

Первая нормальная форма
Первая нормальная форма:
запрещает повторяющиеся столбцы (содержащие одинаковую по смыслу информацию)
запрещает множественные столбцы (содержащие значения типа списка и т.п.)
требует определить первичный ключ для таблицы, то есть тот столбец или комбинацию столбцов, которые однозначно определяют каждую строку
Вторая нормальная форма
Вторая нормальная форма требует, чтобы неключевые столбцы таблиц зависили от первичного ключа в целом, но не от его части. Маленькая ремарочка: если таблица находится в первой нормальной форме и первичный ключ у нее состоит из одного столбца, то она автоматически находится и во второй нормальной форме.
Третья нормальная форма
Чтобы таблица находилась в третьей нормальной форме, необходимо, чтобы неключевые столбцы в ней не зависели от других неключевых столбцов, а зависели только от первичного ключа. Самая распространенная ситуация в данном контексте - это расчетные столбцы, значения которых можно получить путем каких-либо манипуляций с другими столбцами таблицы. Для приведения таблицы в третью нормальную форму такие столбцы из таблиц надо удалить.
Нормальная форма Бойса-Кодда
Нормальная форма Бойса-Кодда требует, чтобы в таблице был только один потенциальный первичный ключ. Чаще всего у таблиц, находящихся в третьей нормальной форме, так и бывает, но не всегда. Если обнаружился второй столбец (комбинация столбцов), позволяющий однозначно идентифицировать строку, то для приведения к нормальной форме Бойса-Кодда такие данные надо вынести в отдельную таблицу.
Четвертая нормальная форма
Для приведения таблицы, находящейся в нормальной форме Бойса-Кодда, к четвертой нормальной форме необходимо устранить имеющиеся в ней многозначные зависимости. То есть обеспечить, чтобы вставка / удаление любой строки таблицы не требовала бы вставки / удаления / модификации других строк этой же таблицы.
Пятая нормальная форма
Таблицу, находящуюся в четвертой нормальной форме и, казалось бы, уже нормализованную до предела, в некоторых случаях еще можно бывает разбить на три или более (но не на две!) таблиц, соединив которые, мы получим исходную таблицу. Получившиеся в результате такой, как правило, весьма искусственной, декомпозиции таблицы и называют находящимися в пятой нормальная форме. Формальное определение пятой нормальной формы таково: это форма, в которой устранены зависимости соединения. В большинстве случаев практической пользы от нормализации таблиц до пятой нормальной формы не наблюдается.
Такая вот теория... Разработаны специальные формальные математические методы нормализации таблиц реляционных баз данных. На практике же толковый проектировщик баз данных, детально познакомившись с предметной областью, как правило, достаточно быстро набросает структуру, в которой большинство таблиц находятся в четвертой нормальной форме:).
Краткие итоги. Зачем нужна нормализация.
Главное, чего мы добьемся, проведя нормализацию базы данных - это устранение (или, по крайней мере, серьезное сокращение) избыточности, дублирования данных. Как следствие, значительно сокращается вероятность появления противоречивых данных, облегчается администрирование базы и обновление информации в ней, сокращается объем дискового пространства.
Но не все так бело и пушисто. Зачастую, чтобы извлечь информацию из нормализованной базы данных, приходится конструировать очень сложные запросы, которые к тому же, бывает, работают довольно медленно - из-за, главным образом, большого количества соединений таблиц. Поэтому, чтобы увеличить скорость выборки данных и упростить программирование запросов, нередко приходится идти на выборочную денормализацию базы. Что это такое и как это делается - поговорим в следующей статье.
13. Целостность БД.
Термин «целостность» используется для описания точности и корректности (или непротиворечивости) данных, хранящихся в базе данных.
Если термин «безопасность» означает защиту данных от несанкционированного доступа, то «целостность» означает защиту от санкционированного доступа, т.е. целостность возникает тогда, когда у пользователя имеются права работы с базой данных, но при этом он работает корректно (не вводит каких-то данных, которые приводят базу данных в неправильное положение).
