

Вопрос 20
Таблицы страниц бывают различной структуры – иерархические, хешированные и инвертированные. Хешированные таблицы страниц требуют поиска нужной страницы по хеш-списку. Инвертированные таблицы страниц требуют поиска нужной физической страницы по номеру процесса и логическому номеру страницы.
Структура таблицы страниц
Иерархические таблицы страниц.Таблицы страниц в операционных системах могут быть по-разному организованы, при сохранении общих принципов их использования, описанных ранее. Рассмотрим далее три основных способа организации таблиц страниц – иерархические таблицы страниц, хешированные таблицы страниц и инвертированные таблицы страниц.
Чаще всего используются иерархические таблицы страниц.При их использовании логическое адресное пространство разбивается на несколько таблиц страниц (иначе говоря, используются таблицы таблиц страниц ). Наиболее простой и распространенный метод – двухуровневая таблица страниц.
При обычной организации таблицы страниц, логический адрес (для 32-разрядной архитектуры, при размере страницы 4 килобайта = 4096 байтов) разбивается на номер страницы (20 битов) и смещение внутри страницы (12 битов).
При двухуровневой организациии таблицы страниц, таблица страниц верхнего уровня сама делится на страницы, поэтому логический адрес будет иметь вид: (p1, p2, d),где p1 – индекс во внешней таблице страниц, p2 – смещение внутри страницы для внешней таблицы страниц, d – смещение внутри страницы (адресуемой по внутренней таблице страниц). При тех же предположениях об архитектуре и размере страницы, p1 и p2 будут занимать по 10 битов.
Организация двухуровневых таблиц страниц изображена на рис. 16.9.

Рис. 16.9. Организация двухуровневых таблиц страниц.
Схема адресной трансляции по двухуровневой
таблице страниц иллюстрируется рис.
16.10.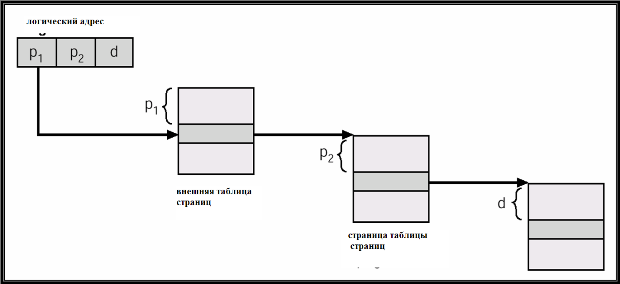 Рис.
16.10. Схема адресной трансляции по
двухуровневой таблице страниц.
Рис.
16.10. Схема адресной трансляции по
двухуровневой таблице страниц.
Хешированные таблицы страниц
Структура таблицы страниц, описанная в данном разделе, базируется на понятии хеш-функции (hash function) - целочисленной функции hash, определенной на элементах s некоторого пространства поиска S (строках, больших числах и др.) и принимающей значения из отрезка [0, H-1] где H – натуральное число. Общая идея поиска с помощью хеш-функций заключается в следующем: пространство поиска разбивается на H непересекающихся подмножеств (списков) Sh, в каждом из которых хранятся элементы, имеющие одинаковое значение хеш-функции, равное h. Таким образом, применение хеш-функции позволяет сократить поиск в среднем в H раз: при поиске элемента s сначала вычисляем hash(s),а затем выполняем поиск только в списке Shash(s) Для облегчения доступа к хеш-спискам хранится также хеш-оглавление – таблица, индексируемая значением хеш-функции, каждый элемент которой содержит ссылку на начало соответствующего списка.
Хешированные таблицы страниц используются, если адресное пространство 64-битное или большей разрядности. Очевидно, что в этом случае, при прямолинейном подходе, размеры таблиц страниц оказались бы слишком велики. Поэтому используется другой метод. Логический номер страницы хешируется (т.е. для него вычисляется хеш-функция). Полученное число (реальный номер страницы) используется как индекс в хеш-оглавлении, ссылающемся на список страниц, хешируемых в один и тот же номер. В найденном таким образом списке и выполняется поиск нужной страницы. Данный способ организации таблицы страниц и схема адресации иллюстрируются рис. 16.11
 Рис.
16.11. Хешированные таблицы страниц.
Рис.
16.11. Хешированные таблицы страниц.
