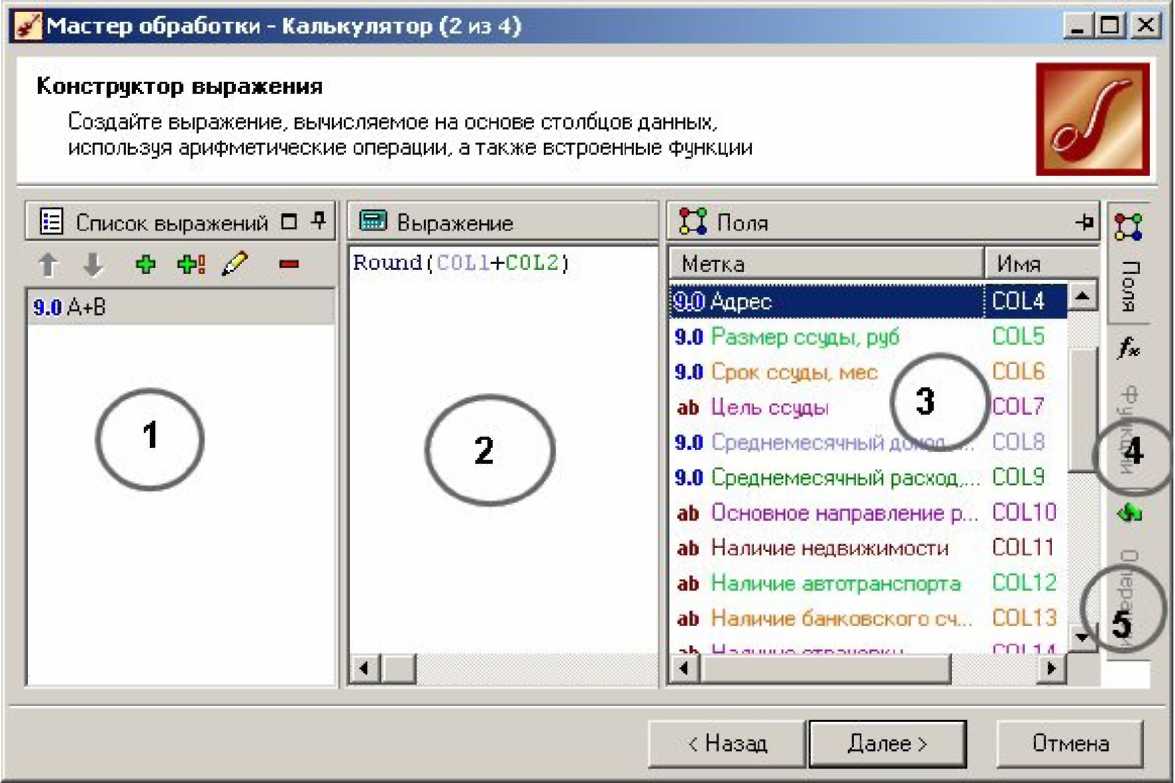
Рис. 3.1. Вікно калькулятора
1 - область списку обчислюваних виразів. Кожен обчислюваний вираз буде новим стовпцем в результуючому наборі даних.
2 - формула, по якій розраховуватиметься вираз (вікно виразу).
3 - список всіх існуючих стовпців поточного набору даних, що складаються з імен і міток. Для кожного стовпця показується ім'я і мітка.
4 - відкриває вкладку із списком вбудованих функцій.
5 - відкриває вкладку із списком доступних арифметичних, логічних і інших операцій.
Область списку обчислюваних виразів спочатку містить один порожній вираз. Для управління списком обчислюваних виразів передбачені наступні кнопки:
![]() (Ctrl
+ Up)
- перемістити поточний вираз на одну
позицію вгору за списком.
(Ctrl
+ Up)
- перемістити поточний вираз на одну
позицію вгору за списком.
![]() (Ctrl
+ Down)
- перемістити поточний вираз на одну
позицію вниз за списком.
(Ctrl
+ Down)
- перемістити поточний вираз на одну
позицію вниз за списком.
![]() (Num+
) - додати новий вираз з параметрами, що
встановлюються за умовчанням, і порожньою
формулою.
(Num+
) - додати новий вираз з параметрами, що
встановлюються за умовчанням, і порожньою
формулою.
![]() -
додати новий вираз з типом даних, описом
і формулою як у поточного вираза.
