

Лекція 8. Тема: Специфікації програмного забезпечення при структурному підході
Специфікації є повним і точним описом функцій і обмежень майбутнього програмного забезпечення [31]. При цьому одна частина специфікацій (функціональні) описує його функції, а інша частина (експлуатаційні) визначає вимоги до технічних засобів, до надійності, інформаційної безпеки і інш. Стосовно функціональних специфікацій маються на увазі наступні вимоги:
• вимога повноти означає, що специфікації повинні містити всю істотну інформацію, де нічого важливого не було б упущено, і відсутня неістотна інформація, наприклад деталі реалізації, щоб не перешкоджати розробникові у виборі найбільш ефективних рішень;
• вимога точності означає, що специфікації повинні однозначно сприйматися як замовником, так і розробником.
Останню вимогу виконати досить складно внаслідок того, що природна мова для опису специфікацій не підходить: навіть докладні специфікації на природній мові не забезпечують необхідної точності. Точні специфікації можна визначити, тільки розробивши деяку формальну модель майбутнього програмного забезпечення.
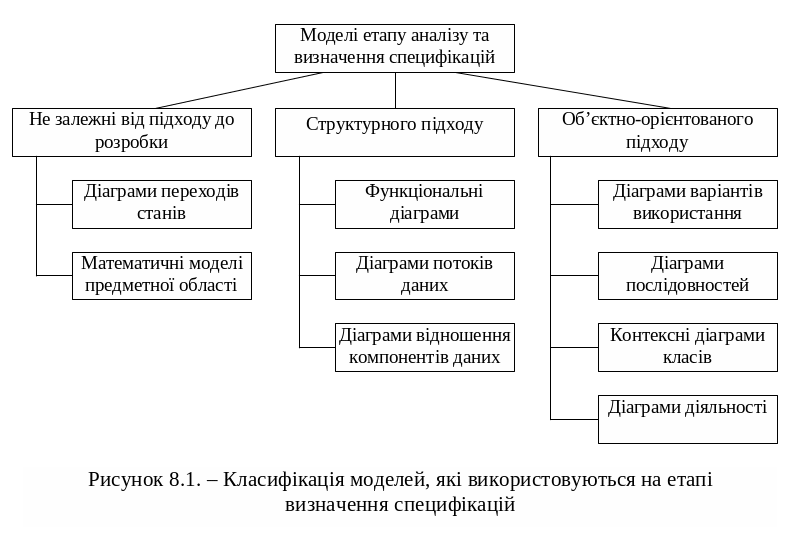
Формальні моделі, що використовуються на етапі визначення специфікацій можна розділити на дві групи: моделі, залежні від підходу до розробки (структурного або об’єктно-орієнтованого), і моделі, не залежні від нього. Так, діаграми переходів станів, які демонструють особливості поведінки майбутнього програмного забезпечення, при отриманні тих або інших сигналів ззовні, і математичні моделі наочної області використовують при будь-якому підході до розробки.
В рамках структурного підходу на етапі аналізу і визначення специфікацій використовують три типи моделей: орієнтовані на функції, орієнтовані на дані і орієнтовані на потоки даних. Кожну модель доцільно використовувати для свого специфічного класу програмних розробок.
На рис. 8.1 показана класифікація моделей майбутнього програмного забезпечення, що використовуються на етапі визначення специфікацій.
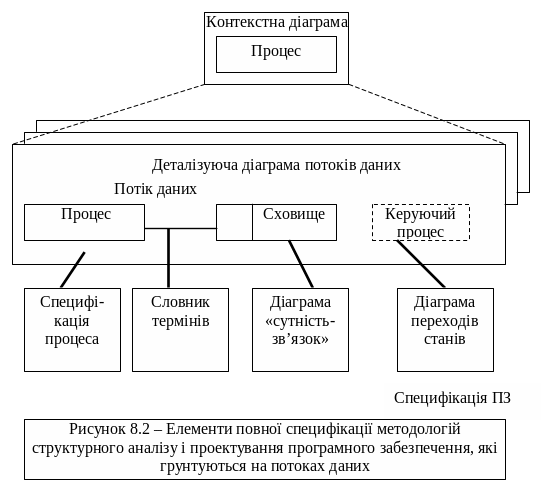
Методології структурного аналізу і проектування, засновані на моделюванні потоків даних, зазвичай використовують представлення проектованого програмного забезпечення у вигляді наступних моделей [11]:
• діаграм потоків даних (DFD - Data Flow Diagrams), що описують взаємодію джерел і споживачів інформації через процеси, які повинні бути реалізовані в системі;
• діаграм «суть-зв'язок (ERD - Entity-Relationship Diagrams)», що описують бази даних системи, що розробляється;
• функціональних діаграм (методологія SADT);
• діаграм переходів станів (STD - State Transition Diagrams), що характеризують поведінка системи в часі;
• специфікацій процесів;
• словника термінів.