Инвертированные таблицы страниц
Данный способ организации таблиц страниц предназначен для сокращения размеров таблиц страниц. В таблице страниц хранится один элемент для каждой реальной страницы, находящейся в памяти. К логическому адресу добавляется номер процесса (pid) владеющего данной страницей. По паре (номер процесса = pid, номер страницы = p) выполняется ассоциативный поиск в таблице страниц. Индекс найденного элемента таблицы i конкатенируется со смещением d внутри страницы, в результате получается физический адрес. Инвертированные таблицы страниц иллюстрируются рис. 16.12.
 Рис.
16.12. Инвертированные таблицы страниц.
Рис.
16.12. Инвертированные таблицы страниц.
Разделяемые страницы
Разделяемые (совместно используемые) страницы – логические страницы, используемые несколькими процессами и имеющие один и тот же номер в таблице страниц каждого из процессов. Данный механизм полезен для экономии памяти, так как позволяет загружать в память в единственном экземпляре не изменяемую информацию, необходимую нескольким процессам – например, код и массивы констант.
Пример использования разделяемых страниц тремя процессами приведен на рис. 16.13. Три процесса используют одни и те же коды трех редакторов ed1, ed2, ed3, логические страницы которых имеют для обоих процессов номера 0, 1 и 2. Кроме того, каждый процесс использует свои индивидуальные данные data1, data2, data3.
 Рис.
16.13. Разделяемые страницы.
Рис.
16.13. Разделяемые страницы.
Принципы сегментной организации памяти
Сегментная организация памяти (segmentation) - схема распределения памяти в виде сегментов переменной длины, соответствующая пользовательской трактовке распределения памяти, т.е. логической структуре программ и данных. С точки зрения пользователя (разработчика программы), программа – это набор модулей кода и данных, каждому из которых должен соответствовать свой сегмент в памяти. Сегмент – логическая единица распределения памяти, предназначенная для размещения в памяти одного модуля программного кода или данных. Например, в виде сегментов памяти могут быть представлены:
основная программа;
процедура;
функция;
метод;
объект;
набор локальных переменных;
набор глобальных переменных;
общий блок данных (например, COMMON-блок в языке FORTRAN);
стек;
таблица символов;
массив.
рис. 17.1 иллюстрирует данную точку зрения на программу как на набор сегментов в памяти.
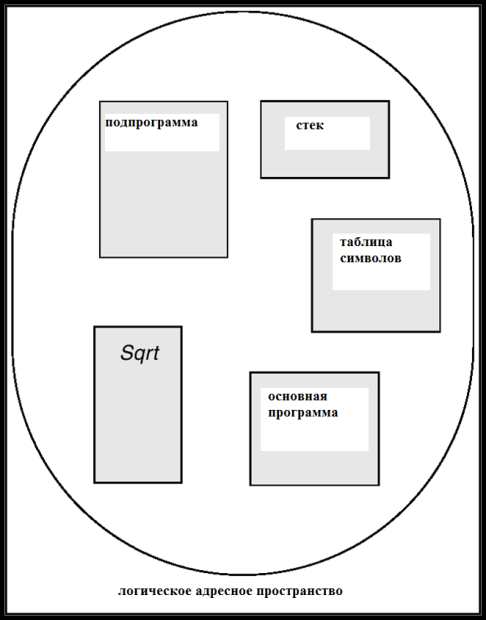
Рис. 17.1. Программа как набор сегментов.
Архитектура сегментной организации памяти
Многие принципы архитектуры сегментной организации схожи с принципами страничной организации (см. "Страничная организация памяти"), однако во всех случаях приходится учитывать, что длина сегмента переменна, и хранить ее в явном виде в таблицах.
Логический адрес при сегментной организации памяти - пара:
<segment-number, offset>,
где segment-number – номер сегмента, offset – смещение в сегменте.
Таблица сегментов – служит для отображения логических адресов в физические при сегментной организации памяти. Каждый ее элемент содержит следующую информацию:
base – начальный адрес сегмента в оперативной (физической) памяти;
limit – длину сегмента.
Базовый регистр таблицы сегментов - segment-table base register (STBR) содержит адрес таблицы сегментов в памяти.
Регистр длины таблицы сегментов - segment-table length register (STLR) содержит число сегментов, используемое программой.
