

Введение в анализ данных
Анализ данных — область математики и информатики, занимающаяся построением и исследованием наиболее общих математических методов и вычислительных алгоритмов извлечения знаний из экспериментальных (в широком смысле) данных; процесс исследования, фильтрации, преобразования и моделирования данных с целью извлечения полезной информации и принятия решений. Анализ данных имеет множество аспектов и подходов, охватывает разные методы в различных областях науки и деятельности.
Интеллектуальный анализ данных — это особый метод анализа данных, который фокусируется на моделировании и открытии данных, а не на их описании.
Не следует путать с Извлечением информации. Извлечение информации (англ. information extraction) — это задача автоматического извлечения (построения) структурированных данных из неструктурированных или слабоструктурированных машиночитаемых документов.
Извлечение информации является разновидностью информационного поиска, связанного с обработкой текста на естественном языке. Примером извлечения информации может быть поиск деловых визитов — формально это записывается так: НанеслиВизит(Компания-Кто, Компания-Кому, ДатаВизита), — из новостных лент, таких как: «Вчера, 1 апреля 2007 года, представители корпорации Пепелац Интернэшнл посетили офис компании Гравицап Продакшнз». Главная цель такого преобразования — возможность анализа изначально «хаотичной» информации с помощью стандартных методов обработки данных. Более узкой целью может служить, например, задача выявить логические закономерности в описанных в тексте событиях.
В современных информационных технологиях роль такой процедуры, как извлечение информации, всё больше возрастает — из-за стремительного увеличения количества неструктурированной (без метаданных) информации, в частности, в Интернете. Эта информация может быть сделана более структурированной посредством преобразования в реляционную форму или добавлением XML разметки. При мониторинге новостных лент с помощью интеллектуальных агентов как раз и потребуются методы извлечения информации и преобразования её в такую форму, с которой будет удобнее работать позже.
Типичная задача извлечения информации: просканировать набор документов, написанных на естественном языке, и наполнить базу данных выделенной полезной информацией. Современные подходы извлечения информации используют методы обработки естественного языка, направленные лишь на очень ограниченный набор тем (вопросов, проблем) — часто только на одну тему.
Data Mining (рус. добыча данных, интеллектуальный анализ данных, глубинный анализ данных) — собирательное название, используемое для обозначения совокупности методов обнаружения в данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. Термин введён Григорием Пятецким-Шапиро в 1989 году.
Английское словосочетание «Data Mining» пока не имеет устоявшегося перевода на русский язык. При передаче на русском языке используются следующие словосочетания: просев информации, добыча данных, извлечение данных, а, также, интеллектуальный анализ данных. Более полным и точным является словосочетание «обнаружение знаний в базах данных» (англ. knowledge discovering in databases, KDD).
Основу методов Data Mining составляют всевозможные методы классификации, моделирования и прогнозирования, основанные на применении деревьев решений, искусственных нейронных сетей, генетических алгоритмов, эволюционного программирования, ассоциативной памяти, нечёткой логики. К методам Data Mining нередко относят статистические методы (дескриптивный анализ, корреляционный и регрессионный анализ, факторный анализ, дисперсионный анализ, компонентный анализ, дискриминантный анализ, анализ временных рядов, анализ выживаемости, анализ связей). Такие методы, однако, предполагают некоторые априорные представления об анализируемых данных, что несколько расходится с целями Data Mining (обнаружение ранее неизвестных нетривиальных и практически полезных знаний).
Одно из важнейших назначений методов Data Mining состоит в наглядном представлении результатов вычислений, что позволяет использовать инструментарий Data Mining людьми, не имеющими специальной математической подготовки. В то же время, применение статистических методов анализа данных требует хорошего владения теорией вероятностей и математической статистикой.
Бизнес-аналитика охватывает анализ данных, который полагается на агрегацию.
Business intelligence или сокращенно BI — бизнес-анализ, бизнес-аналитика. Под этим понятием чаще всего подразумевают программное обеспечение, созданное для помощи менеджеру в анализе информации о своей компании и её окружении. Существует несколько вариантов понимания этого термина.
