

Динамическое хеширование
Описанные выше методы хеширования являются статическими, т.е. сначала выделяется некая хеш-таблица, под ее размер подбираются константы для хеш-функции. К сожалению, это не подходит для задач, в которых размер базы данных меняется часто и значительно [9]. По мере роста базы данных можно
пользоваться изначальной хеш-функцией, теряя производительность из-за роста коллизий;
выбрать хеш-функцию «с запасом», что повлечет неоправданные потери дискового пространства;
периодически менять функцию, пересчитывать все адреса. Это отнимает очень много ресурсов и выводит из строя базу на некоторое время.
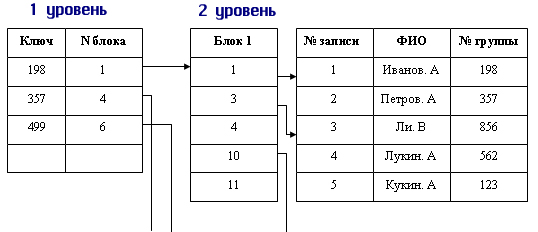
Существует техника, позволяющая динамически менять размер хеш-структуры [10]. Это – динамическое хеширование. Хеш-функция генерирует так называемый псевдоключ (“pseudokey”), который используется лишь частично для доступа к элементу. Другими словами, генерируется достаточно длинная битовая последовательность, которая должна быть достаточна для адресации всех потенциально возможных элементов. В то время, как при статическом хешировании потребовалась бы очень большая таблица (которая обычно хранится в оперативной памяти для ускорения доступа), здесь размер занятой памяти прямо пропорционален количеству элементов в базе данных. Каждая запись в таблице хранится не отдельно, а в каком-то блоке (“bucket”). Эти блоки совпадают с физическими блоками на устройстве хранения данных. Если в блоке нет больше места, чтобы вместить запись, то блок делится на два, а на его место ставится указатель на два новых блока.
20) Инвертированные списки
Инвертированный список в общем случае — это двухуровневая индексная структура. Здесь на первом уровне находится файл или часть файла, в которой упо-рядочепно расположены значения вторичных ключей. Каждая запись с вторичным ключом имеет ссылку на номер первого блока в цепочке блоков, содержащих номера записей с данным значением вторичного ключа. На втором уровне находится цепочка блоков, содержащих номера записей, содержащих одно и то же значение вторичного ключа. При этом блоки второго уровня упорядочены по значениям вторичного ключа.
И наконец, на третьем уровне находится собственно основной файл.
Механизм доступа к записям по вторичному ключу при подобной организации записей весьма прост. На первом шаге мы ищем в области первого уровня заданное значение вторичного ключа, а затем по ссылке считываем блоки второго уровня, содержащие номера записей с заданным значением вторичного ключа, а далее уже прямым доступом загружаем в рабочую область пользователя содержимое всех записей, содержащих заданное значение вторичного ключа.
Для одного основного файла может быть создано несколько инвертированных списков по разным вторичным ключам.
Следует отметить, что организация вторичных списков действительно ускоряет поиск записей с заданным значением вторичного ключа. Но рассмотрим вопросмодификации основного файла.
При модификации основного файла происходит следующая последовательность действий:
Изменяется запись основного файла.
Исключается старая ссылка на предыдущее значение вторичного ключа.
Добавляется новая ссылка на новое значение вторичного ключа.
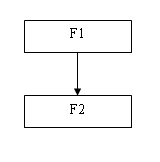
21)Моделирование отношений «один-ко-многим» на файловых структурах
Моделирование отношений «один-ко-многим» на файловых структурах
Отношение иерархии является типичным для баз данных, поэтому моделирование иерархических связей является типичным для физических моделей баз данных.
Для
моделирования отношений 1:М (один-ко-многим)
и М:М (многие-ко-мно-гим) на файловых
структурах используется принцип
организации цепочек записей внутри
файла и ссылки на номера записей для
нескольких взаимосвязанных
файлов.Моделирование
отношения 1:М с использованием
однонаправленных указателейВ
этом случае связываются два файла,
например F1 и F2, причем предполагается,
что одна запись в файле F1 может быть
связана с несколькими записями в файле
F2. Условно это можно представить в виде,
изображенном на рис. 9.10
22)Условия достоверности данных, хранимые процедуры, триггеры
В реляционных базах данных, к которым относится и Visual FoxPro, для управления данными могут использоваться не только прикладные программы, но и непосредственно сервер базы данных. Данная возможность реализуется с помощью условий достоверности ввода данных, триггеров и хранимых процедур, которые являются неотъемлемой частью базы данных. Удобным средством просмотра хранящейся в базе данных информации являются представления данных, которые содержат результат выборки из одной или нескольких таблиц, удовлетворяющих заданному условию. Представления данных имеют много общего с запросами и таблицами. Так же, как и для запросов, вы можете связывать несколько таблиц, указывать отображаемые поля, задавать условие выборки. Просмотр представления данных осуществляется аналогично просмотру таблицы Visual FoxPro.
