

3 Виды правил принятия решений
− параллельные – проведение ряда тестов над всей совокупностью выявленных данных об объекте и принятие решения на основе их результатов;
− последовательные – проведение последовательности тестов над подмножествами выявленных данных; выбор очередного теста определяется результатами предыдущих тестов.
3.1 Параллельное распознавание
Систему с параллельным способом принятия решения можно проиллюстрировать следующим образом (рис. 6):
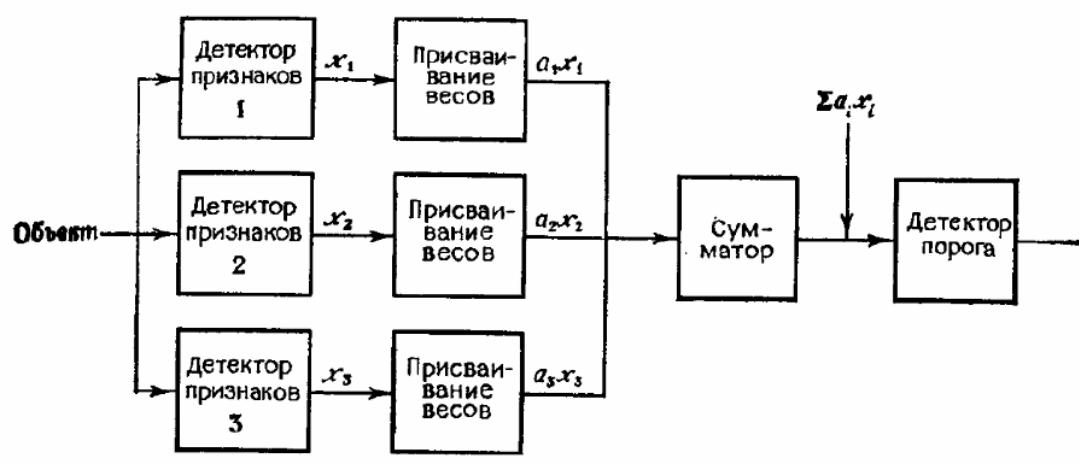
Рисунок 6 – Схема действия параллельной процедуры распознавания
Для выполнения распознавания система производит ряд тестов над всеми компонентами xi, i = 1,..., N описания входного объекта одновременно. Решающая функция в этом случае представляется функцией не более, чем N переменных g (x1 ,..., xN).
Система может быть организована в виде множества параллельных функций
F = { f j (x1, ..., xN)}, j = 1,..., m,
каждая их которых производит оценку принадлежности объекта к соответствующему ей классу. В таком случае решающая функция принимает решение на основе максимального полученного значения – g = max(f j).
Параллельная процедура является достаточно надёжной и требует для распознавания постоянного времени, равного времени выполнения самой продолжительной из процедур распознавания. Однако, она не обладает гибкостью, свойственной последовательным процедурам.
Главным недостатком параллельного подхода является требование к подаче полного описания распознаваемого образа на вход системы. В случаях, когда полный образ состоит из нескольких подобразов, и требуется распознать каждый из подобразов в отдельности, для использования параллельного правила распознавания потребуется предварительное выделение каждого подобраза из общей картины. Такая ситуация характерна, например, для распознавания изображения текста системой, обученной к распознаванию отдельных символов. В некоторых случаях предварительное выделение подобразов является выполнимой задачей, как, например, выделение символов в машинопечатном тексте. В других случаях выделение подобраза по сложности равносильно его распознаванию. Это характерно для образов, в которых подобразы не имеют чётких и формально определимых границ. Как пример — рукописный (скорописный) текст.
Параллельная процедура распознавания, как правило, реализуется методами, использующими Евклидово пространство описаний, а так же некоторыми признаковыми методами. Структурные же методы чаще всего реализуют последовательные правила, речь о которых пойдёт в следующем разделе.
3.2 Последовательное распознавание
Последовательный способ распознавания, как и параллельный, предусматривает ряд тестов над признаками распознаваемого объекта (рис. 7).
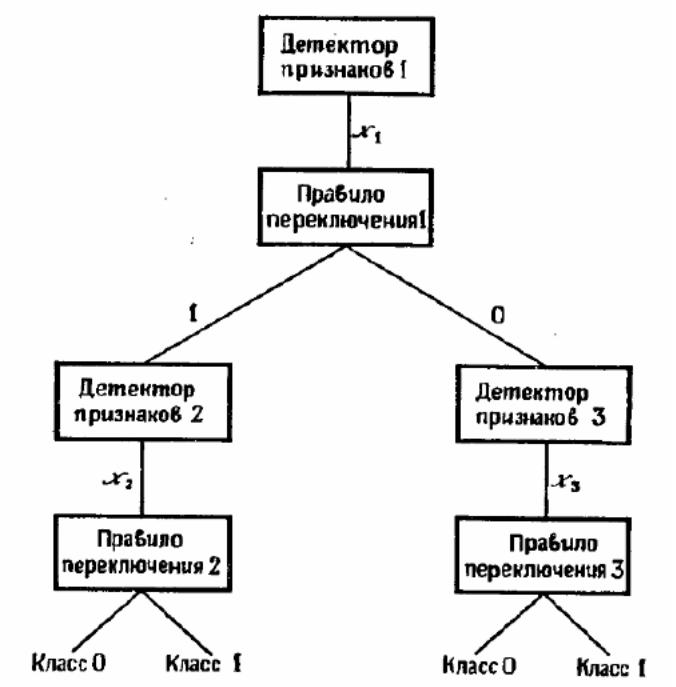
Рисунок 7 – Схема действия последовательной процедуры распознавания
Однако, выполняются они не одновременно, а последовательно, причём порядок их выполнения может зависеть (и чаще всего зависит) от получаемых результатов.
На каждом шаге распознавания выполняется очередной тест одним из детектирующих блоков. По результатам его работы управление может перейти к одному из нескольких возможных последующих блоков. Кроме того, выполнение очередного теста может быть параметризовано некоторым образом, зависящим от результатов предыдущих тестов. Таким образом, от характеристик образа, выявленных на ранних этапах анализа, зависит набор проверок, выполняемых на более поздних этапах. Можно говорить, что последовательная процедура распознавания определяется деревом проверок и решений, по одной из ветви которой в каждый момент движется процесс распознавания.
Пример.
Рассмотрим, к примеру, систему считывания двумерного штрих-кода [15]. Устройство-считыватель осуществляет сканирование изображения штрих-кода. Прежде всего, оно осуществляет поиск опорных элементов — ориентиров. Разные типы штрих-кодов используют различные ориентировочные элементы. В зависимости от типа найденного ориентира выбирается дальнейший алгоритм анализа изображения. В соответствии с выбранным алгоритмом и по полученным параметрам ориентиров осуществляется определение границ штрих-кода, угла его поворота относительно устройства сканирования, а также собственно расшифровка закодированных данных.