Бизнес-аналитика — это методы и инструменты для построения информативных отчётов о текущей ситуации. В таком случае цель бизнес-аналитики — предоставить нужную информацию тому человеку, которому она необходима в нужное время. Эта информация может оказаться жизненно необходимой для принятия управленческих решений.
Бизнес-аналитика — это инструменты, используемые для преобразования, хранения, анализа, моделирования, доставки и трассировки информации в ходе работы над задачами, связанными с принятием решений на основе фактических данных. При этом с помощью этих средств лица, принимающие решения, должны при использовании подходящих технологий получать нужные сведения и в нужное время.
Таким образом, BI в первом понимании является лишь одним из секторов бизнес-аналитики в более широком втором понимании. Помимо отчётности туда входят инструменты интеграции и очистки данных (ETL), аналитические хранилища данных и средства Data Mining.
BI-технологии позволяют анализировать большие объёмы информации, заостряя внимание пользователей лишь на ключевых факторах эффективности, моделируя исход различных вариантов действий, отслеживая результаты принятия тех или иных решений.
Термин впервые появился в 1958 году в статье исследователя из IBM Ханса Питера Луна (англ. Hans Peter Luhn). Он определил этот термин как: «Возможность понимания связей между представленными фактами.»
BI в сегодняшнем понимании эволюционировал из систем для принятия решений, которые появились в начале 1960-х и разрабатывались в середине 1980-х.
В 1989 году Говард Дреснер (позже аналитик Gartner) определил Business intelligence как общий термин, описывающий «концепции и методы для улучшения принятия бизнес-решений с использованием систем на основе бизнес-данных».
В статистическом смысле некоторые разделяют анализ данных на описательную статистику, исследовательский анализ данных и проверку статистических гипотез.
Цель описательной (дескриптивной) статистики — обработка эмпирических данных, их систематизация, наглядное представление в форме графиков и таблиц, а также их количественное описание посредством основных статистических показателей.
В отличие от индуктивной статистики дескриптивная статистика не делает выводов о генеральной совокупности на основании результатов исследования частных случаев. Индуктивная же статистика напротив предполагает, что свойства и закономерности, выявленные при исследовании объектов выборки, также присущи генеральной совокупности.
Исследовательский анализ данных это подход к анализу данных с целью формулировки гипотез стоящих тестирования, дополняющий инструментами стандартной статистики для тестирования гипотез. Названо Джоном Тьюки для отличия от проверки статистических гипотез, термином используемым для набора идей о тестировании гипотез, достигаемом уровне значимости, доверительном интервале и прочих, которые формируют ключевые инструменты в арсенале практикующих статистиков.
Исследовательский анализ данных занимается открытием новых характеристик данных, а проверка статистических гипотез на подтверждении или опровержении существующих гипотез.
Проверки статистических гипотез — один из классов задач в математической статистике.
Пусть
в (статистическом) эксперименте доступна
наблюдению случайная
величина
![]() ,
распределение
которой
,
распределение
которой
![]() известно
полностью или частично. Тогда любое
утверждение, касающееся
известно
полностью или частично. Тогда любое
утверждение, касающееся
![]() называется
статистической
гипотезой.
Гипотезы различают по виду предположений,
содержащихся в них:
называется
статистической
гипотезой.
Гипотезы различают по виду предположений,
содержащихся в них:
Статистическая гипотеза, однозначно определяющая распределение , то есть
 ,
где
,
где
 какой-то
конкретный закон, называется простой.
какой-то
конкретный закон, называется простой.
Статистическая гипотеза, утверждающая принадлежность распределения к некоторому семейству распределений, то есть вида
 ,
где
,
где
 —
семейство распределений, называется
сложной.
—
семейство распределений, называется
сложной.
На
практике обычно требуется проверить
какую-то конкретную и как правило простую
гипотезу
![]() .
Такую гипотезу принято называть нулевой.
При этом параллельно рассматривается
противоречащая ей гипотеза
.
Такую гипотезу принято называть нулевой.
При этом параллельно рассматривается
противоречащая ей гипотеза
![]() ,
называемая конкурирующей
или альтернативной.
,
называемая конкурирующей
или альтернативной.
Выдвинутая гипотеза нуждается в проверке, которая осуществляется статистическими методами, поэтому гипотезу называют статистической. Для проверки гипотезы используют критерии, позволяющие принять или опровергнуть гипотезу.
