

5.7. Дистрибутивный метод в семантике
Дистрибутивный метод получил распространение в науке о языке при "исследовании семантических явлений только во второй половине нашего века, т. е. относится к одному из наиболее современных приемов лингвистического анализа.
Термины "дистрибуция" и "дистрибутивный метод" неоднозначны, хотя в их основе лежит латинское слово distributio с определенным значением "распределение". Отсюда и первичное значение термина "дистрибуция" - распределение, а исходное содержание дистрибутивного метода заключается в исследовании того, как распределяются (встречаются, и сочетаются) в речевом потоке (письменном тексте) относительно одна другой языковые единицы.
Чаще всего термин "дистрибуция" употребляется в следующих двух значениях: 1) совокупность всех линейных окружений данной языковой единицы; 2) совокупность всех сочетаний исследуемой языковой единицы. Иногда эти значения не дифференцируются, и тогда дистрибуция рассматривается, как совокупность всех контекстов языковой единицы, а дистрибутивный метод - как контекстуальное исследование семантики. Во всех случаях дистрибутивный метод предполагает учет отношений между языковыми единицами, их распределение в тексте.
Как правило, значимые единицы языка распределяются в речи не произвольно, а по определенным закономерностям, которые могут иметь детерминистический (логический, точно предсказуемый) или, что гораздо чаще, вероятностный характер. В основе обоих видов закономерностей распределения лежат семантические свойства языковых единиц. В свою очередь, эти семантические свойства подразделяются на общие грамматические и индивидуальные смысловые. В то время как грамматическая сочетаемость подчиняется преимущественно детерминистическим правилам, лексическая сочетаемость определяется главным образом вероятностными правилами. Такой вид распределения слов в связном тексте, как совместная встречаемость, фактически полностью подчиняется вероятностным закономерностям.
Сущность всех указанных видов распределения языковых единиц заключается в возможности прогнозирования в речи (тексте) одних элементов на основании знания других элементов. Например, фразеологически связанная единица или грамматическая форма многих слов часто дает возможность стопроцентного (детерминистического) предсказания друго-
191
го слова или грамматической формы. Так, слово храповицкого требует глагола задать, направленная на объект грамматическая форма глагола видеть требует существительного (местоимения) в форме винительного падежа и т. д. В остальных случаях распределения слов прогнозирование подчиняется вероятностным закономерностям, т. е. можно предсказать слово или грамматическую форму лишь с известной долей вероятности. Обычно, чем больше членов высказывания известно, тем легче предсказать недостающий его член.
С учетом таких видов распределения языковых единиц, как грамматическая и лексическая сочетаемость, а также совместная их встречаемость, выделяются соответствующие разновидности дистрибутивного метода, используемые для исследования плана содержания языковых единиц. Одна из таких разновидностей называется дистрибутивно-трансформационной.] Цель применения этого метода заключается в том, чтобы выявить семантическую общность слов на основании сходства их синтаксических потенций, которые обнаруживаются в их отношении с другими словами. Как правило, оказывается, что те слова, которые в сочетании с другими словами способны к одинаковым синтаксическим преобразованиям, обладают и одинаковыми семантическими свойствами. Иначе говоря, Цюм более .сходными являются синтаксические свойства данных слов, тем ближе их значения. Способность к синтаксическим преобразованиям находится под влиянием семантического потенциала слова, и, чем разнообразнее эти преобразования, тем активнее семантические свойства слова, т. е. внутренние содержательные свойства находят одно из своих формальных выражений во внешних синтаксических проявлениях. Отсюда "синтаксическим различиям и сходствам соответствуют, как.правило, существенные семантические различия и сходства" (Апресян 1967: 25; см. также: Lyons 1977: 386).