Целостность реляционных данных, стратегии поддержания ссылочной целостности
Целостность реляционных данных фиксирует два базовых требования целостности:
- требование целостности сущности
- требование целостности внешних ключей
Целостность сущности
У любой переменной отношения должен существовать первичный ключ, и никакое значение первичного ключа в кортежах значения-отношения переменной отношения не должно содержать неопределенных значений (NULL).
Неопределенное значение не принадлежит никакому типу данных и может присутствовать среди значений любого атрибута, определенного на любом типе данных (если это явно не запрещено при определении атрибута).
Таким образом, требование означает, что первичный ключ должен полностью идентифицировать каждую сущность, а поэтому в составе любого значения первичного ключа не допускается наличие неопределенных значений.
Правило целостности внешних ключей
Внешние ключи не должны быть несогласованными, т.е. для каждого значения внешнего ключа должно существовать соответствующее значение первичного ключа в родительском отношении.
Ссылочная целостность может нарушиться в результате операций, изменяющих состояние базы данных. Таких операций три:
- вставка
- обновление
- удаление кортежей в отношениях.
Т.к. в определении ссылочной целостности участвуют два отношения - родительское и дочернее, а в каждом из них возможны три операции, то нужно рассмотреть шесть различных вариантов.
Для родительского отношения:
1. Вставка кортежа в родительском отношении. При вставке кортежа в родительское отношение возникает новое значение потенциального ключа. Т.к. допустимо существование кортежей в родительском отношении, на которые нет ссылок из дочернего отношения, то вставка кортежей в родительское отношение не нарушает ссылочной целостности.
2. Обновление кортежа в родительском отношении. При обновлении кортежа в родительском отношении может измениться значение потенциального ключа. Если есть кортежи в дочернем отношении, ссылающиеся на обновляемый кортеж, то значения их внешних ключей станут некорректными. Обновление кортежа в родительском отношении может привести к нарушению ссылочной целостности, если это обновление затрагивает значение потенциального ключа.
3. Удаление кортежа в родительском отношении. При удалении кортежа в родительском отношении удаляется значение потенциального ключа. Если есть кортежи в дочернем отношении, ссылающиеся на удаляемый кортеж, то значения их внешних ключей станут некорректными. Удаление кортежей в родительском отношении может привести к нарушению ссылочной целостности.
Для дочернего отношения:
1. Вставка кортежа в дочернее отношение. Нельзя вставить кортеж в дочернее отношение, если вставляемое значение внешнего ключа некорректно. Вставка кортежа в дочернее отношение привести к нарушению ссылочной целостности.
2. Обновление кортежа в дочернем отношении. При обновлении кортежа в дочернем отношении можно попытаться некорректно изменить значение внешнего ключа. Обновление кортежа в дочернем отношении может привести к нарушению ссылочной целостности.
3. Удаление кортежа в дочернем отношении. При удалении кортежа в дочернем отношении ссылочная целостность не нарушается.
Таким образом, ссылочная целостность в принципе может быть нарушена при выполнении одной из четырех операций:
1. Обновление кортежа в родительском отношении.
2. Удаление кортежа в родительском отношении.
3. Вставка кортежа в дочернее отношение.
4. Обновление кортежа в дочернем отношении.
Существуют две основные стратегии поддержания ссылочной целостности:
RESTRICT (ОГРАНИЧИТЬ) - не разрешать выполнение операции, приводящей к нарушению ссылочной целостности.
CASCADE (КАСКАДИРОВАТЬ) - разрешить выполнение требуемой операции, но внести при этом необходимые поправки в других отношениях так, чтобы не допустить нарушения ссылочной целостности и сохранить все имеющиеся связи. Изменение начинается в родительском отношении и каскадно выполняется в дочернем отношении.
Эти стратегии являются стандартными и присутствуют во всех СУБД, в которых имеется поддержка ссылочной целостности.