Номер сегмента s корректен, если s < STLR.
Перемещение (relocation) программ и данных при сегментной организации динамическое, т.е. выполняется во время исполнения программы с помощью таблицы сегментов.
Возможен общий доступ (sharing) нескольких процессов к одному и тому же сегменту, т.е. поддерживается концепция разделяемых сегментов. При этом логический номер общего сегмента для разных процессов будет одним и тем же.
Стратегии распределения памяти при сегментной организации: метод первого подходящего или метод наиболее подходящего (см. "Страничная организация памяти"). Метод наименее подходящего при сегментной организации смысла не имеет, так как он не улучшает ситуацию с фрагментацией (ввиду переменной длины сегментов). Соответственно, при сегментной организации возможна внешняя фрагментация, для борьбы с которой применяется компактировка (см. "Страничная организация памяти").
Защита при сегментной организации организована аналогично защите при страничной организации, однако, ввиду того, что каждый сегмент выполняет определенную логическую функцию в программе, дополнительно с каждым сегментом связываются его признаки защиты. Таким образом, в каждом элементе таблицы сегментов хранятся:
validation-бит (аналогично страничной организации): значение бита, равное 0, означает, что сегмент неверный, т.е. не принадлежит логической памяти процесса;
полномочия чтения (read) / записи (write) / исполнения (execute) – каждое кодируется одним битом; значение бита, равное 0, означает, что процесс не имеет данных полномочий.
Например, если сегмент является сегментом данных, то система устанавливает в таблице сегментов бит защиты от исполнения равным 0. Если это сегмент кода, то целесообразна установка в 0 битов защиты от чтения и от записи.
Биты защиты связываются с сегментами. Совместный доступ к коду осуществляется на уровне сегментов.
В системе "Эльбрус" к стандартному набору признаков защиты был добавлен еще один: защита от записи в сегмент адресной информации (данный признак целесообразен, если, например, сегмент предназначен для записи в файл).
Поскольку сегменты различаются по длине, распределение памяти в виде сегментов – это общая задача динамического распределения памяти (см. "Страничная организация памяти").
На рис. 17.2 приведена схема адресации
при сегментном распределении памяти.
Логический адрес (s, d), где s – номер
сегмента, d – смещение внутри сегмента,
обрабатывается следующим образом. По
номеру сегмента s происходит обращение
в таблицу сегментов, и определяется
база сегмента – его начальный адрес в
основной памяти. Смещение d сравнивается
с длиной (границей) сегмента. Если оно
меньше, то оно складывается с базой, и
в результате получается физический
адрес, по которому и происходит обращение
в память. Если смещение больше или равно
базе, происходит прерывание – ошибка
адресации. На схеме не показана еще одна
проверка – для номера сегмента s
проверяется, что он не превосходит
значения регистра длины таблицы
сегментов, иначе – прерывание.
Рис. 17.2. Схема адресации при сегментной организации памяти.
Пользователи систем UNIX, Linux, Solaris наверняка по ассоциации вспомнят часто встречающееся системное сообщение: Segmentation violation (нарушение сегментации) при прерывании. Причина подобного сообщения обычно следующая: программа пытается обратиться по пустому (нулевому) указателю, номер сегмента в котором, естественно, равен 0, а номер сегмента 0 считается в системе недопустимым. Таким образом, через проверку номера сегмента, UNIX защищает от такой часто встречающейся ошибки, как обращение по пустому указателю. Аналогично, по той же самой причине, если программа пытается практически любое другое число (например, 5) рассматривать как адрес и обращаться по нему, то также генерируется прерывание и сигнал SIGSEGV (segmentation violation).
Сегментно-страничная организация памяти в системах MULTICS и "Эльбрус"
Сегментное распределение памяти, как видно из предыдущих пунктов, имеет свои неоспоримые преимущества. Однако, к сожалению, проблема внешней фрагментации при чисто сегментной организации памяти весьма серьезна.
Поэтому в системе MULTICS проблемы внешней фрагментации и длительного времени поиска решены путем страничной организации памяти для сегментов. Данное решение отличается от чисто сегментной организации тем, что элемент таблицы сегментов содержит не базовый адрес сегмента, а базовый адрес таблицы страниц для данного сегмента.
