

8.Охарактеризовать общую схему подписывания и проверки подписи с использованием хэш-функции. Кратко пояснить схему вычисления хэш-функции по гост р 34.11-94, по алгоритму sha.
Хэш-функции являются одним из важных элементов криптосистем на основе ключей. Их легко вычислить, но почти невозможно подделать. Хэш-функция имеет исходные данные переменной длины и возвращает строку фиксированного размера, часто называемую дайджестом сообщения (англ. – Message Digest или далее MD).
Хэш-функция должна удовлетворять ряду условий:
Хэш-функция Н должна применяться к блоку данных любой длины.
Хэш-функция Н создает выход фиксированной длины.
Н(М) относительно легко (за полиномиальное время) вычисляется для любого значения М.
Для любого данного значения хэш-кода h вычислительно невозможно найти M такое, что Н (M) = h.
Вычислительно невозможно найти произвольную пару (х, y) такую, что H (y) = H (x).
Изменение даже одного бита исходного сообщения M должно приводить к значительному изменению h.
Большинство хэш-функций строится на основе однонаправленной функции f(), которая образует выходное значение фиксированной длины n при задании двух входных значений длиной n.
Этими входами являются блок исходного текста Mi и хэш-значение Нi-1 предыдущего блока текста.
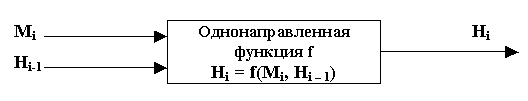
Хэш-значение, вычисляемое при вводе последнего блока текста, становится хэш-значением всего сообщения М.
Определение. Хэш-функцией называется односторонняя функция, предназначенная для получения дайджеста файла, сообщения или некоторого блока данных: h = H(M), где М является блоком данных произвольной длины, а h является хэш-кодом фиксированной длины.
В хэш-функциях входное значение (сообщение, файл и т.п.) рассматривается как последовательность n-битных блоков. Входное значение обрабатывается последовательно блок за блоком, и создается m-битное значение хэш-кода.
Одним из простейших примеров хэш-функции является побитный XOR каждого блока:
Сi = bi1 bi2 . . . bik,
где Сi - i-ый бит хэш-кода, 1 ≤ i ≤ n;
k - число n-битных блоков входа;
bij - i-ый бит в j-ом блоке.
В результате получается хэш-код длины n, известный как продольный избыточный контроль. Это эффективно при случайных сбоях для проверки целостности данных.
При вводе сообщения М произвольной длины менее 264 бит алгоритм SНА вырабатывает 160-битовое выходное сообщение, называемое дайджестом сообщения МD (Message Digest). Затем этот дайджест сообщения используется в качестве входа алгоритма DSА, который вычисляет цифровую подпись сообщения М. Формирование цифровой подписи для дайджеста сообщения, а не для самого сообщения повышает эффективность процесса подписания, поскольку дайджест сообщения обычно намного короче самого сообщения.
Такой же дайджест сообщения должен вычисляться пользователем, проверяющим полученную подпись, при этом в качестве входа в алгоритм SНА используется полученное сообщение М.
Рассмотрим подробнее работу алгоритма хэширования SНА. Прежде всего исходное сообщение М дополняют так, чтобы оно стало кратным 512 битам. Дополнительная набивка сообщения выполняется следующим образом: сначала добавляется единица, затем следуют столько нулей, сколько необходимо для получения сообщения, которое на 64 бита короче, чем кратное 512, и наконец добавляют 64-битовое представление длины исходного сообщения.
Инициализируется пять 32-битовых переменных в виде: А = 0х67452301, В = 0хЕFСDАВ89, С = 0х98ВАDСFЕ, D = 0x10325476, Е = 0хС3D2Е1F0
Затем начинается главный цикл алгоритма. В нем обрабатывается по 512 бит сообщения поочередно для всех 512-битовых блоков, имеющихся в сообщении. Первые пять переменных А, В, С, D, Е копируются в другие переменные a, b, с, d, е:
Главный цикл содержит четыре цикла по 20 операций каждый. Каждая операция реализует нелинейную функцию от трех из пяти переменных а, b, с, d, е, а затем производит сдвиг и сложение.
Алгоритм SНА имеет следующий набор нелинейных функций:
fi (X, Y, Z) = (X Y) ((X) Z) |
для t = 0...19, |
fi (X, Y, Z) = X Y Z |
для t = 20...39, |
fi (X, Y, Z) = (X Y) (X Z) (Y Z) |
для t = 40...59,
|
fi (X, Y, Z) = X Y Z |
для t = 60...79, |
![]()
![]()
![]()
где t - номер операции.
В алгоритме используются также четыре константы:
Кt = 0х5А827999 для t = 0...19,
Кt = 0х6ЕD9ЕВА1 для t = 20...39,
Кt = 0х8F1ВВСDС для t = 40...59,
Кt = 0хСА62С1D6 для t = 60...79.