Взаємозв’язок елементів такої узагальненої моделі показаний на рис.8.2.
Оскільки різні моделі описують майбутнє програмне забезпечення з різних сторін, рекомендується використовувати відразу декілька моделей і супроводжувати їх текстами: словниками, описами і т. п., які пояснюють відповідні діаграми.
Взаємозв’язок елементів такої узагальненої моделі показаний на рис.8.2.
Специфікації процесів. Специфікації процесів (СП) зазвичай представляють у вигляді короткого текстового опису, схем алгоритмів, псевдокодів, Flow-форм або діаграм Насси-Шнейдермана. Оскільки опис процесу повинен бути коротким і зрозумілим як розробникові, так і замовникові, для їх специфікації найчастіше використовують псевдокоди.
Незалежно від вибраної нотації специфікація процесу повинна починатися з ключового слова (наприклад @СПЕЦПРОЦ). Необхідні вхідні і вихідні дані повинні бути специфіковані таким чином:
@ВХІД = <ім'я символу даних>
@ВИХІД = <ім'я символу даних>
@ВХІДВИХІД = <ім'я символу даних>
де <ім'я символу даних> - відповідне ім'я із словника Даних.
Ці ключові слова повинні використовуватися перед визначенням СП, наприклад
@ВХІД = СЛОВА ПАМ'ЯТІ
@ВИХІД = ЗНАЧЕННЯ, ЩО ЗБЕРІГАЮТЬСЯ
@СПЕЦПРОЦ
Для всіх СЛІВ ПАМ'ЯТІ виконати:
Роздрукувати ЗБЕРЕЖЕНІ ЗНАЧЕННЯ
@
Ситуація, коли символ даних є одночасно вхідним і вихідним, може бути описана двома способами: або символ описується двічі з допомогою @ВХІД і @ВИХІД, або один раз з допомогою @ВХІДВИХІД.
Іноді в СП задаються пред- і після-умови виконання даного процесу. У предумовах записуються об'єкти, значення яких повинні бути істинні перед початком виконання процесу, що забезпечує певні гарантії безпеки для користувача. Аналогічно, у разі наявності після-умов гарантується, що значення всіх вхідних в нього об'єктів будуть істинні при завершенні процесу.
Специфікації повинні задовольняти наступним вимогам:
для кожного процесу нижнього рівня повинна існувати одна і лише одна специфікація;
специфікація повинна визначати спосіб перетворення вхідних потоків у вихідні;
немає необхідності (на даному етапі) визначати метод реалізації цього перетворення;
специфікація повинна прагнути до обмеження надмірності - не слід перевизначати те, що вже було визначене на діаграмі або в словнику даних;
набір конструкцій для побудови специфікації повинен бути простим і стандартним.
При структурному програмуванні розрізняють три види обчислювального процесу: лінійний, розгалужений і циклічний.
Лінійна структура – виконання операторів послідовно.
Розгалужена структура – в залежності від виконання деякої умови, виконується та чи інша послідовність операцій.
Циклічна структура – багатократне виконання однакової послідовності операцій.
Для зображення схеми алгоритмів розроблений ГОСТ 19.701-90.
Не залежно від складності, алгоритм можна представити, використовуючи три основні конструкції, які отримали назву базових:
слідування, означає послідовне виконання дій (рис.8.3,а).
розгалуження, відповідає вибору одного із двох варіантів дій (рис.8.3,б).
цикл-доки, визначає повторну дію, доки не буде порушена деяка умова, виконання якої перевіряється на початку циклу (рис.8.3,в).