Дополнительные стратегии:
SET NULL (УСТАНОВИТЬ В NULL) - разрешить выполнение требуемой операции, но все возникающие некорректные значения внешних ключей изменять на null-значения.
SET DEFAULT (УСТАНОВИТЬ ПО УМОЛЧАНИЮ) - разрешить выполнение требуемой операции, но все возникающие некорректные значения внешних ключей изменять на некоторое значение, принятое по умолчанию.
IGNORE (ИГНОРИРОВАТЬ) - выполнять операции, не обращая внимания на нарушения ссылочной целостности.
14. Индексирование в БД.
Структура хранения на основе индексирования предполагает использовать двух хранимых файлов. 1. Файл таблицы с данными (например, поставщиков деталей), его условно называют последовательный файл. 2. Файл с индексами (например, данные о городах проживания поставщиков).
В файле с индексами названия городов всегда упорядочены по алфавиту. И фактически есть риды (RID) соответствующие записи файла поставщиков.
Например: Представим себе файл с данными, т.е таблица с поставщиками, там есть определенное количество записей. Риды S1,S2 и так далее.
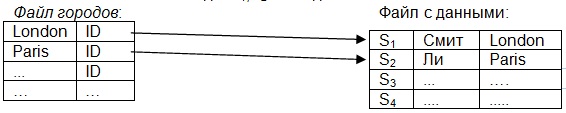
В индексном файле записи упорядочены по алфавиту, а в файле с данными записи располагаются как есть.Они могут быть упорядоченны не по файлу городов, а по номеру или фамилии поставщика. Но нам допустим надо по городу. Файл городов в этом случае называется индексным файлом, состоящим из двух колонок. Ну а файл таблица (в физическом смысле файл, или в логическом смысле файл, как это в SQL серверах) называется индексированным .
Фактически для того чтобы найти сведения быстро в таблице, первоначально считывается индексный файл, он поскольку всегда состоит из двух колонок, то он может быть относительно малым (а таблица может быть достаточно широкой). Загружается в память (индексный файл). Так как записи упорядочены по алфавиту, то быстро находиться по алфавиту методом двоичного поиска( он быстрый). Когда у нас данные индексированы от маленького значения до большого, фактически первый раз ищется половина, смотрим попали или не попали. Если не попали, то следующую пополам, если не попали опять следующую и так далее. Всего надо 10 шагов чтобы в файле из 1024 записей в порядке возрастания, или убывания найти нужную запись. Если бы искали по порядку то в худшем случае оказалось бы 1024 поиска. Скорость поиска по индексному файлу очень велика, и чем больше записей тем быстрее, вместо последовательного поиска по всем записям нужной записи.
Иногда индексный файл называют инвертированным списком. Очень удобны такие инвертированные списки когда они делаются по ключевому полю, по Primary Key. Очень эффективны и быстро работают. В принципе могут быть две стратегии поиска поставщиков ,например, из города London. В файле поставщиков найти все записи, названия городов которых являются London.Или сначала в файле городов найти все значения с London, а затем по указателям найти записи. Во втором случае получается гораздо быстрее. Правда есть время, затрачиваемое на считывание файла городов. Если эти файлы соизмеримы то выигрыша нет, для маленьких табличек до 300 записей смысла индексы делать нет, потому что таблица с малым числом строк всегда загружается в виде страницы в память и что по индексу искать, что искать по памяти одинаково.
Если доля поставщиков из London очень мала, то такой файл эффективен (индексированный файл), если их доля велика то этот файл будет часто включаться, тогда выйгрыш от использования индексного файла начинает теряться. Индексы всегда хороши когда число искомых записей не превышает 10-15 процентов. Когда число искомых записей от 20% и выше то можно искать по прямому поиску.
Все записи про London идут друг за другом, и если нашлись несколько записей, идущих подряд, то ясно их положение, здесь они быстро считываются, и эти идентификаторы указывают на нужные записи. Если бы мы не упорядочивали, то London может встречаться где угодно и поиск будет долгим. Нужно будет просматривать всю таблицу.