Условия достоверности позволяют контролировать ввод данных средствами сервера на уровне записей и полей таблицы. В первом случае условие определяется в окне ввода свойств таблицы, а во втором — в окне свойств поля таблицы. Проверка на уровне записи обычно используется, если необходима проверка при добавлении или удалении записи, а также если условие проверки изменения записи требует анализа более одного поля.
При определении условий достоверности ввода данных используются триггеры и хранимые процедуры. Триггеры задают действия, выполняемые при добавлении, удалении или изменении записей таблицы. Хранимые процедуры содержат наиболее часто используемые процедуры, выполняемые сервером базы данных. Если вы определили условия достоверности ввода данных, их проверка осуществляется независимо от способа изменения данных в таблице.
23)Язык SQL. Структура и типы данных языка SQL
SQL (обычно произносимый как "СИКВЭЛ" или "ЭСКЮЭЛЬ") символизирует собойСтруктурированный Язык Запросов. Это - язык, который дает Вам возможность создавать и работать в реляционных базах данных, являющихся наборами связанной информации, сохраняемой в таблицах.
Информационное пространство становится более унифицированным. Это привело к необходимости создания стандартного языка, который мог бы использоваться в большом количестве различных видов компьютерных сред. Стандартный язык позволит пользователям, знающим один набор команд, использовать их для создания, нахождения, изменения и передачи информации - независимо от того, работают ли они на персональном компьютере, сетевой рабочей станции, или на универсальной ЭВМ.
В нашем все более и более взаимосвязанном компьютерном мире, пользователь снабженый таким языком, имеет огромное преимущество в использовании и обобщении информации из ряда источников с помощью большого количества способов.
Элегантность и независимость от специфики компьютерных технологий, а также его поддержка лидерами промышленности в области технологии реляционных баз данных, сделало SQL (и, вероятно, в течение обозримого будущего оставит его) основным стандартным языком. По этой причине, любой, кто хочет работать с базами данных 90-х годов, должен знать SQL.
Язык SQL предназначен для манипулирования данными в реляционных базах данных, определения структуры баз данных и для управления правами доступа к данным в многопользовательской среде.
Поэтому, в язык SQL в качестве составных частей входят:
язык манипулирования данными (Data Manipulation Language, DML)
язык определения данных (Data Definition Language, DDL)
язык управления данными (Data Control Language, DCL).
Подчеркнем, что это не отдельные языки, а различные команды одного языка. Такое деление проведено только лишь с точки зрения различного функционального назначения этих команд.
Язык манипулирования данными используется, как это следует из его названия, для манипулирования данными в таблицах баз данных. Он состоит из 4 основных команд:
SELECT |
(выбрать) |
INSERT |
(вставить) |
UPDATE |
(обновить) |
DELETE |
(удалить) |
Структура языка SQL
Нужно заметить, что в настоящее время, ни одна система не реализует стандарт SQL в полном объеме. Кроме того, во всех диалектах языка имеются возможности, не являющиеся стандартными. Таким образом, можно сказать, что каждый диалект - это надмножество некоторого подмножества стандарта SQL. Это затрудняет переносимость приложений, разработанных для одних СУБД в другие СУБД.
Язык SQL оперирует терминами, несколько отличающимися от терминов реляционной теории, например, вместо "отношений" используются "таблицы", вместо "кортежей" - "строки", вместо "атрибутов" - "колонки" или "столбцы".
Стандарт языка SQL, хотя и основан на реляционной теории, но во многих местах отходит он нее. Например, отношение в реляционной модели данных не допускает наличия одинаковых кортежей, а таблицы в терминологии SQL могут иметь одинаковые строки. Имеются и другие отличия.
Язык SQL является реляционно-полным. Это означает, что любой оператор реляционной алгебры может быть выражен подходящим оператором SQL.