Р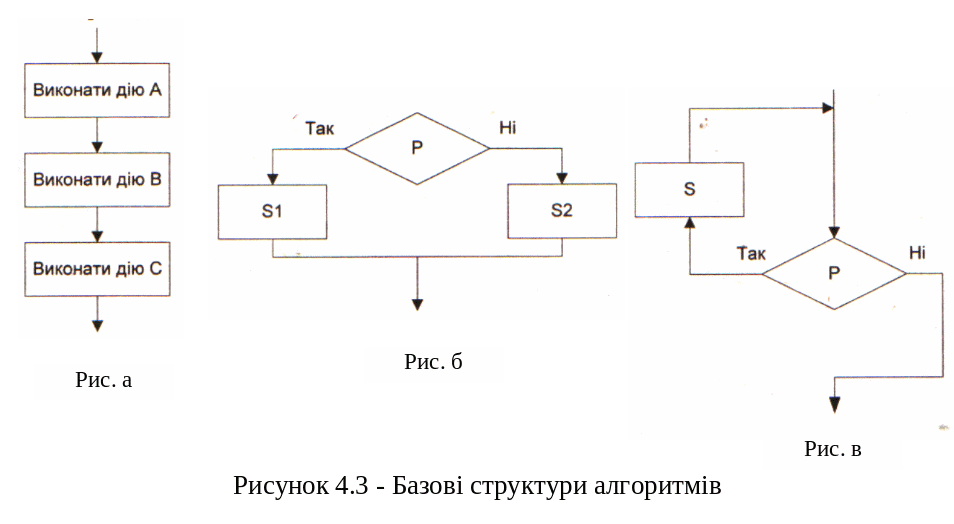 исунок
8.3 – Базові структури алгоритмів
исунок
8.3 – Базові структури алгоритмів
Окрім базових структур є ще три конструкції, які можна скласти із базових: вибір, цикл-до, цикл з заданим числом повторень. Перераховані шість конструкцій були покладені в основу структурного програмування.
Структурована природна мова
Структурована природна мова використовується для читабельного, строгого опису специфікацій процесів. Це розумна комбінація строгої мови програмування та читабельної природньої мови і складається з підмножини слів, які організовані в певні логічні структури, арифметичних виразів і діаграм.
До складу мови входять наступні основні символи:
дієслова, які використовують до об’єктів та орієнтовані на дію;
терміни, визначені на будь-якій стадії проекту ПЗ (наприклад, завдання, процедури, символи даних і тому подібне);
сполучники, які використовуються в логічних відношеннях;
загальновживані математичні, фізичні і технічні терміни;
арифметичні рівняння;
таблиці, діаграми, графи і т.п.;
коментарі.
Базові структури мови мають один вхід і один вихід. До них відносяться:
послідовна конструкція: ВИКОНАТИ функция1 ВИКОНАТИ функция2 ВИКОНАТИ функция3
конструкція вибору: ЯКЩО <умова> ТО ВИКОНАТИ функция1 ІНАКШЕ
ВИКОНАТИ функция2
КІНЕЦЬЯКЩО
ітерація: ДЛЯ <умова> ВИКОНАТИ функція КІНЕЦЬДЛЯ
або
ДОКИ <умова>
ВИКОНАТИ функція
КІНЕЦЬДОКИ
При використанні структурованої природної мови прийняті наступні угоди:
1) Логіка процесу виражається у вигляді комбінації послідовних конструкцій, конструкцій вибору і ітерацій.
2) Ключові слова ЯКЩО, ВИКОНАТИ, ІНАКШЕ і так далі повинні бути написані заголовними буквами.
3) Слова або фрази, визначені в словнику даних, повинні бути написані заголовними буквами.
4) Дієслова повинні бути активними, недвозначними і орієнтованими на цільову дію (заповнити, обчислити, витягувати, а не модернізувати, обробити).
5) Логіка процесу повинна бути виражена чітко і недвозначно.
Таблиці рішень
Структурована природна мова неприйнятна та деяких типів перетворень. Наприклад, якщо дія залежить від декількох змінних, які в сукупності можуть продукувати велике число комбінацій, то його опис буде дуже заплутаним і з великим числом рівнів вкладеності. Для опису подібних дій традиційно використовуються таблиці і дерева рішень.
Проектування специфікацій процесів за допомогою таблиць рішень (ТР) полягає в заданні матриці, що відображає безліч вхідних умов в безліч дій.
Таблиця Рішень складається з двох частин. Верхня частина таблиці використовується для визначення умов. Звичайна умова ЯКЩО є частиною оператора ЯКЩО-ТО і вимагає відповіді "так-ні". Проте іноді в умові може бути присутнім і обмежена безліч значень, наприклад, ЧИ Є ДОВЖИНА РЯДКА БІЛЬШОЮ, МЕНШОЮ АБО РІВНОЮ ГРАНИЧНОМУ ЗНАЧЕННЮ?
