

4. Случайные величины и их распределения
Распределения случайных величин и функции распределения. Распределение числовой случайной величины – это функция, которая однозначно определяет вероятность того, что случайная величина принимает заданное значение или принадлежит к некоторому заданному интервалу.
Первое – если случайная величина принимает конечное число значений. Тогда распределение задается функцией Р(Х = х), ставящей каждому возможному значению х случайной величины Х вероятность того, что Х = х.
Второе – если случайная величина принимает бесконечно много значений. Это возможно лишь тогда, когда вероятностное пространство, на котором определена случайная величина, состоит из бесконечного числа элементарных событий. Тогда распределение задается набором вероятностей P(a<X <b) для всех пар чисел a, b таких, что a<b. Распределение может быть задано с помощью т.н. функции распределения F(x) = P(X<x), определяющей для всех действительных х вероятность того, что случайная величина Х принимает значения, меньшие х. Ясно, что
P(a <X <b) = F(b) – F(a).
Это соотношение показывает, что как распределение может быть рассчитано по функции распределения, так и, наоборот, функция распределения – по распределению.
Используемые в вероятностно-статистических методах принятия решений и других прикладных исследованиях функции распределения бывают либо дискретными, либо непрерывными, либо их комбинациями.
Дискретные функции распределения соответствуют дискретным случайным величинам, принимающим конечное число значений или же значения из множества, элементы которого можно перенумеровать натуральными числами (такие множества в математике называют счетными). Их график имеет вид ступенчатой лестницы (рис. 1).
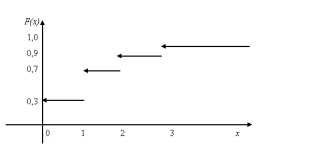
Рис.1. График функции распределения числа дефектных изделий.
Непрерывные
функции распределения не имеют скачков.
Они монотонно
возрастают http://www.aup.ru/books/m157/2_2_4.htm
- _ftn1при
увеличении аргумента – от 0 при 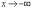 до
1 при
до
1 при 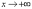 .
Случайные величины, имеющие непрерывные
функции распределения, называют
непрерывными.
.
Случайные величины, имеющие непрерывные
функции распределения, называют
непрерывными.
Непрерывные функции распределения, используемые в вероятностно-статистических методах принятия решений, имеют производные. Первая производная f(x) функции распределения F(x)называется плотностью вероятности,
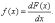
По плотности вероятности можно определить функцию распределения:
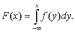
Для любой функции распределения

а потому

Перечисленные свойства функций распределения постоянно используются в вероятностно-статистических методах принятия решений.
Смешанные функции распределения встречаются, в частности, тогда, когда наблюдения в какой-то момент прекращаются. Например, при анализе статистических данных, полученных при использовании планов испытаний на надежность, предусматривающих прекращение испытаний по истечении некоторого срока. Или при анализе данных о технических изделиях, потребовавших гарантийного ремонта.
Характеристики случайных величин. В вероятностно-статистических методах принятия решений используется ряд характеристик случайных величин, выражающихся через функции распределения и плотности вероятностей.
При описании дифференциации доходов, при нахождении доверительных границ для параметров распределений случайных величин и во многих иных случаях используется такое понятие, как «квантиль порядка р», где 0 < p < 1 (обозначается хр). Квантиль порядка р – значение случайной величины, для которого функция распределения принимает значение р или имеет место «скачок» со значения меньше р до значения больше р (рис.2). Может случиться, что это условие выполняется для всех значений х, принадлежащих этому интервалу (т.е. функция распределения постоянна на этом интервале и равна р). Тогда каждое такое значение называется «квантилем порядка р».

Рис.2. Определение квантиля хр порядка р.
Для непрерывных функций распределения, как правило, существует единственный квантиль хр порядка р (рис.2), причем
F(xp) = p. (2)
Пример. Найдем квантиль хр порядка р для функции распределения F(x) из (1).
При 0 < p < 1 квантиль хр находится из уравнения
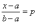 ,
,
т.е. хр = a + p(b – a) = a(1- p) +bp. При p = 0 любое x < a является квантилем порядка p = 0. Квантилем порядка p = 1 является любое число x> b.
