

Приклад алгоритму Apriori
Огляд
Весь сенс алгоритму (та інтелектуального аналізу даних, в цілому) вилучення корисної інформації з великих обсягів даних. Наприклад, інформація про те, що клієнт, який купляє клавіатуру також має тенденцію до купівлі мишки в той же час отримуютчи з асоціативних правил нижче:
Підтримка: Відсоток завдань відповідних операцій даних, для яких модель вірна.
Підтримка
(Клавіатура -> Мишка) =![]()
Довіри: міра впевненості та надійності, пов'язана з кожною виявленою картинкою.
Впевненість
(Клавіатура -> Мишка) =
Алгоритм прагне знайти правила, які задовольняють як мінімальний поріг підтримки і мінімальний поріг довіри (строгі правила).
 Item(Товар):
стаття в кошику.
Item(Товар):
стаття в кошику.
Itemset(Група товарів): група товарів, придбаних разом в одній транзакції.
Як працює Apriori
1.Шукає всі набори , які часто зустрічаються :
Отримати ці набори:

Предмети виникнення яких у базі даних більше або дорівнює пороговому min.support.
Отримати всі набори , які часто зустрічаються:
Генерація кандидатів від частих предметів.
Підсумок результатів, щоб знайти набори , які часто зустрічаються.
2.Генерують сильні асоціативні правила з часто зустрічаються наборів
Правила, які задовольняють min.support і min.confidence поріг.
Дизайн високого рівня
Згенерувати
асоціативне правило
Згенерувати Set
= NULL
Отримати
всі набори , які часто зустрічаються
Отримати
всі набори , які часто зустрічаються
Початок
Генерація
кандидатських наборів






Ні
Так
Приклад
База даних складається з п'яти операцій. Нехай min sup = 50% and min con f = 80%.
База Даних
Т-ID |
Продукт |
100 |
ACD |
200 |
BCE |
300 |
ABCE |
400 |
BE |
Рішення
Крок 1:Знайти всі набори , які часто зустрічаються
1-Група продуктів |
Підтримка |
{A} |
2 |
{B} |
3 |
{C} |
3 |
{E} |
3 |
Т-ID |
Продукт |
100 |
ACD |
200 |
BCE |
300 |
L1 |
400 |
BE |

Зєднання



2-Група продуктів |
Підтримка |
{A C} |
2 |
{B C} |
2 |
{B E} |
3 |
{C E} |
2 |
Зєднання
Витягти
L2
С2
Продукт |
Підтримка |
{A B} |
1 |
{A C} |
2 |
{A E} |
|
{B C} |
2 |
{B E} |
3 |
{C E} |
2 |
 1
1
L3\3
С3№3
Група продуктів |
|
 {B
C E}
{B
C E}3-Група продуктів |
Підтримка |
{B C E} |
2 |
Витягти
Всі набори , які часто зустрічаються
{ A } { B } { C } { E } { A C } { B C } { C E } { B C E } |
Крок 2: Створення сильних асоціативних правил з наборами , які часто зустрічаються
Правило |
Підтримка |
Підтримка |
Впевненість |
{A}{C} |
2 |
2 |
100 |
{B}{C} |
2 |
3 |
66.66666667 |
{B}{E} |
3 |
3 |
100 |
{C}{E} |
2 |
3 |
66.66666667 |
{B}{C E} |
2 |
3 |
66.66666667 |
{C}{B E} |
2 |
3 |
66.66666667 |
{E}{B C} |
2 |
3 |
66.66666667 |
{C}{A} |
2 |
3 |
66.66666667 |
{C}{B} |
3 |
3 |
100 |
{E}{B} |
2 |
3 |
66.66666667 |
{E}{C} |
2 |
2 |
100 |
{}{} |
2 |
3 |
66.66666667 |
{}{} |
2 |
2 |
100 |
|
|
|
|
Решітка
Закрита Група: підтримка всіх батьків не рівні підтримкою набору елементів.
Максимальний набір елементів: всі батьки, яких набір елементів повинен бути рідкісним.
Майте на увазі:
Рідкісні
Закриті
Макс.
Набори , які часто зустрічаються
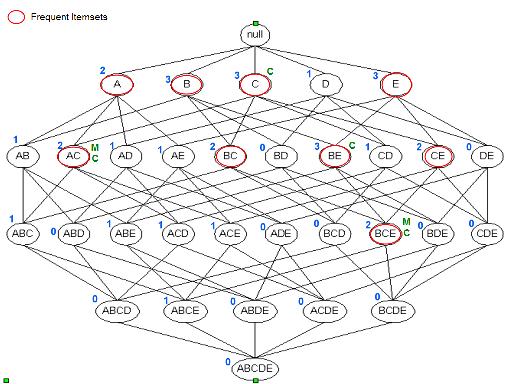
Набір елементів {C} закрито, як підтримка батьків (суперсетами) {AC}: 2, {BC}: 2, {} CD: 1,} {CE: 2 не дорівнює підтримці {C}: 3.
І те ж саме для {C}, {B} E & {B C E}.
Набір елементів {AC} максимальна, як і всі батьки (суперсетами) {ABC}, {ACD}, {} ACE бувають рідко.
І те ж саме для {B C E}.
Підсумки:
1.)Задачею пошуку асоціативних правил, являється визначення часто зустрічаючих наборів обєктів в великій кількості наборів
2.)Секвенціальний аналіз заключається в пошуку послідовностей, які часто зустрічаються. Основною відмінністю задачі секвенціального аналізу від пошуку асоціативних правил являється встановлення відношення порядку між обєктами.
3.)Наявність ієрархії в обєктах і її використання в задачі пошуку асоціативних правил позволяє виконувати більш гнучкий аналіз і діставати додаткові знання.
4.)Результати рішення задачі представляються у вигляді асоціативних правил умовна і заключна частина яких містить набори обєктів.
5.)Основними характеристиками асоціативних правил являються підтримка , достовірність і покращення.
6.)Підтримка(support) показує, який відсоток транзакцій підтримує дане правило.
7.)Достовірність показує, яка ймовірність того, що з наявності транзакції набору умовна частина правил слідує наявністі в ній заключної частини.
8.)Поліпшення показує, чи корисніше правило випадкового вгадування.
9.)Задача пошуку асоціативних правил розвязується у два етапи. На першомі етапі виконується всіх часто зустрічаючих наборів обєктів. На другому етапі із найдених наборів обєктів, часто зустрічалися генеруються асоціативні правила.
10.)Алгоритм Apriori використовує одне з властивостей підтримки, говоряча: підтимка будь-якого набору обєктів не може перевищувати мінімальної підтримки із його підмножин.
Список використаної літератури:
1.) R. Agrawal, T. Imielinski, A. Swami. 1993. Mining Associations between Sets of Items in Massive Databases. In Proc. of the 1993 ACM-SIGMOD Int’l Conf. on Management of Data, 207-216.
2. )R. Agrawal, R. Srikant. "Fast Discovery of Association Rules", In Proc. of the 20th International Conference onVLDB, Santiago, Chile, September 1994.
3.)http://www/codeproject.com/Articles/70371/Apriori-Algorithm