Нижня частина Таблиці Рішень використовується для визначення дій, тобто ТО-частина оператора ЯКЩО-ТО. Так, в конструкції ЯКЩО Йде дощ, ТО РОЗКРИТИ ПАРАСОЛЬКУ . Йде дощ є умовою, а РОЗКРИТИ ПАРАСОЛЬКУ - дією.
Ліва частина Таблиці Рішень містить власне опис умов і дій, а в правій частині перераховуються всі можливі комбінації умов і, відповідно, вказується, які конкретно дії і в якій послідовності виконуються, коли певна комбінація умов має місце.
Пояснимо вищесказане на прикладі специфікації процесу вибору верхнього одягу з корзини з речами. При виборі верхнього одягу необхідно керуватися наступними правилами:
якщо чергова річ є верхнім одягом, то узяти і покласти в свою сумку;
якщо своя сумка повна, то закінчити пошук верхнього одягу;
якщо корзина з речами порожня, то закінчити пошук;
інакше помістити річ в контейнер для проглянутих речей.
Таблиця рішень для даного прикладу виглядає таким чином (таблиця 8.1):
Таблиця 8.1
|
УМОВИ |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
С1 |
id_wear(c) |
Т |
Н |
Т |
Н |
Т |
Н |
Т |
Н |
С2 |
Full_bag() |
Н |
Т |
Т |
Т |
Н |
Н |
Т |
Н |
С3 |
Clear_kor() |
Н |
Т |
Н |
Н |
Т |
Т |
Т |
Н |
|
ДІЇ |
|
|
|
|
|
|
|
|
D1 |
Put_bag(c) |
1 |
|
|
|
1 |
|
|
|
D2 |
End_search() |
|
1 |
1 |
1 |
2 |
1 |
1 |
|
D3 |
Put_kont(c) |
|
|
|
|
|
|
|
1 |
Відмітимо, що якщо виконується умова C2, то немає необхідності в перевірці умов C1 і С3. Тому комбінації 2,3,4 і 7 можуть бути замінені узагальнювальною комбінацією (-,Т,-), де "-" означає будь-яку з можливих альтернатив (у нашому випадку, Т або Н). Тоді ми отримаємо зредуковану таблицю рішень:
Таблиця 2
|
УМОВИ |
1 |
2 |
3 |
4 |
5 |
С1 |
id_wear(c) |
Т |
- |
Т |
Н |
Н |
С2 |
Full_bag() |
Н |
Т |
Н |
Н |
Н |
С3 |
Clear_kor() |
Н |
- |
Т |
Т |
Н |
|
ДІЇ |
|
|
|
|
|
D1 |
Put_bag(c) |
1 |
|
1 |
|
|
D2 |
End_search() |
|
1 |
2 |
1 |
|
D3 |
Put_kont(c) |
|
|
|
|
1 |
Побудову Таблиці Рішень рекомендується здійснювати по наступних кроках:
Ідентифікувати всі умови (або змінні) в специфікації. Ідентифікувати всі значення, які кожна змінна може мати.
Обчислити число комбінацій умов. Якщо всі умови є бінарними, то існує 2**N комбінацій N змінних.
Ідентифікувати кожну з можливих дій, які можуть викликатися в специфікації.
Побудувати порожню таблицю, що включає всі можливі умови і дії, а також номери комбінацій умов.
Виписати і занести в таблицю всі можливі комбінації умов.
Редукувати комбінації умов.
Перевірити кожну комбінацію умов і ідентифікувати відповідні виконувані дії.
Виділити комбінації умов, для яких специфікація не вказує список дій, що треба виконати.
Обговорити побудовану таблицю.
Псевдокоди.
Псевдокод – формалізований текстовий опис алгоритму (текстова анотація). В літературі були представлені декілька варіантів псевдокодів. Один з них приведений в табл.8.3.
Таблиця 8.3
Структура |
Псевдокод |
Структура |
Псевдокод |
Слідування |
<Дія 1> <Дія 2> |
Вибір |
ВИБІР <код> <код 1>: <Дія 1> <код 2>: <Дія 2> Все-вибір |
Розгалуження |
ЯКЩО <Умова> ТО <Дія 1> ІНАКШЕ <Дія 2> Все-якщо |
Цикл з заданим числом повторень |
ДЛЯ <індекс> = <n>,<к>,<h> <Дія> Все-цикл
|
Цикл-доки |
ЦИКЛ-ДОКИ <Умова> <Дія > Все-цикл |
Цикл-до |
Виконувати <Дія > ДО <умова > |