24) Оператор SELECT, используемые опции. Примеры
Оператор SELECT (выбрать) языка SQL является самым важным и самым часто используемым оператором. Он предназначен для выборки информации из таблиц базы данных. Упрощенный синтаксис оператора SELECT выглядит следующим образом.
SELECT [DISTINCT] <список атрибутов>
FROM <список таблиц>
[WHERE <условие выборки>]
[ORDER BY <список атрибутов>]
[GROUP BY <список атрибутов>]
[HAVING <условие>]
[UNION <выражение с оператором SELECT];
SELECT – устанавливается, какие столбцы должны присутствовать в выходных данных;
FROM – определяются имена используемых таблиц
WHERE – выполняется фильтрация строк объекта в соответствии с заданными условиями; ORDER BY – определяется упорядоченность результатов выполнения операторов.
В квадратных скобках указаны не обязательные элементы в запросе. Ключевое слово SELECT сообщает базе данных, что данная запись, является запросом на извлечение информации. После слова SELECT через запятую перечисляются наименования полей (список атрибутов), содержимое которых запрашивается. Обязательным ключевым словом в запросе SELECT является слово FROM (из какой таблицы извлекать). За ключевым словом FROM указывается список разделенных запятыми имен таблиц, из которых извлекается информация.
Пример
Написать запрос который выведет Имена и фамилии всех студентов из таблицы STUDENT которые проживают в городе Новгород.
SELECT SURNAME, NAME
FROM STUDENT
WHERE CITY = 'Новгород'
25) Агрегатные функции языка SQL, их использование в запросах. Примеры.
Для подведения итогов по данным, содержащимся в БД, в языке SQL предусмотрены агрегатные (статистические) функции. Агрегатная функция берет в качестве аргумента какой-либо столбец (для множества строк), а возвращает одно значение, определяемое типом функции:
AVG - среднее значение в столбце;
SUM - сумма значений в столбце;
MAX - наибольшее значение в столбце;
MIN - наименьшее значение в столбце;
COUNT - количество значений в столбце.
Аргументами агрегатных функций могут быть как столбцы таблицы, так и результаты выражений над ними. При этом выражение может быть сколь угодно сложным.
Вложенность агрегатных функций не допускается, однако из этих функций можно составлять любые выражения.
Для функций SUM и AVG столбец должен содержать числовые значения.
Специальная функция COUNT (*) служит для подсчета всех без исключения строк в таблице (включая дубликаты).
Аргументу всех функций, кроме COUNT (*), может предшествовать ключевое слово DISTINCT (различный), указывающее, что избыточные дублирующие значения должны быть исключены перед тем, как будет применяться функция.
Если не используется предложение GROUP BY, но в предложении SELECT используется какая-либо агрегатная функция, то в качестве возвращаемых элементов нельзя указывать по отдельности столбцы таблиц (можно лишь в качестве аргументов агрегатных функций)
.
Первые две функции (сумма и среднее) могут быть вычислены только по числовым столбцам, максимальное и минимальное значения могут быть определены для столбцов всех типов (кроме больших объектов), при этом строки текста сравниваются в лексикографическом, а даты - в хронологическом порядке. Например:
Подсчитать средний балл по всем студентам и предметам SELECT AVG (mark) avg mark FROM mark
26) Группирование результатов в запросах
При группировке формируются группы с одинаковыми значениями в столбце группировки (или нескольких столбцах), запрос возвращает столько строк, сколько получилось групп. Фактически количество групп совпадает с количеством уникальных значений в столбце группировки, поэтому группировку принято выполнять по столбцам, содержащим большое количество повторяющихся значений. Тогда количество групп будет значительно меньше, чем количество строк в таблице.