Значит, одна из важнейших проблем семантики - системность лексических значений - имеет доступ к своему исследованию со стороны синтаксиса, что позволяет объективным путем, посредством использования внутриязыковых критериев, обнаруживать те семантические связи между словами, с помощью которых данные слова образуют лексические подсистемы, поля, группы, т. е. совокупности слов, имеющие семантическую общность. Так, например, лишь существительные типа вид, семейство, класс, разряд, категория, группа, разновидность, род и т. п. допускают следующую трансформацию: этот вид (семейство, класс, разряд
192
и. т. п.) - объекты этого вида (семейства, класса, разряда и т.п.); только существительные со значением вместилища допускают трансформацию типа банка из-под варенья - банка под варенье, бутылка из-под молока - бутылка под молоко и т. п.; только существительные со значением параметра вещей допускают трансформацию типа высотой с дом - высокий, как дом, шириной с улицу - широкий, как улица и т. п. Поскольку наиболее активными с синтаксической точки зрения являются глаголы, исследование их семантики служит удачной сферой приложения дистрибутив-чо-трансформационного метода с целью, например, таксономии глаголов с семантической точки зрения, что и осуществлено на материале русского языка (Апресян 1967).
Дистрибутивно-трансформационный анализ позволяет расклассифицировать синтаксически активные слова на семантические группы, но фактически ничего не говорит о строении (структуре) этих групп, характере семантических связей между членами группы. К тому же получаемые классы слов не представляются единственно возможными со смысловой точки зрения, поскольку лексические единицы могут объединяться в семантические группы на других основаниях, например на предметно-логических (тематические группы), морфологических (словообразовательные гнезда), формально-грамматических и др. Причем получаемые на разных основаниях таксономии не обязательно должны совпадать между собой.
Для определения силы семантической связи между членами заданной лексической подсистемы достаточно эффективной представляется дистрибутивно-статистическая методика, предложенная А. Е. Супруном. Суть этой методики заключается в статистическом анализе слов, сочетающихся с рассматриваемыми лексемами в текстах. В лексической сочетаемости проявляются семантические свойства слов, поэтому, чем больше элементов лексической сочетаемости учитывается для каждого исследуемого слова, тем полнее представляются его семантические свойства. В этом случае задача языковеда заключается в том, чтобы, изучая тексты достаточно большого и статистически достоверного объема, фиксировать в них для заданных слов все их семантические свойства, выявляемые через лексическую сочетаемость. Получаемые при этом данные предоставляют возможность составите для рассматриваемых слов своеобразную семантическую анкету, в которой дается описание значений слов путем набора реализованных ими в текстах семантических признаков. Вес или значимость каждого семантического
193
признака измеряется частотой слов, которые сочетаются с исследуемым и выражают этот признак (например, признак размера выражается прилагательными большой, огромный, громадный, маленький и т. д., признак движения - глаголами бежать, ехать, мчаться, идти и т.п.). Сравнивая значения заданных слов по совокупности выявленных таким образом семантических признаков, исследователь может с помощью статистических формул измерять степень сходства семантики слов.
Проведенные исследования по описанию значений слов разнообразных лексических групп показали, что полученные результаты в целом соответствуют как нашим интуитивным знаниям о семантике рассмотренных слов, так и данным, которые представлены для этих слов в филологических словарях (Плотников 1979).-Сильной стороной этой разновидности дистрибутивно-статистического анализа служит то, что исследование строится на большом фактическом материале, позволяющем измерять силу семантических связей между словами и на этом основании вскрывать структуру лексических подсистем, решать некоторые проблемы синонимии и антонимии (определять меру синонимичности и ан-тонимичности интересующих нас слов), измерять семантический объем слов и т. п. К факторам, ограничивающим сферу применения этой методики, относится то, что процесс исследования достаточно трудоемок, методика пригодна только для регулярно употребляемых в текстах слов.
Следующая разновидность дистрибутивного метода направлена на учет совместной встречаемости лексических единиц в заданном интервале текста (чаще всего в пределах от одноместного окружения исследуемой единицы до предложения или абзаца). Фактически в основе этой методики лежит идея, сформулированная Ф. Ф. Фортунатовым: "Чем чаще сочетаются в опыте известные духовные явления или чем сильнее они в этом сочетании, тем больше они способны воспроизводить впоследствии одно другое, и наоборот, чем реже они сочетаются в опыте или чем слабее духовные явления в этом сочетании, тем менее способны воспроизводить они впоследствии одно другое" (Фортунатов 1956: 113). На материале письменных текстов эта идея реализуется в виде совместной встречаемости тех слов, которые связаны между собой по значению, т. е. чем сильнее семантическая связь между словами, тем чаще встречаются они в тексте недалеко друг от друга. Сила семантической связи измеряется в этом случае отклонением конкретной зафиксированной в текстах частоты совместной встречаемости слов от теоретически
194
ожидаемой. Эксперименты, проведенные на материале английских текстов с помощью рассматриваемой методики, продемонстрировали ее эффективность как для выделения семантических полей, так и для вскрытия их структуры (Шайкевич 1963).