-
додати новий вираз з типом даних, описом
і формулою як у поточного вираза.
![]() (Num-)
- видалити поточний вираз.
(Num-)
- видалити поточний вираз.
Подвійним клацанням миші на імені виразу в списку викликається Діалогр редагування параметрів виразу (рис.3.2).
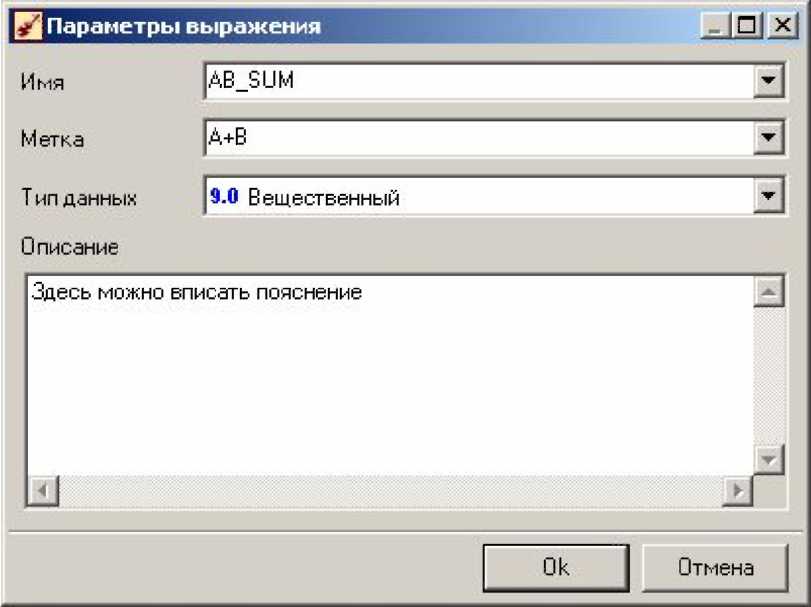
Рис. 3.2. Вікно параметрів виразу
● Ім'я - рядок, який служитиме ідентифікатором стовпця в процедурах обробки. Може складатися тільки з латинських символів і повинно бути унікальним в межах одного набору даних.
● Мітка - мітка нового стовпця. Саме вона відображається в списку обчислюваних виразів. Унікальність міток не потрібна.
● Тип даних - тип даних обчислюваного виразу. Тип вибирається із списку, що відкривається клацанням по кнопці в правій частині поля.
● Опис –довілним способом інформація, що описує обчислюваний вираз.
Спочатку при відкритті сторінки Конструктора список виразів містить тільки один новий стовпець. За умовчанням для нового виразу призначається мітка Вираз_ N, де N -номер, що забезпечує унікальність. Імена полів, формованих в результаті обчислень поданому виразу, призначаються автоматично і мають вигляд: Expr_ N.
Далі потрібно ввести формулу, що розраховується, у вікно виразів. Правила складання виразів відповідають загальноприйнятим в математиці, зокрема, число відкриваючих дужок повинне дорівнювати числу тих, що закривають. Вираз може містити:
■ Числа в явному вигляді.
■ Змінні у вигляді імен стовпців.
■ Дужки, що визначають порядок виконання операцій.
■ Знаки математичних операцій і відносин.
■ Імена функцій.
■ Дати у форматі ДД.ММ.РР, обов'язково указувані в лапках. Такий спосіб введення дати, хоча і допускається, але може виявитися не переносимим між різними комп'ютерами. З цієї причини краще використовувати функцію STRTODATE().
■ Строкові вирази в подвійних лапках: "строковий вираз".
■ Однорядкові і багаторядкові коментарі. Однорядковий коментар починається символами // (два слеша) і продовжується до кінця рядка. Багаторядковим коментарієм вважаються всі символи, що містяться між дужками /* і */ (зірочка-слеш).
Вираз можна ввести уручну з клавіатури, проте зручніше вибирати функції, змінні і знаки операцій за допомогою миші. Для додавання у формулу функцій слід справа вибрати вкладку Функції. Всі функції в ній згруповані по видах (рис. 3.3).