Таким образом индексы позволяют избежать полного просмотра таблиц, который снижает существенно производительность. Снижает производительность не только конкретного клиента, который смотрит и перебирает всю таблицу, но и других, т.к сеть перегружается, буфер у сервера тоже перегружается, т.е тратятся у системы большие ресурсы и другие клиенты не могут их использовать. Сервер часто считывает данные, запись за записью диск только работает на одного человека.
Недостатки индексирования Недостаток использования индексов заключается в том, что если их много, то после обновления данных в таблицах(просто обновления, удаления, добавления записей) индексы должны перестраиваться. Чем больше индексов, тем больше перестроек. В руководстве SQL сервер говориться так : “на одну таблицу не более 16 идексов”. После 16 быстродействие не гарантируется, т.е до 16 индексов переиндексацию сервер обеспечивает относительно быстро, а дальше производительность сильно падает.
Если индексирование сделано по первичному ключу. То индекс называется первичным. В противном случае он называется вторичным, если по всем другим колонкам, например, по городам, по каким нибудь рейтингам, и т.д. Если индекс сделан по первичному ключу, то он еще в дополнение называется уникальным, потому что повторяющихся значений по первичному ключу в принципе быть не может. В файле городов он не может быть уникальным, т.к городов проживания может быть много (у многих клиентов могут быть одинаковые города).
Индексы могут использоваться для двух целей: 1) для последовательного доступа. Например, найти всех поставщиков из города London. 2) Для прямого доступа. Когда надо найти что-то конкретное.
15. Реляционная алгебра.
Реляционная алгебра — замкнутая система операций над отношениями в реляционной модели данных. Операции реляционной алгебры также называют реляционными операциями.
Первоначальный набор из 8 операций был предложен Э. Коддом в 1970-е годы и включал как операции, которые до сих пор используются (проекция, соединение и т.д.), так и операции, которые не вошли в употребление (например, деление отношений).
Выборка .
θ — оператор сравнения из множества {<; ≤; =; ≥; >}
Проекция.
Результатом такой выборки будет набор последовательностей значений отношения R, в котором будут присутствовать только поля, перечисленные в списке a1,…,an с естественным уничтожением потенциально возникающих кортежей-дубликатов[4].
Объединение.
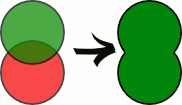
Пересечение.

Разность.
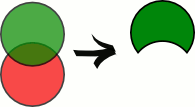
Произведение.
Мульфильмы
Код_мульта |
Название_мульта |
0 |
The Simpsons |
1 |
Family Guy |
2 |
Duck Tales |
Каналы
Код_канала |
Название_канала |
0 |
СТС |
1 |
2х2 |
Результат произведения:
Код_мульта |
Название_мульта |
Код_канала |
Название_канала |
0 |
The Simpsons |
0 |
СТС |
0 |
The Simpsons |
1 |
2х2 |
1 |
Family Guy |
0 |
СТС |
1 |
Family Guy |
1 |
2х2 |
2 |
Duck Tales |
0 |
СТС |
2 |
Duck Tales |
1 |
2х2 |
Деление – процесс обратный умножению (разделение таблиц)
Соединение.
Мульфильмы
Код_мульта |
Название_мульта |
Название_канала |
0 |
The Simpsons |
2х2 |
1 |
Family Guy |
2х2 |
2 |
Duck Tales |
RenTV |
Каналы
Код_канала |
Частота |
RenTV |
3,1415 |
2х2 |
783,25 |
Соединим их с выборкой σНазвание_канала = Код_канала(Произведение) Первый этап, произведение:
Код_мульта |
Название_мульта |
Название_канала |
Код_канала |
Частота |
0 |
The Simpsons |
2х2 |
RenTV |
3,1415 |
0 |
The Simpsons |
2х2 |
2х2 |
783,25 |
1 |
Family Guy |
2х2 |
RenTV |
3,1415 |
1 |
Family Guy |
2х2 |
2х2 |
783,25 |
2 |
Duck Tales |
RenTV |
RenTV |
3,1415 |
2 |
Duck Tales |
RenTV |
2х2 |
783,25 |
Второй этап, выборка σНазвание_канала = Код_канала(Произведение):
Код_мульта |
Название_мульта |
Название_канала |
Код_канала |
Частота |
0 |
The Simpsons |
2х2 |
2х2 |
783,25 |
1 |
Family Guy |
2х2 |
2х2 |
783,25 |
2 |
Duck Tales |
RenTV |
RenTV |
3,1415 |
16. Реляционное исчисление
Реляционное исчисление – декларативный теоретический язык запросов, реализованный на основе исчисления предикатов первого порядка (высказываний в виде функции), которым должны удовлетворять искомые кортежи или домены отношений.