В системе "Эльбрус" данные проблемы решены по-другому: в системе используется страничная организация для математической (виртуальной, логической) памяти и сегментная организация – для физической памяти. Математическая память (т.е. образ памяти на диске) распределяется с точностью до страницы, а физическая – с точностью до слова. Кроме того, как уже отмечалось, для адресации в системе "Эльбрус" используются дескрипторы массивов, содержащие начальный адрес, длину и признаки защиты массива.
Схема трансляции адресов в MULTICS приведена
на рис. 17.5. Рис.
17.5. Схема трансляции адресов в MULTICS.
Рис.
17.5. Схема трансляции адресов в MULTICS.
Логический адрес (s, d) используется следующим образом. Номер сегмента s складывается с содержимым регистра STBR, после чего происходит обращение по полученному адресу в таблицу сегментов. Смещение d сравнивается с длиной сегмента; если оно больше или равно длине сегмента,то прерывание. Из элемента таблицы сегментов извлекается адрес базы таблицы страниц данного сегмента, который складывается со старшими разрядами смещения (p). Младшие разряды смещения используются как смещение внутри страницы, адрес которой извлекается из таблицы страниц данного сегмента.
Нельзя не отметить, что данная схема, на наш взгляд, несколько усложнена. Система MULTICS, в которой этот и многие другие механизмы доведены, казалось бы, до совершенства, вызвала противоположную тенденцию в развитии ОС – к упрощению. Как мы уже говорили, даже название следующей системы – UNIX – выбрано как противоположность MULTICS, что говорит о многом. Таковы тенденции развития во многих областях, в том числе и в операционных системах.
Сегментно-страничная организация памяти в системе Intel 386
В более современных системах, чем
MULTICS, также используется сегментно-страничная
организация. Например, в системе Intel 386
используется сегментно-страничная
организация памяти с двухуровневой
схемой страничной организации (см. рис.
17.6). Рис.
17.6. Сегментно-страничная организация
памяти в Intel 386.
Рис.
17.6. Сегментно-страничная организация
памяти в Intel 386.
21. Мотивировка концепции виртуальной памяти
Концепция виртуальной памяти основана на идеях отделения логической памяти пользователя от физической памяти и расширения логической памяти путем хранения ее образа на диске.
При исполнении программы только часть ее кода и данных, к которым происходит обращение, в каждый момент требует размещения в физической памяти. Поэтому, естественно, возникает идея расширить пространство логической памяти, которое может быть реализовано намного большего размера, чем физическая память. Это и есть основной принцип организации виртуальной памяти.
Виртуальная память поддерживает совместное использование одного и того же адресного пространства более чем одним процессом, создание и исполнение облегченных процессов в общем пространстве виртуальной памяти.
Виртуальная память допускает более эффективное создание процесса, чем предшествующие схемы организации памяти и процессов.
Заметим, что концепция виртуальной памяти непосредственно не связана ни со страничной, ни с сегментной стратегиями распределения памяти. Виртуальная память может быть реализована различными способами, например, с помощью:
страничной организации по требованию (paging on demand);
сегментной организации по требованию (segmentation on demand).
В приведенных терминах подчеркивается динамический характер управления виртуальной памятью: термин по требованию означает, что страница или сегмент будут размещены в физической памяти только в случае, если к ним реально происходит обращение из программы пользователя. Причем если размер обрабатываемой области виртуальной памяти (например, массива) очень велик – например, 1000 страниц, то в физической памяти будет размещена только та его страница, к которой обращается пользовательская программа.
Принцип управления виртуальной памятью
иллюстрируется рис. 18.1.

Рис. 18.1. Виртуальная память и физическая память.
Из схемы видно, что виртуальная память, как предполагается, больше, чем физическая память. Взаимодействие между частями виртуальной памяти и физической памяти происходит через отображение памяти – системную таблицу (сегментов, страниц и т.п.). Образ виртуальной памяти процесса хранится на диске.
Страничная организация по требованию
Принцип реализации виртуальной памяти в виде страничной организации по требованию заключается в том, что каждая страница загружается в память, только если она реально требуется при выполнении программы – содержит код или данные, к которым произошло обращение.