Блок сообщения преобразуется из шестнадцати 32-битовых слов (М0...М15) в восемьдесят 32-битовых слов (W0...W79) с помощью следующего алгоритма:
Wt = Мt для t = 0...15,
Wt = (Wt-3 Wt-8 Wt-14 Wt-16) <<< 1 для t = 16...79,
Wt
= (Wt-3
![]() Wt-8
Wt-14
Wt-16)
Wt-8
Wt-14
Wt-16)
где t - номер операции, Wt - t-й субблок расширенного сообщения, <<< S - циклический сдвиг влево на S бит.
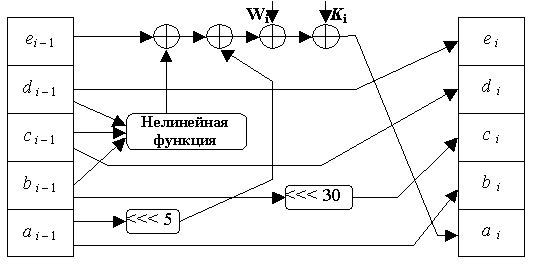
С учетом введенных обозначений главный цикл из восьмидесяти операций можно описать так:
FOR i = 0 to 79
Temporary = (а <<< 5) + fi (b, c, d) + е + Wi + Ki
e = d
d = c
c = (b <<< 30)
b = a
a = Temporary
После окончания главного цикла значения а, b, с, d, е складываются с А, В, С, D, Е соответственно, и алгоритм приступает к обработке следующего 512-битового блока данных. Окончательный выход формируется в виде конкатенации значений А, В, С, D, Е.
Построение ХФ на основе алгоритма ГОСТ 34.11
ГОСТ 34.11-94 «Информационная технология. Криптографическая защита информации. Функция хэширования».
ГОСТ Р 34.11-94 определяет алгоритм и процедуру вычисления хэш-функции для любых последовательностей двоичных символов, применяемых в криптографических методах обработки и защиты информации. Этот стандарт базируется на блочном алгоритме с 64-битовым блоком и 256-битовым ключом. Данная хэш-функция формирует 256-битовое хэш-значение. Его структура довольно сильно отличается от структуры алгоритмов SHA-1,2 или MD5, в основе которых лежит алгоритм MD4.


Основой описываемой хэш-функции является шаговая функция хеширования:
![]()
Каждый блок сообщения, начиная с первого, подаётся на шаговую функцию для вычисления промежуточного значения хэш-функции:
![]()
После вычисления Hn + 1 конечное значение хэш-функции – h:
![]() где K —
контрольная сумма М
где K —
контрольная сумма М
![]() где L — длина
сообщения M в
где L — длина
сообщения M в
битах по модулю 2256
ГОСТ Р 34.11-94. Генерация ключей
Преобразование
блоков длины 256 бит:
![]()
![]()
![]()
![]()
Присваиваются следующие начальные значения:
i = 1, U = H, V = M.
W = U V, K1 = Р (W).
Алгоритм генерации ключей:
Ключи K2, K3, K4 вычисляются последовательно по следующему алгоритму:
U = A(U) Сi,
V = A(A(V)),
W = U V,
Ki = Р(W)
После генерирования ключей происходит шифрование Hin по ГОСТ 28147-89 в режиме простой замены, процедуру шифрования обозначим через E. Для шифрования Hin разделяют на четыре блока по 64 бита:
![]()
и зашифровывают каждый из блоков:
s1 = E(h1,K1)
s2 = E(h2,K2)
s3 = E(h3,K3)
s4 = E(h4,K4)
После чего блоки собирают в 256 битный блок:
![]()
На последнем этапе происходит перемешивание Hin, S и m в итоге получают Hout.
Для описания процесса преобразования сначала необходимо определить функцию ψ, которая производит элементарное преобразование блока длиной 256 бит в блок той же длины:
![]()
где y16,y15,...,y2,y1 — подблоки блока Y длины 16 бит.
Перемешивающее
преобразование имеет вид:
![]()
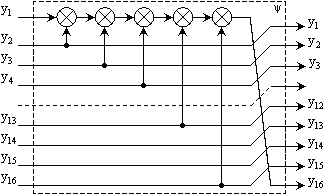
![]()
Алгоритм
1. Генерируются 4 ключа шифрования Кj путем линейного смешивания Mi, Нi – 1 и некоторых констант Cj.
2. Каждый ключ Kj, используют для шифрования 64-битовых подслов hi слова Нi-1 в режиме простой замены: Sj = EKj(hj). Результирующая последовательность S4, S3, S2, S1 длиной 256 бит запоминается во временной переменной S.
3. Значение Нi, является сложной, хотя и линейной функцией смешивания S, Mi и Нi – 1.
При вычислении окончательного хэш-значения сообщения М учитываются значения трех связанных между собой переменных:
Нn – хэш-значение последнего блока сообщения; Z – значение контрольной суммы, получаемой при сложении по модулю 2 всех блоков сообщения; l – длина сообщения.
Эти три переменные и дополненный последний блок М' сообщения объединяются в окончательное хэш-значение следующим образом:
H = f (Z M', f (l, f (M', Нn)))