27) Создание многотабличных запросов
Опция |
Тип создаваемой связи |
Inner join
(Внутреннее объединение) |
Создает объединение, в котором выбираются только те записи, которые содержат совпадающие значения в полях связи |
Left join
(Объединение слева) |
Создает объединение, в котором выбираются все записи из левой таблицы, а также записи из правой таблицы, значения поля связи которого совпадают со значениями поля связи левой таблицы |
Right join
(Объединение справа) |
Создает объединение, в котором выбираются все записи из правой таблицы, а также записи из левой таблицы, значения поля связи которого совпадают со значениями поля связи правой таблицы |
Full join (Полное объединение) |
Создает объединение, в котором выбираются все записи из правой и левой таблиц |
28) Язык SQL. Оператор добавления записей INSERT. Пример использования
Оператор Insert предназначен для добавления новых данных в таблицу. Он имеет следующий формат: INSERT INTO TableName [(columnList)] VALUES (dataValueList); Здесь параметр TableName (Имя таблицы) может представлять имя таблицы базы данных. Параметр columnList (Список столбцов) представляет собой список, состоящий из имен одного или более столбцов, разделенных запятыми. Параметр columnList является необязательным. Если он опущен, то предполагается использование списка из имен всех столбцов таблицы, указанных в том порядке, в котором они были описаны в операторе CREATE TABLE. Параметр dataValueList (Список значений данных) должен следующим образом соответствовать параметру columnList: количество элементов в обоих списках должно быть одинаковым; должно существовать прямое соответствие между позицией одного и того же элемента в обоих списках типы данных элементов списка dataValueList должны быть совместимы с типом данных соответствующих столбцов таблицы. Пример использования оператора Insert. Задание: Поместите в таблицу staff новую запись, содержащую данные во всех столбцах. INSERT INTO Staff VALUES('SG16', 'Alan', 'Brown', 'Assistant’, 'M’, DATE '1957-05-25',8300, 'B003');
29)Язык SQL. Оператор изменения записей UPDATE. Пример использования
Оператор Update позволяет изменять содержимое уже существующих строк указанной таблицы. Этот оператор имеет следующий формат: UPDATE tableName SET columnNamel = dataValuel [, columnName2 = dataValue2 … ] [WHERE searchCondition]; Здесь параметр tableName представляет имя таблицы базы данных. В конструкции SET указываются имена одного или более столбцов, данные в которых необходимо изменить. Конструкция WHERE является необязательной. Если она опущена, значения указанных столбцов будут изменены во всех строках таблицы. Если конструкция WHERE присутствует, то обновлены будут только те строки, которые удовлетворяют условию поиска, заданному в параметре searchCondition. Параметры dataValue1, dataValue2... представляют новые значения соответствующих столбцов и должны быть совместимы с ними по типу данных. Пример использования оператора Update. Задание: Всем менеджерам компании повысить заработную плату на 5%. UPDATE Staff SET salary = salary*1.05 WHERE position = 'Manager’;
30)Язык SQL. Оператор удаления записей DELETE. Пример использования
Оператор Delete позволяет удалять строки данных из указанной таблицы. Этот оператор имеет следующий формат: DELETE FROM tableName [WHERE searchCondition]; Как и в случае операторов INSERT и UPDATE, параметр TableName представляет собой таблицы базы данных. Параметр searchCondition является необязательным — если он опущен, из таблицы будут удалены все существующие в ней строки. Однако сама по себе таблица удалена не будет. Если необходимо удалить не только содержимое таблицы, но и ее определение, следует использовать оператор DROP TABLE. Если конструкция WHERE присутствует, из таблицы будут удалены только те строки, которые удовлетворяют условию отбора, заданному параметром searchCondition Пример использования оператора Delete. Задание: Удалить все записи об осмотрах сдаваемого в аренду объекта с учетным номером PG4. DELETE FROM Viewing WHERE propertyNo = 'PG4';
31) Язык SQL. Операторы определения данных. Создание таблиц CREATE TABLE
CONSTRAINT — необязательное ключевое слово, после которого указывается название ограничения на значения столбца (имя_ограничения). Имена ограничений должны быть уникальны в пределах базы данных. DEFAULT — задает значение по умолчанию для столбца. Это значение будет использовано при вставке строки, если для столбца явно не указано никакое значение. NULL|NOT NULL — ключевые слова, разрешающие (NULL) или запрещающие (NOT NULL) хранение в столбце значений NULL. Если для столбца не задано значение по умолчанию, то при вставке строки с неизвестным значением для столбца будет предприниматься попытка вставки в столбец значения NULL. Если при этом для столбца указано ограничение NOT NULL, то попытка вставки строки будет отклонена, и пользователь получит соответствующее сообщение об ошибке. PRIMARY KEY — определение первичного ключа на уровне одного столбца (т. е. первичный ключ будет состоять только из значений одного столбца). Если необходимо сформировать первичный ключ на базе двух и более столбцов, то такое ограничение целостности должно быть задано на уровне таблицы. При этом следует помнить, что для каждой таблицы может быть создан только один первичный ключ. UNIQUE — указание на создание для столбца ограничения целостности UNIQUE, что позволит гарантировать уникальность каждого отдельного значения в столбце в пределах этого столбца. В таблице может быть создано несколько ограничений целостности UNIQUE. FOREIGN KEY ... REFERENCES — указание на то, что столбец будет служить внешним ключом для таблицы, имя которой задается с помощью параметра <имя_главной_таблицы>. (имя столбца [,...,n]) — столбец или список перечисленных через запятую столбцов главной таблицы, входящих в ограничение FOREIGN KEY. При этом столбцы, входящие во внешний ключ, могут ссылаться только на столбцы первичного ключа или столбцы с ограничением UNIQUE таблицы. ON DELETE {CASCADE | NO ACTION} — эти ключевые слова определяют действия, предпринимаемые при удалении строки из главной таблицы. Если указано ключевое слово CASCADE, то при удалении строки из главной (родительской) таблицы строка в зависимой таблице также будет удалена. При указании ключевого слова NO ACTION в подобном случае будет выдана ошибка. Значением по умолчанию является вариант NO ACTION. ON UPDATE {CASCADE | NO ACTION} - эти ключевые слова определяют действия, предпринимаемые при модификации строки главной таблицы. Если указано ключевое слово CASCADE, то при модификации строки из главной (родительской) таблицы строка в зависимой таблице также будет модифицирована. При использовании ключевого слова NO ACTION в подобном случае будет выдана ошибка. Значением по умолчанию является вариант NO ACTION. CHECK — ограничение целостности, инициирующее контроль вводимых в столбец (или столбцы) значений;
Примеры создания таблиц В качестве примера рассмотрим инструкции создания таблиц базы данных «Сессия». Таблица «Студенты» состоит из следующих столбцов: ID_Студент — тип данных INTEGER, уникальный ключ; Фамилия — тип данных CHAR, длина 30; Имя — тип данных CHAR, длина 15; Отчество — тип данных CHAR, длина 20; Номер_группы — тип данных CHAR, длина 6; Адрес — тип данных CHAR, длина 30; Телефон — тип данных CHAR, длина 8. Создание таблицы выполнялось с помощью следующей команды: CREATE TABLE Студенты (ID_Студент INTEGER NOT NULL, Фамилия CHAR(30) NOT NULL, Имя CHAR(15) NOT NULL, Отчество CHAR(20) NOT NULL, Номер_группы INTEGER NOT NULL, Адрес CHAR(30), Телефон CHAR(8), PRIMARY KEY (ID_Студент) )
Создание таблицы выполняется при помощи команды CREATE TABLE. Обобщенный синтаксис команды следующий: CREATE TABLE имя_таблицы ({<определение__столбца>|<определение_ограничения_таблицы>} [,...,{<определение_стол6ца>|<определение_ограничения_таблицы >}]) То есть после задания имени таблицы через запятую в круглых скобках должны быть перечислены все предложения, определяющие отдельные элементы таблицы, — столбцы или ограничения целостности: имя_таблицы — идентификатор создаваемой таблицы, который в общем случае строится из имени базы данных, имени владельца таблицы и имени самой таблицы. При этом комбинация имени таблицы и ее владельца должна быть уникальной в пределах базы данных. Если таблица создается не в текущей базе данных, в ее идентификатор необходимо включить имя базы данных; определение_столбца — задание имени, типа данных и параметров отдельного столбца таблицы. Названия столбцов должны соответствовать правилам для идентификаторов и быть уникальными в пределах таблицы; определение_ограничения_таблицы — задание некоторого ограничения целостности на уровне таблицы. Описание столбцов Как видно из синтаксиса команды CREATE TABLE, для каждого столбца указывается предложение <определение_столбца>, с помощью которого и задаются свойства столбца. Предложение имеет следующий синтаксис: <Имя_столбца> <тип_данных> [<ограничение_столбца> ] [,...,<ограничение_столбца>] Имя_столбца — идентификатор, задающий имя столбца таблицы; Тип_данных — задает тип данных столбца. Если при определении столбца явно не указано ограничение на хранение значений NULL, то будут использованы свойства типа данных, т. е. если выбранный тип данных позволяет хранить значения NULL, то и в столбце можно будет хранить значения NULL. Если же при определении столбца в команде CREATE TABLE явно будет разрешено или запрещено хранение значений NULL, то свойства типа данных будут перекрыты установленным на уровне столбца ограничением. Например, если тип данных позволяет хранить значения NULL, a на уровне столбца будет установлен запрет, то попытка вставки значения NULL в столбец закончится ошибкой; Ограничение_столбца — с помощью этого предложения указываются ограничения, которые будут определены для столбца. Синтаксис предложения следующий: <ограничение_столбца>::=[ CONSTRAINT <имя_ограничения > ] {[ DEFAULT <выражение>] | [NULL | NOT NULL] | [PRIMARY KEY | UNIQUE] | [FOREIGN KEY REFERENCES <имя_главной_таблицы>[(<имя_столбца> [,...,n])] ^ [ON DELETE {CASCADE | NO ACTION}] [ON UPDATE {CASCADE | NO ACTION}] ]
| [CHECK (<логическое_выражение>)] }
ОПРЕДЕЛЕНИЯ!!!!!!!!
