

2.4 Диаграммы потоков данных. Формирование словаря данных, определение логики процессов, определение накопителей данных, использование информационных моделей в системных исследованиях.
Диаграммы потоков данных (Data Flow Diagrams — DFD) представляют собой иерархию функциональных процессов, связанных потоками данных. Цель такого представления — продемонстрировать, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между этими процессами.
Для построения DFD традиционно используются две различные нотации, соответствующие методам Йордона-ДеМарко и Гейна-Сэрсона. Эти нотации незначительно отличаются друг от друга графическим изображением символов (далее в примерах используется нотация Гейна-Сэрсона).
Диаграмма потока данных - логическая модель потока данных в системе, которая показывает границы системы, процессы и каким образом объекты диаграммы логически связаны.
Диаграмма потока данных - превосходный инструмент для получения детальной информации о компонентах системы, процессов и объектах данных, обеспечивает аналитика логической схемой системы. Изображение компонент системы с помощью контекстной диаграммы помогает аналитику, пользователю и менеджеру представлять альтернативные логические проекты системы высокого уровня. Элементы диаграммы потока данных ведут непосредственно к физическому проекту, к процессам, предполагающим программы и процедуры, потокам данных, предполагающим связи и хранилищ данных, предполагающим сущности данных, файлы и базы данных.
Диаграммы потоков данны (DFD - Data Flow Diagramm) строятся из следующих элементов:

Рисунок 10 - Шкала методов.
Такой тип обозначений элементов DFD-диаграммы получил название "нотация Йордона - Де Марко", по именам разработавших его специалистов.
Функции, хранилища и внешние сущности на DFD-диаграмме связываются дугами, представляющими потоки данных. Дуги могут разветвляться или сливаться, что означает, соответственно, разделение потока данных на части, либо слияние объектов. При интерпретации DFD-диаграммы используются следующие правила:
Функции преобразуют входящие потоки данных в выходящие.
Хранилища данных не изменяют потоки данных, а служат только для хранения поступающих объектов.
Преобразования потоков данных во внешних сущностях игнорируется.
Построим DFD-диаграмму для предприятия, строящего свою деятельность по принципу "изготовление на заказ". На основании полученных заказов формируется план выпуска продукции на определенный период. В соответствии с этим планом определяются потребность в комплектующих изделиях и материалах, а также график загрузки производственного оборудования. После изготовления продукции и проведения платежей, готовая продукция отправляется заказчику.
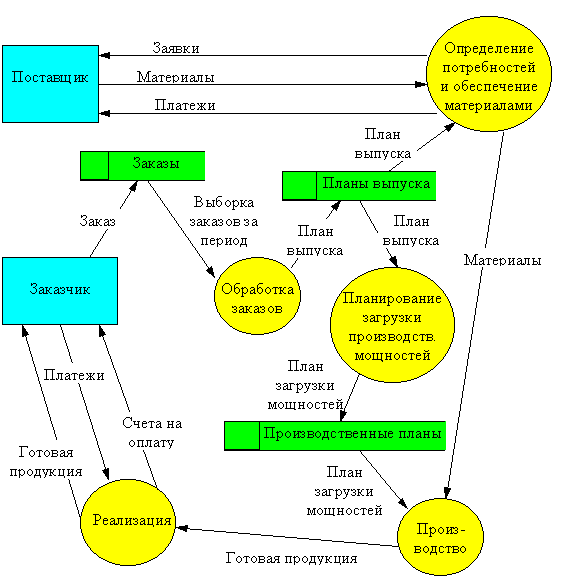
Рисунок 11– Шкала методов.
Эта диаграмма представляет самый верхний уровень функциональной модели. Естественно, это весьма грубое описание предметной области. Уточнение модели производится путем детализации необходимых функций на DFD-диаграмме следующего уровня. Так мы можем разбить функцию "Определение потребностей и обеспечение материалами" на подфункции "Определение потребностей", "Поиск поставщиков", "Заключение и анализ договоров на поставку", "Контроль платежей", "Контроль поставок", связанные собственными потоками данных, которые будут представлены на отдельной диаграмме. Детализация модели должна производится до тех пор, пока она не будет содержать всю информацию, необходимую для построения ифнормационной системы.