Запрос к БД, выполненный с использованием реляционного исчисления, содержит описание желаемого результата, для которого может существовать несколько способов его вычисления, представленных выражениями реляционной алгебры или непосредственно командами СУБД. Преимуществом реляционного исчисления перед реляционной алгеброй можно считать то, что пользователю не требуется самому строить алгоритм выполнения запроса, Программа СУБД (при достаточной ее интеллектуальности) сама строит эффективный алгоритм.
Существует два варианта исчислений: исчисление, кортежей и исчисление, доменов. В первом случае для описания отношений используются переменные, допустимыми значениями которых являются кортежи отношения, а во втором случае — элементы домена.
Домен - это семантическое понятие. Домен можно рассматривать как подмножество значений некоторого типа данных имеющих определенный смысл. Домен характеризуется следующими свойствами:
Домен имеет уникальное имя (в пределах базы данных).
Домен определен на некотором простом типе данных или на другом домене.
Домен может иметь некоторое логическое условие, позволяющее описать подмножество данных, допустимых для данного домена.
Домен несет определенную смысловую нагрузку.
Кортеж, отношение
Кортеж, соответствующий данной схеме отношения, - это множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. "Значение" является допустимым значением домена данного атрибута (или типа данных, если понятие домена не поддерживается). Попросту говоря, кортеж - это набор именованных значений заданного типа.
Отношение - это множество кортежей, соответствующих одной схеме отношения. На самом деле, понятие схемы отношения ближе всего к понятию структурного типа данных в языках программирования.
3.9. Реляционное исчисление, основанное на кортежах (исчисление кортежей)
В исчислении кортежей, как и в процедурных языках программирования, сначала нужно описать используемые переменные, а затем записать выражения запроса к данным.
Описательную часть исчисления можно представить в виде: RANGE OF <переменная> IS <список>.
Конструкция RANGE указывает идентификатор переменной кортежа <переменная> и область ее допустимых значений - <список> - последователь<ность одного или более элементов: x1, ..., xn, каждый из которых является либо отношением, либо выражением над отношением (порядок записи выражений описывается далее). При этом в любой момент <переменная> принимает в качестве значения только один из кортежей <списка> отношений.
Схемы отношений списка должны быть эквивалентными. Область допустимых значений <переменной> образуется путем объеди<нения значений всех элементов списка.
Пример: RANGE OF Студент IS Очный_студент, Заочный_студент
Область определения переменной Студент включает в себя все значения из отноше<ния, которое является объединением отношений Очный_студент и Заочный_студент.
Выражением реляционного исчисления кортежей называется конструкция вида <целевой_список > WHERE <WFF>
Значением выражения является отношение, тело (множество кортежей) которого должно удовлетворять WFF (well formulated formula — правильно построенная формула), а схема (набор атрибутов и их имена) определяется целевым списком. Целевой список по существу определяет операцию проекции, а формула WFF - селекцию кортежей.
В паре <переменная>.<атрибут> первая составляющая служит для указания переменной кортежа (определенной конструкцией RANGE), а вторая — для определения атрибута отношения, на котором изменяется переменная кортежа. Необязательная часть «AS <атрибут>» используется для переименования атрибута целевого отношения. Если она отсутствует, то имя атрибута целевого отношения наследуется от соответствующего имени атрибута исходного отношения.