Большое значение в статистике имеет квантиль порядка р = Ѕ. Он называется медианой (случайной величины Х или ее функции распределения F(x)) и обозначается Me (X). В геометрии есть понятие «медиана» - прямая, проходящая через вершину треугольника и делящая противоположную его сторону пополам. В математической статистике медиана делит пополам не сторону треугольника, а распределение случайной величины: равенство F(x0,5) = 0,5 означает, что вероятность попасть левееx0,5 и вероятность попасть правее x0,5 (или непосредственно в x0,5) равны между собой и равны Ѕ, т.е.
P(X < x0,5) = P(X > x0,5) = Ѕ.
Медиана указывает «центр» распределения. С точки зрения одной из современных концепций – теории устойчивых статистических процедур – медиана является более хорошей характеристикой случайной величины, чем математическое ожидание [2,7]. При обработке результатов измерений в порядковой шкале (см. главу о теории измерений) медианой можно пользоваться, а математическим ожиданием – нет.
Ясный смысл имеет такая характеристика случайной величины, как мода – значение (или значения) случайной величины, соответствующее локальному максимуму плотности вероятности для непрерывной случайной величины или локальному максимуму вероятности для дискретной случайной величины.
Если x0 –
мода случайной величины с плотностью f(x), то,
как известно из дифференциального
исчисления,  .
.
У случайной величины может быть много мод. Так, для равномерного распределения (1) каждая точках такая, что a < x < b, является модой. Однако это исключение. Большинство случайных величин, используемых в вероятностно-статистических методах принятия решений и других прикладных исследованиях, имеют одну моду. Случайные величины, плотности, распределения, имеющие одну моду, называются унимодальными.
Нормальное распределение и центральная предельная теорема. В вероятностно-статистических методах принятия решений часто идет речь о нормальном распределении. Иногда его пытаются использовать для моделирования распределения исходных данных (эти попытки не всегда являются обоснованными – см. ниже). Более существенно, что многие методы обработки данных основаны на том, что расчетные величины имеют распределения, близкие к нормальному.
Пусть X1, X2,…, Xn,
…– независимые одинаково распределенные
случайные величины с математическими
ожиданиями M(Xi)
= m и
дисперсиями D(Xi) = 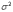 , i =
1, 2,…, n,…
Как следует из результатов предыдущей
главы,
, i =
1, 2,…, n,…
Как следует из результатов предыдущей
главы,
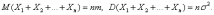
Рассмотрим
приведенную случайную величину Un для
суммы 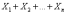 ,
а именно,
,
а именно,
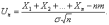
Как следует из формул (7), M(Un) = 0, D(Un) = 1.
Центральная предельная теорема (для одинаково распределенных слагаемых). Пусть X1, X2,…, Xn, …– независимые одинаково распределенные случайные величины с математическими ожиданиями M(Xi) = m и дисперсиями D(Xi) = , i = 1, 2,…, n,… Тогда для любого х существует предел
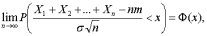
где Ф(х) – функция стандартного нормального распределения.
Подробнее о функции Ф(х) – ниже (читается «фи от икс», поскольку Ф – греческая прописная буква «фи»).
Центральная предельная теорема (ЦПТ) носит свое название по той причине, что она является центральным, наиболее часто применяющимся математическим результатом теории вероятностей и математической статистики.
Дискретные распределения, используемые в вероятностно-статистических методах принятия решений. Наиболее часто используют три семейства дискретных распределений - биномиальных, гипергеометрических и Пуассона, а также некоторые другие семейства - геометрических, отрицательных биномиальных, мультиномиальных, отрицательных гипергеометрических и т.д.
Как уже говорилось, биномиальное распределение имеет место при независимых испытаниях, в каждом из которых с вероятностью р появляется событие А. Если общее число испытаний n задано, то число испытаний Y, в которых появилось событие А, имеет биномиальное распределение. Для биномиального распределения вероятность принятия случайной величиной Y значения y определяется формулой
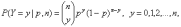 (19)
(19)
где
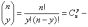
- число сочетаний из n элементов по y, известное из комбинаторики. Для всех y, кроме 0, 1, 2, …, n, имеем P(Y=y)=0. Биномиальное распределение при фиксированном объеме выборки n задается параметром p, т.е. биномиальные распределения образуют однопараметрическое семейство. Они применяются при анализе данных выборочных исследований [2], в частности, при изучении предпочтений потребителей, выборочном контроле качества продукции по планам одноступенчатого контроля, при испытаниях совокупностей индивидуумов в демографии, социологии, медицине, биологии и др.