Создание диаграммы потока данных ориентировано на процессы. Следовательно, относительно легко пропустить ключевые элементы данных и производные. Сбалансированная диаграмма потока данных подтверждает внутреннюю логику модели, но не обязательно показывает отсутствующие элементы. Попытка сбалансировать сложную логическую модель без соответствующего программного обеспечения (типа CASE-средств) может оказаться трудной задачей.
Основными компонентами диаграмм потоков данных являются:
внешние сущности;
системы и подсистемы;
процессы;
накопители данных;
потоки данных.
Внешняя сущность представляет собой материальный объект или физическое лицо, являющиеся источником или приемником информации, например, заказчики, персонал, поставщики, клиенты, склад. Внешняя сущность обозначается квадратом, расположенным над диаграммой и бросающим на нее тень для того, чтобы можно было выделить этот символ среди других обозначений.

Рисунок 10 – Графическое изображение внешней сущности.
При построении модели сложной системы она может быть представлена в самом общем виде на так называемой контекстной диаграмме в виде одной системы как единого целого, либо может быть декомпозирована на ряд подсистем.
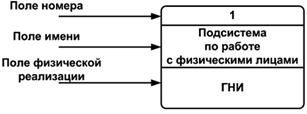
Рисунок 11- Подсистема по работе с физическими лицами (ГНИ — Государственная налоговая инспекция)
Номер подсистемы служит для ее идентификации. В поле имени вводится наименование подсистемы в виде предложения с подлежащим и соответствующими определениями и дополнениями.
Процесс представляет собой преобразование входных потоков данных в выходные в соответствии с определенным алгоритмом. Физически процесс может быть реализован различными способами: это может быть подразделение организации (отдел), выполняющее обработку входных документов и выпуск отчетов, программа, аппаратно реализованное логическое устройство и т.д.
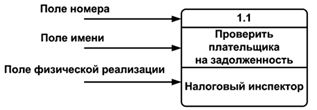
Рисунок 12- Графическое изображение процесса
Номер процесса служит для его идентификации. В поле имени вводится наименование процесса в виде предложения с активным недвусмысленным глаголом в неопределенной форме (вычислить, рассчитать, проверить, определить, создать, получить), за которым следуют существительные в винительном падеже, например: "Ввести сведения о налогоплательщиках", "Выдать информацию о текущих расходах", "Проверить поступление денег".
Информация в поле физической реализации показывает, какое подразделение организации, программа или аппаратное устройство выполняет данный процесс.
Накопитель данных — это абстрактное устройство для хранения информации, которую можно в любой момент поместить в накопитель и через некоторое время извлечь, причем способы помещения и извлечения могут быть любыми.
Накопитель данных может быть реализован физически в виде микрофиши, ящика в картотеке, таблицы в оперативной памяти, файла на магнитном носителе и т.д. Накопитель данных на диаграмме потоков данных изображается, как показано на Рис. 13.
![]()
Рисунок 13- Графическое изображение накопителя данных
Накопитель данных идентифицируется буквой "D" и произвольным числом. Имя накопителя выбирается из соображения наибольшей информативности для проектировщика.
Накопитель данных в общем случае является прообразом будущей базы данных, и описание хранящихся в нем данных должно соответствовать модели данных.
Поток данных определяет информацию, передаваемую через некоторое соединение от источника к приемнику. Реальный поток данных может быть информацией, передаваемой по кабелю между двумя устройствами, пересылаемыми по почте письмами, магнитными лентами или дискетами, переносимыми с одного компьютера на другой и т.д.
Поток данных на диаграмме изображается линией, оканчивающейся стрелкой, которая показывает направление потока (Рис. 14). Каждый поток данных имеет имя, отражающее его содержание.
Рисунок 14- Поток данных. Построение иерархии диаграмм потоков данных
Методология SADT (IDEF0).
Методология SADT (Structured Analisys and Design Technique) разработана Дугласом Т. Россом в 1969-73 годах. Она изначально создавалась для проектирования систем более общего назначения по сравнению с другими структурными методами, выросшими из проектирования программного обеспечения. IDEF0 (подмножество SADT) используется для моделирования бизнес-процессов в организационных системах и имеет развитые процедуры поддержки коллективной работы.