Рис. 3.3. Вікно функцій калькулятора
Щоб ввести функцію у вираз, достатньо двічі клацнути по її імені в списку, або, утримуючи, перетягнути її мишею в потрібну область формули. Ім'я функції у виразі з'являється разом з дужками, куди слід ввести аргумент або аргументи. Аргументами можуть бути числа в явному вигляді, рядки в лапках, дати в лапках, імена функцій, імена полів, а також арифметичні, логічні і строкові вирази. Імена полів зручно вводити за допомогою подвійного клацання в списку полів. Якщо в аргументі декілька полів, то їх імена розділяються крапкою з комою.
У вікні введення виразу можна вивести підказку - комбінація клавіш Ctrl + пропуск.
При створенні формул при розробці сценаріїв дуже часто використовуються функції IF і IFF.

У тому випадку, коли потрібно створити два нові стовпці Поле1 і Поле2, а Поле2 розраховується на основі Поля1, необхідно створити два вузли типу Калькулятор.
Особливість роботи вузла при виникненні помилок.
Створення нові поля за допомогою Калькулятора на якому-небудь наборі даних не означає, що надалі не виникнуть помилки при розрахунку значень. Наприклад, формула мала вид Поле1/Поле2. Що буде, якщо в Поле2 опиниться нульове або порожнє значення? Вузол Калькулятор має наступне правило роботи в таких ситуаціях: при виникненні будь-якої помилки в розрахунку значення запису в поле, що розраховується, заноситься значення NULL (порожнє значення) і повідомлення про помилку не видається. Це потрібно враховувати при розробці і відладці сценаріїв. У разі, коли формула в Калькуляторі посилається на неіснуючий стовпець, то буде видано повідомлення типу:
«Стовпець "Ім'я" ("Назва") повинен існувати в початковому джерелі даних»
і вузол не буде виконаний. Таке може трапитися, наприклад, коли набір даних, Калькулятор, що знаходиться над вузлом, поміняв свою структуру або імена полів.
Скрипти призначені для автоматизації процесу додавання в сценарій однотипних гілок обробки. Це потрібно в наступних випадках:
► потрібно виконати частину сценарію (тобто послідовність вузлів) на іншому наборі даних;
► потрібно застосувати модель (дерево рішень, нейрона сітка) на нових даних.
Якщо повторне виконання частини сценарію можна обійти, використовуючи копіювання віток, то у разі застосування аналітичної моделі до нових даних без обробника Скрипт обійтися неможливо.
По суті скрипт є динамічною копією вибраної ділянки сценарію. Скрипта є готовою частиною сценарію, і тому вхідні в нього вузли не можуть бути змінені окремо від початкової вітки сценарію. Проте, в скрипті відбиваються всі зміни, що вносяться до вітки, на яку він посилається, тобто при перенавчанні або перенастроюванні вузлів цієї вітки всі зроблені зміни будуть внесені до роботи скрипта.
Припустимо, що після імпорту даних з двох різних текстових файлів потрібно провести певну передобробку (поміняти назви стовпців, замінити дані, додати декілька розрахунковий стовпців), а потім експортувати отримані дані назад. Для першої гілки (першого текстового файлу) ці дії проводяться як завжди - послідовними кроками будується ланцюжок обробників. Для іншого ж джерела (іншого файлу) досить створити вузол імпорту, до якого приєднати вузол Скрипт, заснований на вже побудованій першій гілці. У цьому скрипті будуть виконані такі самі дії, як в оригінальній гілці. На виході скрипта ставиться вузол експорту, і друга гілка обробки готова до використання. Цю ідею ілюструє малюнок нижче.
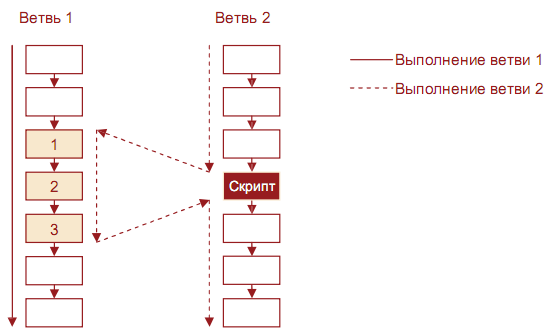
На малюнку показана схема виконання гілки з скриптом, що включає три вузли з іншої вітки сценарію. Спочатку (до вузла з скриптом) послідовно виконуються вузли другої вітки. Потім здійснюється перехід на початковий вузол скрипта, що знаходиться в Гілці 1. Далі послідовно виконуються вже вузли першої вітки, поки не буде досягнутий кінцевий вузол скрипта. Після цього здійснюється повернення до Гілки 2 на наступний після скрипта етап обробки, і виконання продовжується. На хід виконання першої гілки скрипт при цьому не робить ніякого впливу.
