

5. Декластеризация
Большая часть пространственно распределенных данных, которые анализируются в геостатистике, имеет кластерную структуру. Кластер образуется, если в одной области было проведено значительно большее число измерений, чем в другой. В этом случае могут возникнуть существенные искажения при вычислении, например среднего значения. Это влечет невозможность получить репрезентативную гистограмму распределения. Пусть, например, в области высоких значений измеряемой величины, находится вдвое больше точек, чем в области низких значений. Если при оценке среднего и других статистических параметров все значения будут иметь одинаковый вес, то область высоких значений будет слишком сильно влиять на такую оценку. В этом случае точки из зоны с большими значениями нужно было бы учитывать с весом, вдвое меньшим, чем все остальные. Проблема вычисления статистического веса каждой точки в параметрах распределения решается путем проведения процедуры декластеризации (declustering) данных.
Декластеризация не требуется, если измерения были выполнены на регулярной сетке. В этом случае наилучшее описание распределения получится при работе с равными весами. Тем не мене, во многих случаях невозможно получить данные на равномерной сетке.
При анализе измерений, проведенных на нерегулярной сетке, предполагается существование такого набора весов, при котором может быть получено репрезентативное распределение данных. Здравый смысл подсказывает, что данные из области с большей плотностью измерений нужно брать с меньшим весом (для уменьшения их влияния на распределение в целом), чем данные из области с меньшей плотностью измерений. Для вычисления весов могут быть использованы разные подходы: метод ячейковой декластеризации, метод ячеек Дирихле (полигонов Вороного, рис. 4), кригинг.
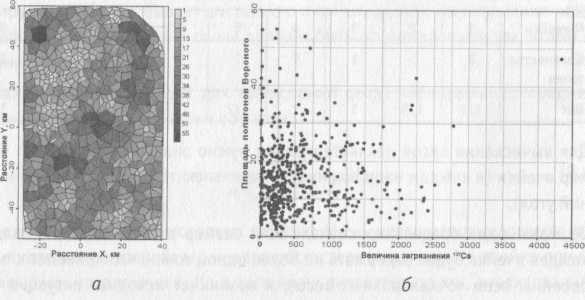
Рис. 4. Площади полигонов Вороного (а), корреляция площади полигона и величины пространственной переменной 137Cs (6)
Метод ячейковой декластеризации (cell-dedustering) был предложен в [Journel 1983]. Его идея заключается в разбиении рассматриваемой области на подобласти кластеризованных данных и в определении равных весов для всех точек внутри каждой подобласти в соответствии с их количеством.
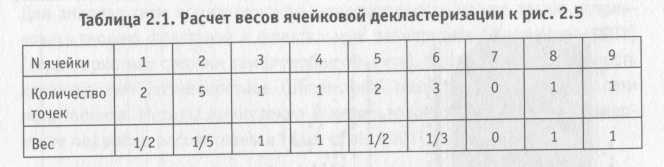
Так, если в ячейку ак попало пк точек, то каждое измерение будет учтено с весом 1/пк. Область ак пространства обычно имеет размерность 3 (время может стать четвертым измерением). Для ячейки, не содержащей опытных точек, веса не рассчитываются, т. е. область декластеризованных данных состоит из ячеек, содержащих по крайней мере по одному измерению. Это ограничивает влияние граничных данных весом 1,0. На рис. 5 показан пример разбиения области на ячейки. Расчет соответствующих весовых коэффициентов приведен в табл. 1. После вычисления весов в такой форме они должны быть отнормированы так, чтобы их сумма была равна 1.

Рис. 5. Пример расчета весов ячейковой декластеризации
Таб. 1. Расчёт весов ячейковой декластеризации к рис. 5
Для вычисления весов декластеризации нужно знать два параметра: размер ячейки (в каждом направлении) и начальную точку сетки (левый нижний угол).
Возможны два предельных случая: если размер ячейки слишком мал, то каждая ячейка будет содержать не более одной точки, что приведет к присвоению всем точкам равных весов, и возникнет исходная ситуация недекластеризованных данных. В противоположном случае, когда размер ячейки слишком велик, все данные попадут в одну единственную ячейку и результат будет тот же — все точки получат равные веса.
Метод выбора размера ячейки зависит от типа кластеризации. Если данные кластеризованы случайным образом (есть области скопления точек, никак не связанных с их значениями), размер ячейки выбирается так, чтобы в областях с низкой плотностью измерений на одну ячейку приходилось приблизительно по одной точке измерений. Если же известно, что есть области высоких или низких значений с большим количеством измерений, то размер ячейки может быть выбран так, чтобы оптимально получить максимальное или минимальное взвешенное среднее. При декластеризации областей высоких или низких значений нужно пробовать наборы ячеек разного размера. В этом случае строится график зависимости взвешенного среднего значения от размера ячейки (Рис. 7) и в соответствии с ним выбирается подходящий размер [Deutsch, 1989].
Ячейки не обязательно должны быть квадратными. С помощью параметра анизотропии (отношение размеров ячейки) можно построить описанные выше зависимости и на их основе также выбрать параметры ячейки, соответствующие минимуму или максимуму взвешенного среднего. Результаты можно представить, например, в виде контурной карты с размерами ячеек в каждом из направлений в качестве координат.
Если при фиксированном размере ячейки перемещать начало декластеризующей сетки, то веса декластеризации могут существенно меняться. Чтобы исключить влияние этого фактора, проводят несколько шагов декластеризации, вводя систематическое смещение начала сетки. Веса, полученные после каждого шага смещения, нормируются на единицу, и результаты суммируются. Обычно бывает достаточно пяти смещений. По окончании манипуляций веса всех точек снова должны быть отнормированы так, чтобы их сумма была равна 1.
Таким образом, формулу для вычисления декластеризованного среднего можно записать следующим образом:
 (2.6.)
(2.6.)
где,
п — общее число исходных данных; Nof — число использующихся при вычислении смещений; wik — веса декластеризации для к-й ячейки при i-м смещении начала ячеек. Но в алгоритме декластеризации, реализованном в популярном пакете геостатистических программ GSLib [Deutsch, Journel, 1998], используется нормализация весов не к 1, а к числу измерений. При этом формула для вычисления декластеризованного среднего (2.6) несколько изменяется:
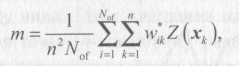 (2.7)
(2.7)
где
wik
— веса декластеризации, связанные с
весами из (2.6) соотношением wik=nwik.

Рис. 6. Веса ячейковой декластеризации для декластеризации кластеров низких значений (а) и кластеров высоких значений (б)
Рис. 7. Зависимость декластеризованного среднего значения от размера ячейки.
Метод ячейковой декластеризации.
Рис. 8. Гистограммы декластеризованных и исходных данных 137Cs