В терминах IDEF0 система представляется в виде комбинации блоков и дуг. Блоки представляют функции системы, дуги представляют множество объектов (физические объекты, информация или действия, которые образуют связи между функциональными блоками). Место соединения дуги с блоком определяет тип интерфейса:
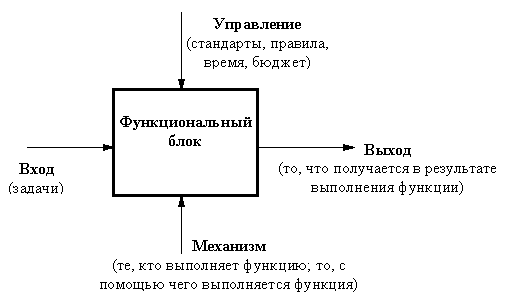
Рисунок 15- Схема IDEF0
Правила интерпретации модели:
Функциональный блок (функция) преобразует входные объекты в выходные.
Управление определяет, когда и как это преобразование может или должно произойти.
Исполнитель осуществляет это преобразование.
С дугами связываются метки на естественном языке, описывающие данные, которые они представляют. Дуги показывают, как функции системы связаны между собой, как они обмениваются данными и осуществляют управление друг другом. Выходы одной функции могут быть входами, управлением или исполнителями другой.
Дуги могут разветвляться и соединяться. Ветвление означает множественность (идентичные копии одного объекта) или расщепление (различные части одного объекта). Соединение означает объединение или слияние объектов.
Каждый блок IDEF0-диаграммы может быть представлен несколькими блоками, соединенными интерфейсными дугами, на диаграмме следующего уровня. Эти блоки представляют подфункции (подмодули) исходной функции. Каждый из подмодулей может быть декомпозирован аналогичным образом. Число уровней не ограничивается, зато рекомендуется на одной диаграмме использовать не менее 3 и не более 6 блоков.
На следующем рисунке представлена IDEF0-модель деятельности предприятия.
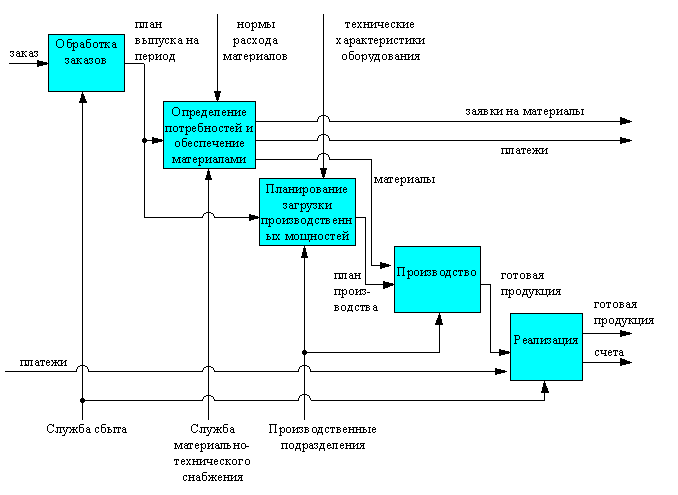
Рисунок 16 - IDEF0-модель деятельности предприятия.
Структурированный естественный язык применяется для понятного, достаточно строгого описания спецификаций процессов. При его использовании приняты следующие соглашения:
• логика процесса выражается в виде комбинации последовательных конструкций, конструкций выбора и итераций;
• глаголы должны быть активными, недвусмысленными и ориентированными на целевое действие (заполнить, вычислить, извлечь, а не модернизировать, обработать);
• логика процесса должна быть выражена четко и недвусмысленно.
После построения законченной модели системы ее необходимо верифицировать (проверить на полноту и согласованность). В полной модели все ее объекты (подсистемы, процессы, потоки данных) должны быть подробно описаны и детализированы. Выявленные недетализированные объекты следует детализировать, вернувшись на предыдущие шаги разработки. В согласованной модели для всех потоков данных и накопителей данных должно выполняться правило сохранения информации: все поступающие куда-либо данные должны быть считаны, а все считываемые данные должны быть записаны.
Рассмотрим общий алгоритмипостроении бизнес-моделей:
1. Описание контекста процессов и построение начальной контекстной диаграммы.
Начальная контекстная диаграмма потоков данных должна содержать нулевой процесс с именем, отражающим деятельность организации, внешние сущности, соединенные с нулевым процессом посредством потоков данных. Потоки данных соответствуют документам, запросам или сообщениям, которыми внешние сущности обмениваются с организацией.
2. Спецификация структур данных.