Методика, направленная на учет частоты совместной встречаемости слов, может опираться на различные исходные положения: во-первых, можно регистрировать совмест-иую встречаемость всех слов подряд и самые частые встречаемости затем подвергнуть лингвистическому анализу; во-вторых, допустимо фиксировать совместную встречаемость только тех слов, которые интересуют исследователя, например определенных синонимов, слов, принадлежащих к одной тематической группе, и т. д.
В большинстве случаев языковеды предпочитают анализировать с помощью дистрибутивно-статистического метода именно связные тексты, считая их более надежным и достоверным источником, чем, например, толковые словари, подвергаемые критике из-за субъективизма авторов в определении значений, а также из-за нечеткости и нестрогости толкований. Допуская критические замечания в адрес толковых словарей в некоторой степени правомерными, тем не менее можно полагать, что содержащиеся в них сведения о значениях слов представляют научную ценность по нескольким причинам. Во-первых, словари составляются обычно высококвалифицированными специалистами, опыт, знание языка и лингвистическая интуиция которых воплощаются в словарных материалах, используемых практически всеми грамотными людьми в качестве достоверного источника сведений о языке. Во-вторых, в филологических словарях отражены прежде всего парадигматические связи между словами (наряду с иллюстрацией, особенно в больших словарях, сочетаемости этих слов), т.е. именно те связи, которые лежат в основе таких системных группировок слов в языке, как синонимические, гипонимические, тематические и др. В-третьих, филологические словари отражают в себе данные не о конкретном тексте или некотором, стиле языка, а о лексике языка в целом. Подчеркнем также то обстоятельство, что широкое использование синонимов в толковых и двуязычных словарях для определения и перевода слов дает в руки исследователя вполне корректный лингвистический материал при изучении, например, таких проблем синонимии, как- измерение степени синонимичности слов и определение среди синонимической группы доминанты, т. е. слова, возглавляющего синонимическую группу.
195
Рассмотрим для иллюстрации одну из разновидностей Методики дистрибутивно-статистического анализа применительно к данным лексикографических источников. Материалом для исследования послужили слова работа, действие, деятельность, труд, дело, создание, творчество, которые представляются сходными по значению. Требуется определить силу семантических связей между этими словами и определить доминанту. В качестве исходного положения примем следующую предпосылку: если слова этой группы встречаются рядом в пределах словарных статей толковых и двуязычных словарей, то между словами регистрируются семантические связи. Отсюда, чем больше семантических связей в обследованных словарных статьях у данного слова с другими словами этой группы, тем выше его семантический потенциал. Слово с самым высоким семантическим потенциалом следует в таком случае признать доминантой. И далее: чем чаще встречается та или иная пара слов вместе в словарных статьях, тем сильнее между словами этой пары семантическая связь и тем синонимичнее они.