Преимущества данного подхода:
Меньший объем ввода-вывода: В память подкачивается только минимально необходимый объем данных (например, одна страница большого массива, а не весь многостраничный массив);
Меньший объем памяти: При данном способе расходуется минимально необходимый объем физической памяти;
Более быстрая реакция системы: Поскольку объем пересылаемых данных меньше, система в среднем быстрее реагирует на каждый запрос к памяти;
Система может обслуживать большее число пользователей: Ввиду экономии физической памяти и времени обращения, система в состоянии при данном подходе обслуживать большее число пользовательских процессов.
Основные принципы страничной организации по требованию:
Если страница требуется программе, на нее имеется ссылка из программы.
Если ссылка на страницу неверна (например, страницы с данным номером не существует), происходит прерывание.
Если требуемая страница отсутствует в памяти, то она подкачивается в память. Механизм подкачки реализуется через прерывание (page fault – отказ страницы).
рис. 18.2 иллюстрирует размещение
виртуальной памяти на диске и ее откачку
и подкачку.

Рис. 18.2. Преобразование страничной памяти в непрерывное дисковое пространство.
Из схемы видно, что, с точки зрения каждой программы, пространство ее виртуальной памяти непрерывно. Оно преобразуется в непрерывную область дисковой памяти. С помощью механизма откачки – подкачки в нужный момент страница виртуальной памяти размещается в основной памяти.
С каждым элементом таблицы страниц связывается бит "valid/invalid",однако, в отличие от организации логической памяти, он играет несколько иную роль – он указывает на присутствие или отсутствие страницы в основной памяти. Значение бита равно 1, если страница в памяти, и 0, если ( страница отсутствует в памяти.
Первоначально для всех элементов таблицы страниц бит valid/invalid полагается равным 0.
Если в процессе трансляции адреса бит "valid/invalid" в таблице страниц оказыется равным 0, то происходит прерывание по отсутствию страницы в памяти (page fault).
На рис. 18.3 приведен пример таблицы
страниц, в которой не все страницы
присутствуют в основной памяти.
 Рис.
18.3. Пример таблицы страниц, в которой
не все страницы в памяти.
Рис.
18.3. Пример таблицы страниц, в которой
не все страницы в памяти.
На схеме логическия память процесса состоит из 6 страниц с номерами от 0 до 5. Однако только страницы 0, 2, 5 размещены в основной памяти (бит valid/invalid имеет значение v = 1). Страницы 1, 3, 4 в основной памяти отсутствуют (бит valid/invalid равен i = 0).
Обработка ситуации отсутствия страницы в памяти
Если в таблице страниц имеется ссылка на страницу, отсутствующую в памяти, первое же обращение по такой ссылке приведет к прерыванию и вызову ОС (ситуации page fault – отсутствие страницы в памяти)
ОС по таблицам определяет, что именно произошло:
Если имеет место неверная ссылка (на страницу, отсутствующую в логической памяти), то работа программы прекращается.
Если же имеет место обычное отсутствие страницы в памяти, то ОС должна разместить его в основной памяти. Для этого ОС выполняет следующий алгоритм:
Найти незанятый фрейм в основной памяти ;.
Считать содержимое страницы в данный фрейм ;
Изменить элемент таблицы страниц: validation-бит установить равным 1;
Продолжить работу программы. Напомним, что программа после прерывания продолжается с той же команды, которая была прервана из-за отсутствия страницы. Поэтому теперь программа продолжит нормально выполняться, и обращение к странице произойдет успешно.
Этапы обработки ситуации отсутствия страницы в памяти показаны на рис. 18.4.
 Рис.
18.4. Обработка ситуации отсутствия
страницы в памяти.
Рис.
18.4. Обработка ситуации отсутствия
страницы в памяти.
Этап 1 – выполнение команды load M, которая прерывается по отсутствию страницы в памяти; 2 – прерывание и вызов ОС; 3 – обращение к странице, находящейся в файле откачки на диске; 4 – считывание страницы в память на свободный фрейм; 5 – изменение элемента таблицы страниц; 6 – повторное (успешное) выполнение команды.
Проблема замещения страниц
Для предотвращение переполнения памяти, подпрограмма обслуживания отказов страниц дополняется поддержкой замещения страниц.
Для сокращения времени передачи страниц используется бит модификации в таблице страниц: только модифицированные страницы откачиваются на диск.
Замещение страниц дополняет картину и стратегию разделения между виртуальной и физической памятью – большая виртуальная память может быть отображена на небольшую физическую память.