Особливість використання скрипта замість копіювання гілки полягає в тому, що внесені до головної гілки зміни автоматично успадковуються всіма скриптами, які посилаються на вузли головної гілки. В більшості випадків це перевага, проте, іноді при створенні сценаріїв необхідне саме копіювання вузлів.
Аналогом скрипта є функція або процедура в мовах програмування. Гілка обробки будується один раз, а потім скриптами вона тиражується в інші місця сценарію.
Обробник Скрипт знаходиться в групі вузлів Інше.
Створення і настройка скрипта
Настройка скрипта складається з наступних кроків.
Крок 1. Завдання початкового вузла обробки і відповідності полів. Це здійснюється у вікні Настройка початкового етапу і відповідності стовпців майстра обробки вузла Скрипт.
Для
вибору початкового вузла потрібно
натиснути кнопку
![]() ,
після чого на екрані з'явиться вікно
Вибор
вузла.
У цьому вікні показано все дерево
сценарію. Кнопка Ok
підтверджує вибір поточного вузла як
початковий вузол скрипта, кнопка Відміна
закриває вікно, не вносячи змін.
,
після чого на екрані з'явиться вікно
Вибор
вузла.
У цьому вікні показано все дерево
сценарію. Кнопка Ok
підтверджує вибір поточного вузла як
початковий вузол скрипта, кнопка Відміна
закриває вікно, не вносячи змін.
При виборі початкового вузла існують наступне обмеження: початковим вузлом може бути тільки вузол обробника (вузол імпорту або експорту даних не може бути вибраний) (рис.3.4).

Рис. 3.4. Вікно майстра обробки
У разі, коли початковий набір даний має менше число стовпців, чим початковий компонент ланцюжка, на екран буде видано попередження:
кількість стовпців початкового компоненту ланцюжка не повинна бути більш ніж кількість стовпців початкового набору данньх.
При цьому у момент обробки скрипта буде прийнята спроба виконати з наявним набором полів. Якщо якесь з відсутніх полів є критичним для будь-якого вузла, що міститься в скрипті, то обробка буде зупинена з видачею повідомлення про помилку. Під початковим набором даних мається на увазі той набір даних, до якого застосовується обробник Скрипт, під початковим компонентом ланцюжка - набір даних, на який настроюється Скрипт.
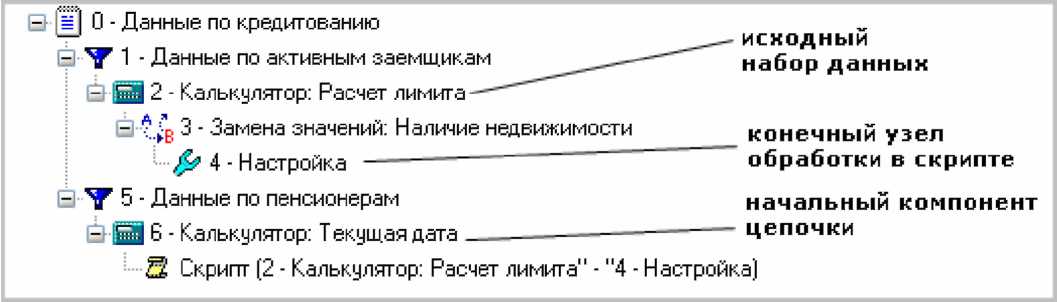
Після вибору початкового вузла слід задати відповідності стовпців початкового набору даних полям вибраного вузла. У нижній частині екрану знаходиться таблиця із списком полів початкового набору в лівому стовпці і полів вибраного вузла - в правом. Для кожного поля початкового вузла треба задати поле-джерело початкового набору. Для цього слідує, клацнувши двічі в лівому стовпці напроти імені потрібного поля, вибрати з випадного списку ім'я стовпця вхідного набору.
Майстер обробки вузла Скрипт влаштований так, що намагається автоматично зіставити поля в джерелах, співпадаючі по назві і/або типу.
Набудувати відповідності стовпців, які мають різний тип, неможливо. Виключення є тільки для типів цілий і речовий, проте рекомендується завжди настроювати відповідність стовпців, що мають однаковий тип (тобто цілий-цілий, речовинний-речовинний).
Можлива ситуація, коли стовпцям початкового компоненту ланцюжка немає зіставних стовпців в початковому наборі даних. У такій ситуації система видасть наступне повідомлення: «Стовпцям початкового компоненту ланцюжка не можна зіставити стовпці початкового набору даних». При цьому у момент обробки скрипта буде прийнята спроба виконати з наявним набором полів. Якщо якесь з відсутніх полів є критичним для будь-якого вузла що міститься в скрипті, то обробка буде зупинена з видачею повідомлення про помилку.
Крок 2. Етап настройки інформаційних полів. Це необов'язковий крок майстра, який з'являється у тому випадку, коли початковий набір даних містить більша кількість полів, чим набір даних, що є початковим компонентом ланцюжка. Під інформаційними полями розуміються ті поля, які не використовуватимуться в скрипті, але які будуть поміщені в результуючий набір даних (рис. 3.5).
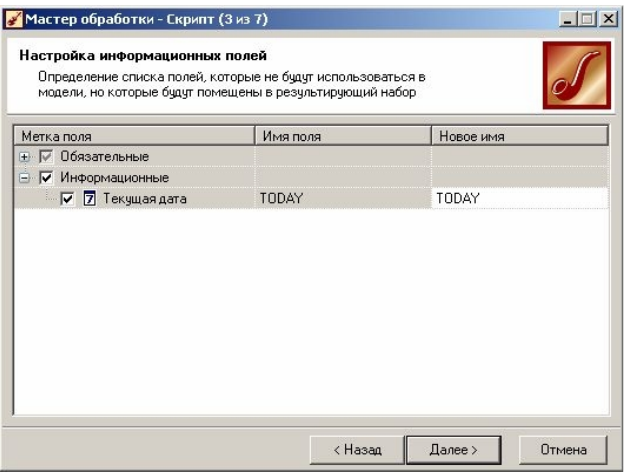
Рис. 3.5. Вікно настройки інформаційних полів
Крок 3. Завдання кінцевого вузла обробки. Тут існують наступні правила.
● Початковий і кінцевий вузли повинні знаходиться на одній гілці сценарію, тобто кінцевий вузол повинен бути нащадком початкового вузла в дереві сценарію.
● Кінцевим вузлом не може бути вузол експорту.
● На число і типи проміжних вузлів не накладаються ніяких обмежень, тобто проміжними вузлами можуть бути і скрипти.
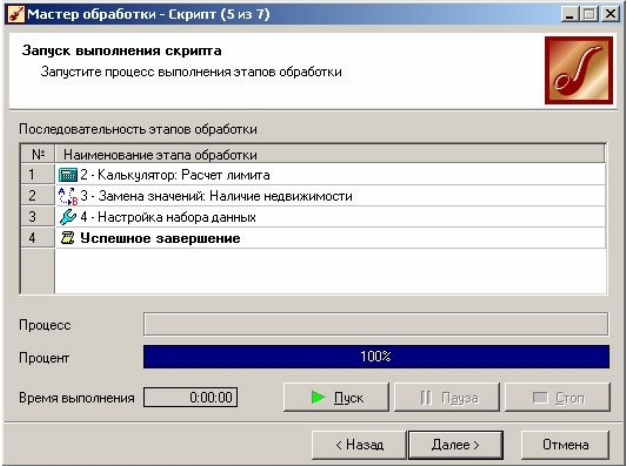
Крок 4. Запуск процесу обробки. На даному кроці запускається власно процес виконання скрипта.
У секції Послідовність етапів обробки показаний список всіх вузлів, що входять в скрипт. Вузли, які ще не виконувалися, відображаються з сірими іконами, виконані - з кольоровими. Ім'я поточного оброблюваного вузла відображається жирним шрифтом.
Якщо процес обробки зупинився, це сигналізує про можливі проблеми. Зупинка може відбутися у разі невідповідності типів даних алгоритму обробки, наявність в оброблюваних полях неприпустимих значень і так далі В цьому випадку можлива поява вікна з повідомленням про помилку. Якщо обробка даних була завершена успішно, то в секції Назва процесу з'явиться повідомлення «Успішніше завершення» (рис.3.6).
 \
\
Рис. 3.6. Вікно запуску виконання скрипта