Употребление в качестве элемента целевого отношения имени переменной равносильно перечислению в списке всех атрибутов соответствующего отношения.
WFF служат для выражения условий, накладываемых на кортежные переменные. Основой WFF являются простые сравнения, представляющие собой операции сравнения скалярных значений (значений атрибутов переменных или констант). Например, конструкция "СТУДЕНТ.НОМЕР_ЗАЧЕТНОЙ_КНИЖКИ = 625432" является простым сравнением. По определению, простое сравнение является WFF, а WFF, заключенная в круглые скобки, является простым сравнением.
Более сложные варианты WFF строятся с помощью логических связок NOT, AND, OR и IF ... THEN.
Так, если <формула> - WFF, а <сравнение> - простое сравнение, то NOT <формула> <сравнение> AND <формула> <сравнение> OR <формула> IF <сравнение> THEN <формула> являются WFF.
Допускается построение WFF с помощью кванторов. Если <формула> - это WFF, в которой участвует <переменная>, то конструкции EXISTS <переменная> (<формула>) FORALL <переменная> (<формула>) являются WFF.
В первом случае WFF означает: "Существует по крайней мере одно такое значение <переменной>, что вычисление <формулы> дает значение ИСТИНА".
Во втором случае WFF означает: "Для всех значений переменной <переменной> вычисление <формулы> дает значение ИСТИНА".
Переменные, входящие в WFF, могут быть свободными или связанными. Все переменные, входящие в WFF, при построении которой не использовались кванторы, являются свободными. Фактически, это означает, что если для какого-то набора значений свободных кортежных переменных при вычислении WFF получено значение ИСТИНА, то эти значения кортежных переменных могут входить в результирующее отношение.
Если же имя переменной использовано сразу после квантора при построении WFF вида EXISTS <переменная> (<формула>) или FORALL <переменная> (<формула>), то в этой WFF и во всех WFF, построенных с ее участием, <переменная> - это связанная переменная. Это означает, что такая переменная не видна за пределами минимальной WFF, связавшей эту переменную. При вычислении значения такой WFF используется не одно значение связанной переменной, а вся ее область определения.
Пример. Пусть СОТР1 и СОТР2 - две кортежные переменные, определенные на отношении СОТРУДНИКИ. Тогда, WFF
EXISTS СОТР2 (СОТР1.СОТР_ЗАРП > СОТР2.СОТР_ЗАРП) для текущего кортежа переменной СОТР1 принимает значение true в том и только в том случае, если во всем отношении СОТРУДНИКИ найдется кортеж (связанный с переменной СОТР2) такой, что значение его атрибута СОТР_ЗАРП удовлетворяет внутреннему условию сравнения.
WFF FORALL СОТР2 (СОТР1.СОТР_ЗАРП > СОТР2.СОТР_ЗАРП) для текущего кортежа переменной СОТР1 принимает значение true в том и только в том случае, если для всех кортежей отношения СОТРУДНИКИ (связанных с переменной СОТР2) значения атрибута СОТР_ЗАРП удовлетворяют условию сравнения.
На самом деле, правильнее говорить не о свободных и связанных переменных, а о свободных и связанных вхождениях переменных. Легко видеть, что если переменная var является связанной в WFF form, то во всех WFF, включающих данную, может использоваться имя переменной var, которая может быть свободной или связанной, но в любом случае не имеет никакого отношения к вхождению переменной var в WFF form.
Пример:
EXISTS СОТР2 (СОТР1.СОТР_ОТД_НОМ = СОТР2.СОТР_ОТД_НОМ)
AND FORALL СОТР2 (СОТР1.СОТР_ЗАРП > СОТР2.СОТР_ЗАРП)
Здесь мы имеем два связанных вхождения переменной СОТР2 с совершенно разным смыслом.
Описанное исчисление не обладает вычислительной полнотой, так как не позволяет выполнять вычисления. Добавление вычислительных функций в исчисление можно реализовать путем расширения определения операндов сравнения и элементов целевого списка таким образом, чтобы они допускали использование скалярных выражений с литералами, ссылками на атрибуты и итоговыми функциями.
