

Кодирование целых чисел
Для преобразования целого числа в двоичный код надо делить его пополам до тех пор, пока в остатке не образуется ноль или единица. Совокупность остатков от каждого деления, записанных справа налево, образует двоичный код десятичного числа.
Для представления целых чисел используется байт, имеющий восемь двоичных разрядов (рис.1).
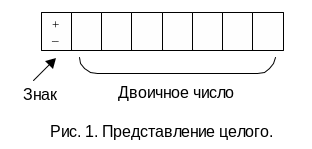
Первый разряд используется для хранения знака числа. Обычно "+" кодируется нулём, а "–" – единицей. Диапазон представления целых чисел зависит от числа двоичных разрядов. С помощью одного байта могут быть представлены числа в диапазоне от –128 до +127. При использовании двух байтов могут быть представлены числа от –32768 до +32767.
Кодирование вещественных чисел
Существуют два способа представления вещественных чисел в памяти компьютера: с фиксированной точкой и с плавающей точкой.
При представлении вещественных чисел в форме с фиксированной точкой положение десятичной точки в машинном слове фиксировано, например (рис. 2):
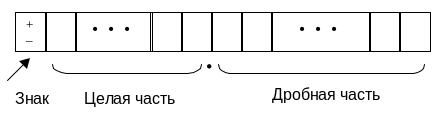
Рис.2. Вещественное число с фиксированной точкой.
Чаще всего точка фиксируется перед первым разрядом числа (рис.3).
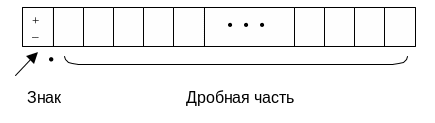
Рис.3. Вещественное число с точкой перед первым разрядом.
Целое число является частным случаем числа с фиксированной точкой, когда точка фиксирована после последнего разряда.
В форме с плавающей точкой вещественное число х представляется в виде
![]()
где
![]() и называется мантиссой, p
– целое число, называемой порядком
(рис.4).
и называется мантиссой, p
– целое число, называемой порядком
(рис.4).
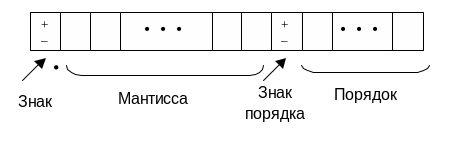
Рис. 4. Вещественное число с плавающей точкой.
Количество позиций, отводимых для мантиссы, определяет точность представления чисел, а количество позиций, отводимых для порядка – диапазон представления чисел.
Обычно мантисса записывается в нормализованном виде, то есть так, чтобы отсутствовали незначащие нули в старших разрядах:
0.0011101 ненормализованное представление,
0.1110100 нормализованное представление.
При сложении чисел в форме с плавающей точкой в общем случае нельзя складывать их мантиссы. Если слагаемые имеют разные порядки, то одинаковые разряды мантиссы будут на самом деле изображать разные разряды числа, например:
0.27103 и 0.31102
При сложении чисел необходимо предварительно выровнять их порядки, то есть числу с меньшим порядком приписать порядок второго числа и соответствующим образом изменить мантиссу, например:
0.31102 = 0.031103.
Кодирование текстовых данных
Если каждому символу алфавита сопоставить целое число, то можно с помощью двоичного кода кодировать текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватает, чтобы закодировать все строчные и прописные буквы английского или русского алфавита, а также знаки препинания, цифры, символы основных арифметических операций и некоторые специальные символы, например "%".
Технически это просто, но существуют организационные сложности. Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, А это трудно осуществить из-за использования различных символов в национальных алфавитах. Сейчас по ряду причин наибольшее распространение получил стандарт США ANСII – American National Code for Information Interchange – стандартный код для обмена информацией. В системе кодирования ANСII закреплены две таблицы кодирования – базовая со значениями кодов от 0 до 127, и расширенная с кодами от 128 до 255.
Коды от 0 до 31 базовой таблицы содержат так называемые управляющие коды, которым не соответствуют символы языка. Они служат для управления устройствами ввода-вывода. Коды с 32 по 127 служат для кодирования символов английского алфавита, знаков препинания, цифр и некоторых других символов. Расширенная таблица с кодами от 128 до 255 содержит набор специальных символов.
Аналогичные системы кодирования разработаны и а других странах. В России большое распространение имеет код КОИ-8.
Трудности создания единой системы кодирования текстовых данных связаны с ограниченным набором кодов (256). Если кодировать символы не 8-разрядными двоичными числами, а 16-разрядными, это позволит иметь набор из 65536 различных кодов. Этого достаточно, чтобы в одной таблице разместить символы большинства языков. Такая система кодирования называется Unicode – универсальный код. Переход к этой системе долго сдерживался из-за недостатка памяти компьютеров, так как в системе Unicode все текстовые документы становятся вдвое длиннее. В настоящее время технические сложности преодолены и происходит постепенный переход на универсальную систему кодирования.