

2.3.2. Иерархическая модель данных
Модель основана на понятии «деревьев», состоящих из вершин и ребер. Вершина «дерева» ставится в соответствие совокупности атрибутов данных, характеризующих некоторый объект. Вершины и ребра «дерева» образуют иерархическую древовидную структуру, состоящую из п уровней (рис. 2.5.).
Первую вершину в «дереве» называют корневой вершиной. ИМД удовлетворяет следующим условиям:
1. Иерархия начинается с корневой вершины.
2. Каждая вершина соответствует одному или нескольким атрибутам.
3. На уровнях с большим номером находятся зависимые вершины. Вершина предшествующего уровня является начальной для новых зависимых вершин.
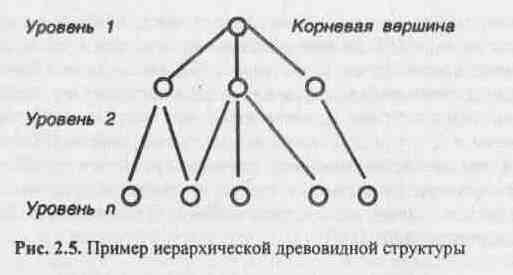
4. Каждая вершина, находящаяся на уровне I, соединена с одной и только одной вершиной уровня (I- 1), за исключением корневой вершины.
5. Корневая вершина может быть связана с одной или несколькими зависимыми вершинами.
6. Доступ к каждой вершине происходит через корневую по единственному пути.
7. Существует произвольное количество вершин каждого уровня. ИМД состоящая из нескольких деревьев, является «лесом». Каждая корневая вершина образует начало записи логической БД. В ИМД вершины, находящиеся на уровне I, называют порожденными вершинами на уровне (I - 1). Рассмотрим пример представления информации в ИМД, реализующей отношение «один ко многим» (рис. 2.6.). Для каждого пользователя может иметься экземпляр корневой вершины. ИМД позволяет для каждого пользователя получать представление о нескольких операциях и нескольких ЭВМ.
ПОЛЬЗОВАТЕЛЬ соответствует корневой вершине и находится на более высоком уровне иерархии, чем ЭВМ, ОПЕРАЦИЯ и РЕЗУЛЬТАТ. Выбор ИМД осуществляет администратор БД на основе операционных характеристик.

Введение двух ИМД, связанных между собой, позволяет решать вопросы включения и удаления данных. Достоинства ИМД:
простота построения и использования, обеспечение определенного уровня независимости данных, наличие существующих СУБД, простота оценки операционных характеристик. Недостатки: отношение «многих ко многим» реализуется очень сложно, дает громоздкую структуру и требует хранения избыточных данных, что нежелательно на физическом уровне; иерархическая упорядоченность усложняет операции удаления и включения; доступ к любой вершине возможен через корневую, что увеличивает время доступа.
2.3.3. Сетевая модель данных
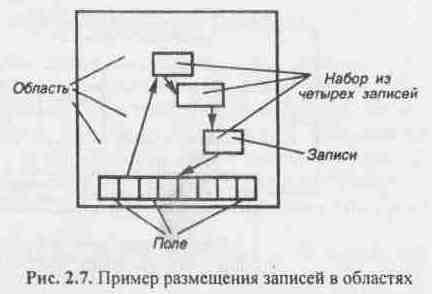
В СМД элементарные данные и отношения между ними представляются в виде ориентированной сети (вершины — данные, дуги — отношения). БД, описываемая сетевой моделью, состоит из нескольких областей. Область содержит записи. Одна запись состоит из нескольких полей. Набор, состоящий из записей, может размещаться в одной или нескольких областях (рис. 2.7).
В СМД объекты предметной области объединяются в сеть. Графически сетевая модель описывается прямоугольниками и стрелками. Каждый тип записи может содержать несколько атрибутов. На рис. 2.8. показан пример представления области в СМД. Здесь область — это часть БД, в которой


ПОЛЬЗОВАТЕЛЬ — ВЫПОЛНИЛ — ПРОЦЕДУРУ реализует иерархическую связь между пользователем и операцией.
Важное отличие СМД от ИМД состоит в том, что в СМД каждая запись может быть в любом числе наборов и может находиться как на верхнем, так и на нижнем иерархическом уровне. Следовательно, любая запись может быть задана как точка входа.
Существует три типа наборов:
а) первый тип
образуется типами записей: ПОЛЬЗОВАТЕЛЬ
и

б) второй тип образуется из трех и более записей и называется многочисленным (рис. 2.10, б);
в) третий тип представляется сингулярными наборами и объединяет записи,у которых нет корневой вершины, но которые могут иметь ее впоследствии (рис. 2.10, в).
Достоинства СМД — наличие реализованных СУБД обеспечивающих; простота реализации отношений «многие ко многим».
Недостаток СМД — сложность. При реорганизации БД возможна потеря независимости данных.
2.4. Система управления базами данных
Задачи автоматизации проектирования и производства связаны с хранением значительного объема информации в виде единообразных записей и сравнительно простой их обработкой для извлечения новой информации в удобной для пользователя форме. Предназначенные для этого программные средства обычно объединяются под общим названием системы управления базами данных (СУБД), в котором под базой данных понимается совокупность взаимосвязанных и хранящихся в удобном для использования виде данных.
Наилучшая форма организации данных зависит как от их содержания, так и от того, как эти данные должны использоваться. Например, существуют немало СУБД, предназначенных для обработки списков, содержащих разные сведения о перечисленных в этих списках людях. Эти СУБД существенно различаются в зависимости от того, какие сведения о каждом лице имеются в списке (в зависимости от логической структуры данных), и от того, как осуществляется поиск того или иного лица.
Вообще, логической структурой данных принято называть конкретные логические взаимосвязи между данными, обусловленные содержанием этих данных. Например, логической структурой стипендиальной ведомости студенческой группы является взаимосвязь каждой фамилии студента с величиной его стипендии и взаимосвязь всех перечисленных в ведомости фамилий с номером группы.
Совокупность количества взаимосвязанных данных (или, как их еще называют, полей) принято называть логической записью, а совокупность логических записей данного вида — файлом. Таким образом, каждая точка стипендиальной ведомости образует отдельную логическую запись, состоящую из двух полей — фамилии и величины стипендии (например, ИВАНОВ 9000), а вся ведомость образует файл.
В базе данных может одновременно храниться много различных файлов, поэтому пользователь присваивает каждому файлу свое имя. Всякая БД должна храниться в ЗУ ЭВМ. Поэтому форма организации данных зависит не только от логической структуры, но и от ее физического представления, т. е. от способа хранения данных в памяти ЭВМ. Порцию данных, которую СУБД считывает из ЗУ или записывает в ЗУ как единое целое, принято называть физической записью.
Одной из самых важных функций СУБД является поиск логической записи в файле. Поиск производится по ключу, который может состоять из поля, части поля, из комбинации полей. Например, при поиске величины стипендии студента по фамилии ИВАНОВ ключом является фамилия ИВАНОВ.