качестве итоговых могут выступать следующие функции: COUNT (количество), SUMM (сумма), АVG (среднее), МАХ (максимальное), MIN (минимальное).
Для данных элементов целесообразно использовать спецификацию вида "AS <имя атрибута>я, где можно явно задать имя результирующему атрибуту.
Пример.
Определить студента с максимальным рейтингом
Студент.ФИО, MAX(Рейтинг) AS Максимальный_Рейтинг WHERE Студент.Номер_зачетной_книжки=Рейтинг.Номер_ зачетной_книжки _
3.10. Реляционное исчисление доменов
В исчислении доменов областью определения переменных являются не отношения, а домены. Применительно к базе данных Рейтинг студентов можно говорить, например, о доменных переменных ИМЯ (значения - допустимые имена) или Номер_зачетной_книжки (значения - допустимые номера зачетных книжек студентов).
Основным формальным отличием исчисления доменов от исчисления кортежей является наличие дополнительного набора предикатов, позволяющих выражать так называемые условия членства. Если R - это n-арное отношение с атрибутами a1, a2, ..., an, то условие членства имеет вид
R(a1i:v1i...aim:vim)(m<=n)
где vij - это либо литерально задаваемая константа, либо имя кортежной переменной. Условие членства принимает значение true в том и только в том случае, если в отношении R существует кортеж, содержащий указанные значения указанных атрибутов.
Если vij - константа, то на атрибут aij задается жесткое условие, не зависящее от текущих значений доменных переменных; если же - имя доменной переменной, то условие членства может принимать разные значения при разных значениях этой переменной.
Во всем остальном формулы и выражения исчисления доменов выглядят похожими на формулы и выражения исчисления кортежей. В частности, конечно, различаются свободные и связанные вхождения доменных переменных.
Для примера сформулируем с использованием исчисления доменов запрос "Выдать номера и имена студентов сотрудников, не получающих минимальную заработную плату" (будем считать для простоты, что мы определили доменные переменные, имена которых совпадают с именами атрибутов отношения СОТРУДНИКИ, а в случае, когда требуется несколько доменных переменных, определенных на одном домене, мы будем добавлять в конце имени цифры):
СОТР_НОМ, СОТР_ИМЯ
WHERE EXISTS СОТР_ЗАРП1
(СОТРУДНИКИ (СОТР_ЗАРП1) AND
СОТРУДНИКИ (СОТР_НОМ, СОТР_ИМЯ, СОТР_ЗАРП) AND
СОТР_ЗАРП > СОТР_ЗАРП1)
Реляционное исчисление доменов является основой большинства языков запросов, основанных на использовании форм. В частности, на этом исчислении базировался известный язык Query-by-Example, который был первым (и наиболее интересным) языком в семействе языков, основанных на табличных формах.
17. SQL (обычно произносимый как "СИКВЭЛ" или "ЭСКЮЭЛЬ") символизирует собой Структурированный Язык Запросов. Это - язык, который дает Вам возможность создавать и работать в реляционных базах данных, являющихся наборами связанной информации, сохраняемой в таблицах.
Информационное пространство становится более унифицированным. Это привело к необходимости создания стандартного языка, который мог бы использоваться в большом количестве различных видов компьютерных сред. Стандартный язык позволит пользователям, знающим один набор команд, использовать их для создания, нахождения, изменения и передачи информации - независимо от того, работают ли они на персональном компьютере, сетевой рабочей станции, или на универсальной ЭВМ.
В нашем все более и более взаимосвязанном компьютерном мире, пользователь снабженый таким языком, имеет огромное преимущество в использовании и обобщении информации из ряда источников с помощью большого количества способов.
Элегантность и независимость от специфики компьютерных технологий, а также его поддержка лидерами промышленности в области технологии реляционных баз данных, сделало SQL (и, вероятно, в течение обозримого будущего оставит его) основным стандартным языком. По этой причине, любой, кто хочет работать с базами данных 90-х годов, должен знать SQL.
