

Глава 7. Введение в проблему статистического вывода
ности (в данном случае — А — 10), а дисперсия выборочных средних составит величину т2 = o^/N, где ох2 — дисперсия совокупности, N — объем каждой выборки (т еще называют ошибкой среднего).
Таким образом, заранее известно распределение средних для случая, когда верна Но. Это распределение позволяет определить, насколько вероятно то или иное случайное отклонение выборочного среднего от А — среднего в генеральной совокупности. Например, из свойств нормального распределения мы знаем, что примерно 68% площади под кривой нормального распределения находится в диапазоне ± о от среднего значения. Следовательно, 68% всех выборочных средних будет находиться в диапазоне А±т. Вероятность того, что выборочное среднее случайно попадет в этот диапазон составляет 0,68, а вероятность того, что оно будет отличаться от А больше чем на \т составляет 1 — 0,68 = 0,32. Аналогичным образом мы можем определить, насколько вероятно получение данного конкретного (или большего) отклонения выборочного среднего от А при условии истинности Но.
Для нашего примера необходимо сначала определить, насколько выборочное среднее отличается от А в единицах стандартного отклонения, то есть определить соответствующее г-значение:
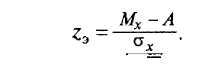
In
Формулы, подобные 7.1, позволяют получить так называемое эмпирическое значение критерия для соответствующего теоретического распределения (в данном случае формула 7.1 позволяет вычислить эмпирическое значение z-критерия — для нормального распределения). Подставляя выборочные значения, получаем z — 2. По таблице параметров нормального распределения можно определить, что в диапазоне ±2 находится 0,954 всей площади под кривой. В соответствии с интерпретацией единичной нормальной кривой, этой площади соответствует вероятность того, что случайное отклонение от 0 будет меньше z= ±2. А для нашего случая найденная площадь соответствует вероятности того, что случайное отклонение выборочного среднего значения будет меньше +(МК — А) — ±0,6. Соответственно, вероятность случайного отклонения выборочного среднего от генерального среднего на 0,6 и больше определяется площадью в «хвостах» под кривой нормального распределения — за пределами найденного диапазона (рис. 7.1). Следовательно, вероятность того, что данная выборка принадлежит генеральной совокупности со средним А (то есть, что верна Но), составляет/? = 1 — 0,954 = 0,046. Это и есть вероятность того, что данный выборочный результат мог быть получен случайно, когда на самом деле в генеральной совокупности верна Но или то, что называется р-уровнем значимости.
Следует отметить, что выборочное распределение средних значений соответствует нормальному виду, если N > 100. Для выборок меньшего объема распределение средних начинает зависеть от объема выборок (точнее — от числа степеней свободы, df) и соответствует другому теоретическому распределе-
97
Часть II. Методы статистического вывода: проверка гипотез
I
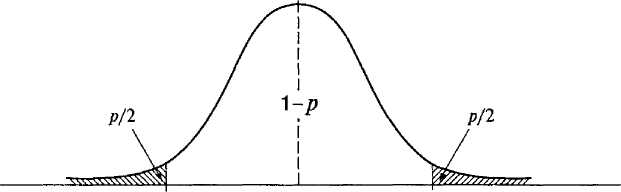
Рис. 7.1. Выборочное распределение средних значений для верной Но
нию — /-Стыодента. Тем не менее, общая последовательность проверки статистической гипотезы остается той же, как, впрочем, и для любого другого случая. Сначала вычисляется соответствующее эмпирическое значение:
![]()
I W _.. А I
df=N-l. (7.2)
Затем вычисленное эмпирическое значение сопоставляется с теоретическим /-распределением для соответствующего числа степеней свободы df. Это позволяет определить /^-уровень — вероятность того, что выборка принадлежит генеральной совокупности, для которой верна нулевая гипотеза Но: М — А.
Таким образом, в основе статистической проверки гипотез лежит представление о теоретическом распределении выборочной статистики — для условия, когда в генеральной совокупности верна нулевая статистическая гипотеза. В исследовании Арбутнота в качестве теоретического выступало биномиальное распределение для Но: Р — '/2, а в нашем примере — распределение выборочных средних для известной нулевой гипотезы (Z-распределение для больших N и /-распределение для малых N). В процессе проверки статистической гипотезы определяется /^-уровень значимости (вероятность того, что нулевая статистическая гипотеза верна) путем соотнесения эмпирических значений выборочных статистик (например, разности средних) с теоретическим распределением, соответствующим нулевой статистической гипотезе.
УРОВЕНЬ СТАТИСТИЧЕСКОЙ ЗНАЧИМОСТИ
Статистическая значимость (Significant level, сокращенно Sig.), или р-уро-вень значимости (р-level), — основной результат проверки статистической гипотезы. Говоря техническим языком, это вероятность получения данного результата выборочного исследования при условии, что на самом деле для генеральной совокупности верна нулевая статистическая гипотеза — то есть связи нет. Иначе говоря, это вероятность того, что обнаруженная связь носит случайный характер, а не является свойством совокупности. Именно статис-
98