Определяется состав потоков данных и готовится исходная информация для построения концептуальной модели данных в виде структур данных. Выделяются все структуры и элементы данных типа "итерация", "условное вхождение" и "альтернатива". Простые структуры и элементы данных объединяются в более крупные структуры. В результате для каждого потока данных должна быть сформирована иерархическая (древовидная) структура, конечные элементы (листья) которой являются элементами данных, узлы дерева являются структурами данных, а верхний узел дерева соответствует потоку данных в целом.
3. Построение начального варианта концептуальной модели данных.
Для каждого класса объектов предметной области выделяется сущность. Устанавливаются связи между сущностями и определяются их характеристики. Строится диаграмма "сущность-связь" (без атрибутов сущностей).
4. Построение диаграмм потоков данных нулевого и последующих уровней.
Можно построить диаграмму для каждого события, поставив ему в соответствие процесс и описав входные и выходные потоки, накопители данных, внешние сущности и ссылки на другие процессы для описания связей между этим процессом и его окружением. После этого все построенные диаграммы сводятся в одну диаграмму нулевого уровня.
Процессы разделяются на группы, которые имеют много общего (работают с одинаковыми данными и/или имеют сходные функции). Они изображаются вместе на диаграмме более низкого (первого) уровня, а на диаграмме нулевого уровня объединяются в один процесс. Выделяются накопители данных, используемые процессами из одной группы.
Декомпозируются сложные процессы и проверяется соответствие различных уровней модели процессов.
Накопители данных описываются посредством структур данных, а процессы нижнего уровня — посредством спецификаций.
5. Уточнение концептуальной модели данных.
Определяются атрибуты сущностей. Выделяются атрибуты-идентификаторы. Проверяются связи, выделяются (при необходимости) связи "супертип-подтип".
Проверяется соответствие между описанием структур данных и концептуальной моделью (все элементы данных должны присутствовать на диаграмме в качестве атрибутов
Контрольные вопросы и упражнения.
Что заставляет нас пользоваться моделями вместо самих моделируемых объектов?
Какие функции выполняют модели во всякой целесообразной деятельности? Можно ли осуществлять такую деятельность без моделирования?
Каково главное отличие между познавательной и прагматической моделями?
Какими средствами располагает человек для построения моделей?
Что необходимо для перехода от моделей в терминах естественного языка к математическим моделям?
Что общего между моделью и оригиналом при косвенном подобии?
Почему знаки можно назвать материальными по форме и абстрактными по существу моделями?
Что такое ингерентность модели?
В каком смысле можно говорить о конечности моделей?
В чем различие между адекватностью и истинностью модели?
Каковы причины того, что любая модель со временем изменяется?
Чем объясняется существование различных определений системы? Как совместить справедливость каждого из них с тем, что они различны?
Соответствие между конструкцией системы и ее целью не однозначно, но и не произвольно. Что же их связывает?
От чего зависит количество входов и выходов модели “черного ящика” для данной системы?
Какими признаками должна обладать часть системы, чтобы ее можно было считать элементом?
Что общего и в чем различие между понятием элемента и его моделью “черного ящика”?
Какова связь между вторым определением системы и ее структурной схемой?
Какие особенности системы отражены в ее графе и какие свойства системы не отображаются этой моделью?
В чем различие между функционированием и развитием?
Каким способом удается компактно описать связь между входом и выходом системы, если значение выхода в данный момент зависит от всей предыстории входа?
В чем состоит условие физической реализуемости динамической модели?
Какие приемы могут помочь повысить степень полноты содержательных моделей систем?
Приведите примеры:
а) системы, которая предназначена для выполнения определенной цели, но которую можно использовать и для других целей;
б) системы, спроектированной специально для реализации одновременно нескольких различных целей;
в) разных систем, предназначенных для одной и той же цели.
Сформулируйте цель работы вашего факультета так, чтобы она не была общей для других факультетов, в том числе для родственных факультетов других вузов.
Обсудите проблему множественности входов и выходов на примере знакомой вам системы (радиоприемника, столовой, велосипеда и т.п.). Перечислите при этом нежелательные входы и выходы. Установите, как можно устранить недостатки системы (нежелательные связи со средой).
Сравните формальную структурную схему какой-нибудь известной вам организации с ее реальной структурой. Обсудите расхождения.
В каких обстоятельствах карта местности является познавательной, а в каких – прагматической моделью?