Информационная система – взаимосвязанная совокупность средств, методов и персонала, используемых для хранения, обработки и выдачи информации в интересах достижения поставленной цели.
База данных (БД) – это поименованная совокупность структурированных данных, относящихся к определенной предметной области.
Система управления базами данных (СУБД) – это комплекс программных и языковых средств, необходимых для создания баз данных, поддержания их в актуальном состоянии и организации поиска в них необходимой информации.
Трехуровневая архитектура СУБД: внешний уровень, концептуальный уровень, внутренний уровень.
Концептуальный уровень – обобщающее представление базы данных. Этот уровень описывает то, какие данные хранятся в базе данных, а также связи, существующие между ними.
Концептуальное проектирование базы данных – процесс создания модели данных, не зависящей от любых физических аспектов ее представления.
Модель данных — это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними.
ER-модель (Entity Relationship) – модель «Сущность-связь», предложена Ченом при инфологическом моделировании баз данных.
Сущность – отображение объекта в памяти человека или компьютера.
Атрибут – свойство, которое описывает некоторую характеристику объекта.
Информационно-логическая (инфологическая) модель предметной области отражает предметную область в виде совокупности информационных объектов и их структурных связей.
Связь – бинарная ассоциация, показывающая, каким образом сущности соотносятся или взаимодействуют между собой.
Связь один к одному (1:1) предполагает, что в каждый момент времени одному экземпляру информационного объекта А соответствует не более одного экземпляра информационного объекта В и наоборот.
Связь один ко многим (1:М) предполагает, что одному экземпляру информационного объекта А соответствует 0,1 или более экземпляров объекта В, но каждый экземпляр объекта В связан не более чем с 1 экземпляром объекта А.
Связь многие ко многим (М:М) предполагает, что в каждый момент одному экземпляру информационного объекта А соответствует 0, 1 или более экземпляров объекта В и наоборот.
Модель данных — совокупность структур данных и операций их обработки.
Виды моделей данных (баз данных): иерархическая, сетевая, реляционная.
Для иерархических структур характерна подчиненность объектов нижнего уровня объектам верхнего уровня.
В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом. Один и тот же объект может выступать как главный и как подчиненный. Допускаются связи на одном уровне.
Реляционная база данных — это конечный (ограниченный) набор отношений, которые используются для представления объектов, а также для представления связей между объектами.
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
каждый элемент таблицы — один элемент данных;
все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину;
каждый столбец (атрибут) имеет уникальное имя;
в таблице нет двух одинаковых строк;
порядок следования строк и столбцов может быть произвольным.
Отношение — это двумерная таблица, имеющая уникальное имя и состоящая из строк и столбцов, где строки соответствуют записям, а столбцы — атрибутам. Каждая строка в таблице представляет некоторый объект реального мира или соотношения между объектами.
Атрибут (поле) — это поименованный столбец отношения.
Домен – набор допустимых значений одного или нескольких атрибутов.
Первичный ключ – это атрибут или группа атрибутов, которые однозначно определяют каждую запись в таблице. Первичный ключ всегда должен быть уникальным, то есть его значения не должны повторяться.
Внешний ключ – атрибут или множество атрибутов одного отношения, которое соответствует потенциальному ключу другого отношения.
Нормализация отношений — формальный аппарат ограничений на формирование отношений (таблиц), который позволяет устранить дублирование, обеспечивает непротиворечивость хранимых в базе данных, уменьшает трудозатраты на ведение (ввод, корректировку) базы данных.