Стандарт SQL определяется ANSI (Американским Национальным Институтом Стандартов) и в данное время также принимается ISO (Международной Организацией по Стандартизации). Однако, большинство коммерческих программ баз данных расширяют SQL без уведомления ANSI, добавляя различные особенности в этот язык, которые, как они считают, будут весьма полезны. Иногда они несколько нарушают стандарт языка, хотя хорошие идеи имеют тенденцию развиваться и вскоре становиться стандартами "рынка" сами по себе в силу полезности своих качеств.
На данном уроке мы будем, в основном, следовать стандарту ANSI, но одновременно иногда будет показывать и некоторые наиболее общие отклонения от его стандарта.
Точное описание особенностей языка приводится в документации на СУБД, которую Вы используете. SQL системы InterBase 4.0 соответствует стандарту ANSI-92 и частично стандарту ANSI-III.
Общие сведения о SQL Команды SQL делятся на функциональные группы, что облегчает из запоминание. Вот эти группы: • Определение данных (Data Definition) • Манипулирование данными (Data Manipulation) • Управление данными (Data Control) • Выборка данных (Data Retrieval) • Управление транзакциями (Transaction Control) Теперь разберем более подробно эти группы: Определение данных Все основные СУБД, являются так называемыми платформами баз данных. Это означает, что они предоставляют среду, очень хорошо поддерживающие работу с таблицами, но не содержит никаких заранее созданных таблиц. Вы должны сами определять состав и конфигурацию хранимых данных (т.е. их тип и т.д.). Для этого в SQL существует ряд специальных команд: CREATE, ALTER, DROP, RENAME и TRUNCATE. Эти команды входят в группу, называемых языком определения данных (DDL, Data Definition Language). Манипулирование данными Допустим, вы научились создавать таблицы. Что же дальше? Разумеется поместить в них данные. В SQL есть команда INSERT, позволяющая добавлять данные в таблицы. После того как данные вставлены, их можно изменять, используя команду UPDATE, или удалять, используя команду DELETE. Эта категория команд называется языком манипулирования данными (DML, Data Manipulation Language). Управление данными Возможность предоставлять некоторым пользователям доступ к определенным таблицам, в то время, как другим это запрещено, обеспечивается за счет присваивания пользователям привилегий на таблицы или действия. Существуют два вида привилегий: • объектная • системная Объектная привилегия разрешает пользователю выполнять определенные действия над таблицей (или другими объектами баз данных) Системная привилегия, напротив, разрешает пользователю выполнять действия определенного типа во всей базе данных. Привилегии базы данных присваиваются и удаляются с помощью SQL-команд GRANT и REVOKE, соответственно. Эти команды относятся к категории, называемой языком управления данными (DCL, Data Control Language). Выборка данных Смысл помещения информации в базу данных состоит в том, чтобы получить ее обратно контролируемым образом. В этой категории всего одна команда – SELECT, но она имеет широкий набор параметров, обеспечивающих огромную гибкость. Вероятно, именно эту команду вы будете использовать чаще всего, особенно если планируете обращаться к SQL из другого языка программирования, такого, как Java, C++ или Pascal. Управление транзакциями SQL позволяет отменять любые из последних команд языка манипулирования данными (DML) до того, как они будут применены к базе данных. После выполнения одной, или нескольких команд DML вы можете ввести либо команду COMMIT для сохранения изменений в базе данных, либо команду ROLLBACK для их отмены («отката»). Отмена возможна на разных уровнях: вы можете отменить самую последнюю транзакцию DML, несколько последних транзакций или выполнить отмену на любую нужную глубину. Однако для того, чтобы выполнять многоуровневый повтор, требуется несколько больше предварительных действий, чем в вашем любимом текстовом процессоре. Если вы хотите иметь возможность отката к промежуточным точкам, они должны быть предварительно отмечены с помощью команды SAVEPOINT.