Если Y1 и Y2 - независимые биномиальные случайные величины с одним и тем же параметром p0, определенные по выборкам с объемами n1 и n2 соответственно, то Y1 + Y2 - биномиальная случайная величина, имеющая распределение (19) с р = p0 и n = n1 + n2. Это замечание расширяет область применимости биномиального распределения, позволяя объединять результаты нескольких групп испытаний, когда есть основания полагать, что всем этим группам соответствует один и тот же параметр.
Характеристики биномиального распределения вычислены ранее:
M(Y) = np, D(Y) = np(1-p).
В разделе "События и вероятности" для биномиальной случайной величины доказан закон больших чисел:
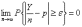
для любого . С помощью центральной предельной теоремы закон больших чисел можно уточнить, указав, насколько Y/n отличается от р.
Теорема Муавра-Лапласа. Для любых чисел a и b, a<b, имеем
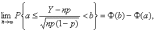
где Ф(х) – функция стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1.
Гипергеометрическое распределение имеет место при выборочном контроле конечной совокупности объектов объема N по альтернативному признаку. Каждый контролируемый объект классифицируется либо как обладающий признаком А, либо как не обладающий этим признаком. Гипергеометрическое распределение имеет случайная величина Y, равная числу объектов, обладающих признаком А в случайной выборке объема n, где n<N. Например, число Y дефектных единиц продукции в случайной выборке объема n из партии объема N имеет гипергеометрическое распределение, если n<N. Другой пример – лотерея. Пусть признак А билета – это признак «быть выигрышным». Пусть всего билетов N, а некоторое лицо приобрело n из них. Тогда число выигрышных билетов у этого лица имеет гипергеометрическое распределение.
Для гипергеометрического распределения вероятность принятия случайной величиной Y значения y имеет вид
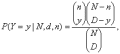 (20)
(20)
где D – число объектов, обладающих признаком А, в рассматриваемой совокупности объема N. При этом y принимает значения от max{0, n - (N - D)} до min{n, D}, при прочих y вероятность в формуле (20) равна 0. Таким образом, гипергеометрическое распределение определяется тремя параметрами – объемом генеральной совокупности N, числом объектов D в ней, обладающих рассматриваемым признаком А, и объемом выборки n.
Простой
случайной выборкой объема n из
совокупности объема N называется
выборка, полученная в результате
случайного отбора, при котором любой
из 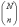 наборов
из n объектов
имеет одну и ту же вероятность быть
отобранным. Методы случайного отбора
выборок респондентов (опрашиваемых)
или единиц штучной продукции рассматриваются
в инструктивно-методических и
нормативно-технических документах.
наборов
из n объектов
имеет одну и ту же вероятность быть
отобранным. Методы случайного отбора
выборок респондентов (опрашиваемых)
или единиц штучной продукции рассматриваются
в инструктивно-методических и
нормативно-технических документах.
Третье широко используемое дискретное распределение – распределение Пуассона. Случайная величина Y имеет распределение Пуассона, если
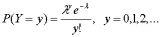 ,
,
где λ – параметр распределения Пуассона, и P(Y=y)=0 для всех прочих y (при y=0 обозначено 0! =1). Для распределения Пуассона
M(Y) = λ, D(Y) = λ.
Распределение Пуассона является предельным случаем биномиального распределения, когда вероятность р осуществления события мала, но число испытаний n велико, причем np = λ. Точнее, справедливо предельное соотношение
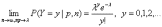
Поэтому распределение Пуассона (в старой терминологии «закон распределения») часто называют также «законом редких событий».
Распределение Пуассона возникает в теории потоков событий. Доказано, что для простейшего потока с постоянной интенсивностью Λ число событий (вызовов), происшедших за времяt, имеет распределение Пуассона с параметром λ = Λt. Следовательно, вероятность того, что за время tне произойдет ни одного события, равна e-Λt, т.е. функция распределения длины промежутка между событиями является экспоненциальной.
Распределение Пуассона используется при анализе результатов выборочных маркетинговых обследований потребителей, расчете оперативных характеристик планов статистического приемочного контроля, статистических закономерностей несчастных случаев и редких заболеваний, и т.д.