Пример замещения страниц приведен на
рис. 18.6.
 Рис.
18.6. Пример замещения страниц.
Рис.
18.6. Пример замещения страниц.
В примере имеются два пользовательских процесса, каждый из которых использует по 4 страницы виртуальной памяти. Однако имеется только 6 фреймов в основной памяти, выделенных для пользовательских процессов, (начальные фреймы занимает резидентный монитор ОС). В процессе 1 происходит обращение к данным M, расположенным на странице 3 виртуальной памяти, отсутствующей в основной памяти. В процессе 2 точно так же может произойти обращение к данным B на странице виртуальной памяти 1, которой также нет в основной памяти. Следовательно, ОС должна выполнить замещение страниц, т.е. решить две задачи:
по какому принципу выбирать "жертвы", т.е. страницы для откачки, находящиеся в оперативной памяти, для освобождения необходимых фреймов?
в каком порядке обслужить процессы 1 и 2, в каждом из которых возникла необходимость в свободном фрейме?
Кратко алгоритм замещения страниц можно сформулировать следующим образом:
Найти, где размещается требуемая страница на диске.
Найти свободный фрейм:
Если есть свободный фрейм, использовать его.
Если нет свободных фреймов, использовать алгоритм замещения страниц для выбора фрейма -"жертвы".
Прочитать содержимое требуемой страницы во вновь освобожденный фрейм. Модифицировать таблицы фреймов и страниц.
Продолжить выполнение процесса.
На рис. 18.7 иллюстрируется момент замещения страниц, с предварительной откачкой страницы-жертвы на диск.
 Рис.
18.7. Замещение страниц с откачкой жертвы
на диск.
Рис.
18.7. Замещение страниц с откачкой жертвы
на диск.
Этапы замещения страниц: 1 – откачка жертвы; 2 – изменение ее элемента таблицы страниц (бит valid заменяется на invalid); 3 – подкачка на освободившееся место желаемой страницы; 4 – изменение элемента таблицы страниц для новой страницы (бит invalid заменяется на valid; запоминается физический адрес подкачанной страницы).
Преимущества виртуальной памяти при создании процессов (совместное использование страниц и файлы, отображаемые в память)
Благодаря механизму виртуальной памяти, могут быть использованы следующие оптимизации расходования памяти при создании процессов:
Копирование по записи (Copy-on-Write)
Отображение файлов в память (Memory-Mapped Files).
Принцип совместного использования страниц процессами (или копирование по записи - Copy-On-Write, COW) позволяет первоначально родительскому и дочернему процессам использовать одни и те же страницы памяти. Если какой-либо процесс модифицирует разделяемую страницу, то только в этом случае данная страница копируется. Принцип COW обеспечивает более эффективное создание процесса, так как копируются только модифицируемые страницы. Свободные страницы распределяются из списка страниц, инициализированных нулями.
Использование при вводе-выводе файлов, отображаемых в память, позволяет рассматривать файловый ввод-вывод как обычное обращение к памяти путем отображения блока на диске в страницу памяти.
Первоначально файл читается с использованием запроса страниц по требованию. Часть файла размером с одну страницу читается из файла в физическую страницу (фрейм). Последующие чтения из файла и записи в файл трактуются как обычные обращения к памяти. Это упрощает доступ к файлу, по сравнению с системными вызовами read() и write(). Это позволяет также нескольким процессам отображать в память один и тот же файл, по тому же принципу, как они совместно используют какие-либо страницы.
На рис. 18.5 иллюстрируется концепция файла, отображаемого в память.
 Рис.
18.5. Файлы, отображаемые в память.
Рис.
18.5. Файлы, отображаемые в память.
Процессы A и B совместно используют файл, причем каждому блоку файла соответствует страница в памяти. Эти страницы имеют одним и те же номера в таблицах страниц виртуальной памяти процессов. Страницы, присутствующие в памяти, фактически являются частями файла, обрабатываемого при вводе-выводе, благодаря этому, гораздо быстрее, чем обычный файл. По окончании обмена, при закрытии файла, система записывает все его измененные части на диск.
Подобный механизм имеется в большинстве операционных систем. Например, в системе Solaris он реализуется командой и системным вызовом mmap (memory map).