В
большинстве случаев статистические
критерии основаны на случайной
выборке
![]() фиксированного
объема
фиксированного
объема
![]() из
распределения
.
В последовательном
анализе выборка формируется в ходе
самого эксперимента и потому её объем
является случайной
величиной (см. Последовательный
статистический критерий).
из
распределения
.
В последовательном
анализе выборка формируется в ходе
самого эксперимента и потому её объем
является случайной
величиной (см. Последовательный
статистический критерий).
Этапы проверки статистических гипотез
Формулировка основной гипотезы и конкурирующей гипотезы . Гипотезы должны быть чётко формализованы в математических терминах.
Задание уровня значимости
 ,
на котором в дальнейшем и будет сделан
вывод о справедливости гипотезы. Он
равен вероятности допустить ошибку
первого рода.
,
на котором в дальнейшем и будет сделан
вывод о справедливости гипотезы. Он
равен вероятности допустить ошибку
первого рода.Расчёт статистики
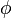 критерия
такой, что:
критерия
такой, что:
её величина зависит от исходной выборки
 ;
;по её значению можно делать выводы об истинности гипотезы ;
сама статистика должна подчиняться какому-то известному закону распределения, так как сама является случайной в силу случайности
 .
.
Построение критической области. Из области значений выделяется подмножество
 таких
значений, по которым можно судить о
существенных расхождениях с предположением.
Его размер выбирается таким образом,
чтобы выполнялось равенство
таких
значений, по которым можно судить о
существенных расхождениях с предположением.
Его размер выбирается таким образом,
чтобы выполнялось равенство
 .
Это множество
и
называется критической
областью.
.
Это множество
и
называется критической
областью.Вывод об истинности гипотезы. Наблюдаемые значения выборки подставляются в статистику и по попаданию (или непопаданию) в критическую область выносится решение об отвержении (или принятии) выдвинутой гипотезы .
Выделяют три вида критических областей:
Двусторонняя критическая область определяется двумя интервалами
 ,
где
,
где
 находят
из условий
находят
из условий
 .
.Левосторонняя критическая область определяется интервалом
 ,
где
,
где
 находят
из условия
находят
из условия
 .
.Правосторонняя критическая область определяется интервалом
 ,
где
,
где
 находят
из условия
находят
из условия
 .
.
Прогнозный анализ фокусируется на применении статистических или структурных моделей для предсказания или классификации, а анализ текста применяет статистические, лингвистические и структурные методы для извлечения и классификации информации из текстовых источников принадлежащих к неструктурированным данным.
Прогнозная аналитика охватывает множество методов из статистики, интеллектуального анализа данных и теории игр, анализирует текущие и исторические факты для составления предсказаний о будущих событиях. В бизнесе, прогнозные модели используют паттерны, найденные в исторических и выполняемых данных, чтобы идентифицировать риски и возможности. Модели фиксируют связи среди многих факторов, чтобы сделать возможной оценку рисков или потенциала, связанного с конкретным набором условий, руководя принятием решений о возможных сделках.
Прогнозная аналитика используется в актуарных расчётах, финансовых услугах, страховании, телекоммуникациях, розничной торговле, туризме, здравоохранении, фармацевтике и других областях.
Одно из хорошо известных применений — кредитный скоринг, который используется в финансовых услугах. Модели скоринга обрабатывают кредитную историю потребителя, займы, потребительские данные и т. д., в порядке ранжирования лиц по вероятности выплаты по кредитам в сроки.
Интеграция данных это предшественник анализа данных, а сам анализ данных тесно связан с визуализацией данных и распространению данных. Термин «Анализ данных» иногда используется как синоним к моделированию данных
Интеграция данных включает объединение данных, находящихся в различных источниках и предоставление данных пользователям в унифицированном виде. Этот процесс становится существенным как в коммерческих задачах (когда двум похожим компаниям необходимо объединить их базы данных), так и в научных (комбинирование результатов исследования из различных биоинформационных репозиториев, для примера). Роль интеграции данных возрастает, когда увеличивается объём и необходимость совместного использования данных. Это стало фокусом обширной теоретической работы, а многочисленные проблемы остаются нерешёнными