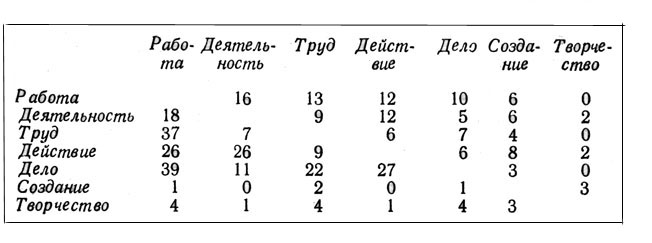
Всего обследовано пять толковых словарей русского языка (словарь В. И. Даля, словарь под ред. Д. Н. Ушакова, словарь С. И. Ожегова, 4- и 17-томные академические словари - в этих словарях рассмотрены все статьи, озаглавленные семью заданными лексемами) и двенадцать иноязычно-русских словарей (отбор статей проводился следующим образом: сначала рассмотрены русско-иноязычные словари, из которых выписаны все иностранные слова, используемые для перевода заданных русских слов, а затем исследованию были подвергнуты в иноязычно-русских словарях статьи, озаглавленные выписанными иностранными словами). Результаты подсчета частот совместных встречаемостей каждой рассматриваемой пары слов представлен ны в таблице (в верхней правой половине таблицы - результаты анализа толковых словарей, в нижней левой части - результаты анализа двуязычных словарей):
196
Наиболее сильные семантические связи отмечены, согласно данным толковых словарей, между лексемами работа и деятельность (16 связей), работа и труд (13 связей), действие и работа, действие и деятельность (по 12 связей). В двуязычных словарях наиболее сильные семантические связи имеют лексемы дело и работа (39 связей), труд и работа (37 связей).
Результаты, полученные в ходе анализа двух различных лексикографических источников, вполне сопоставимы между собой (измеренная с помощью специальной статистической формулы показателя Фехнера степень связи обоих результатов равна 0,71 при максимальном показателе 1). Еще более сильное сходство наблюдается при сопоставлении данных о весе семантического потенциала рассматриваемых слов (напомним, что семантический потенциал измеряется в нашем случае количеством семантических связей, имеющихся у каждого слова по данным обследованных словарей). Расположив слова в порядке убывания количества семантических связей в каждом виде лексикографических источников, с помощью формулы коэффициента ранговой корреляции получаем показатель 0,76 при максимальной величине 1, что свидетельствует о связи приведенных в таблице результатов.
Используя полученные данные, нетрудно определить доминантное слово в рассматриваемой группе (им является слово работа, имеющее самое большое количество связей), а также графически изобразить и вербально описать структуру данной лексической группы, в которой близость расположения слов по отношению друг к другу определяется частотой их совместной встречаемости в обследованных словарных статьях (чем чаще встречаются слова, тем ближе они находятся одно к другому в пределах данной группы).
Каждый из приемов дистрибутивного анализа может быть применен для решения конкретных семантических проблем, поскольку именно через лексическую сочетаемость и совместную встречаемость слов реализуются их разнообразные семантические свойства, т.е. проявляются те элементы значения, которые существенны для функционирования слова и для отношений между словами. Ценность результатов, полученных при использовании различных дистрибутивных методов, заключается в том, что эти результаты выводятся из лингвистической данности, в которой отражены и зафиксированы самые разнообразные аспекты языкового значения.
197
Употребляемые при исследовании семантических явлений разновидности дистрибутивного метода могут быть представлены в виде схемы (рис. 16).
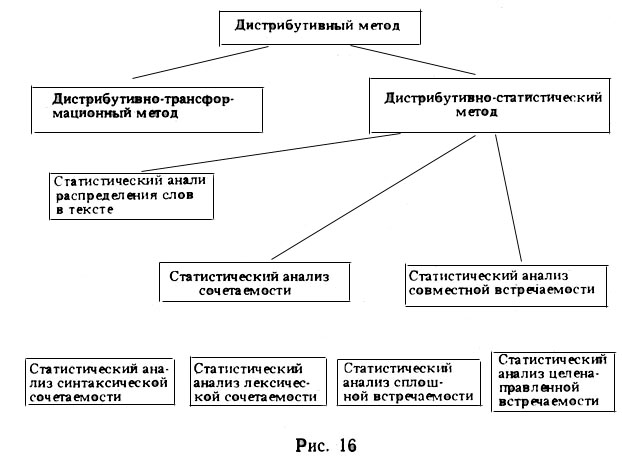
Применение дистрибутивного метода основывается на органической связи семантики и синтаксиса, значения и контекста, на смысловых связях между словами, поэтому данный метод служит объективным лингвистическим средством для выделения парадигматических классов слов, выявления семантических компонентов слова и их веса, для вскрытия системности лексики с семантической точки зрения
Понятие дистрибуции как совокупности сочетаний может использоваться в качестве показателя многозначности слова в синтагматическом плане языка: чем шире лексическая сочетаемость слова, тем многозначнее оно, тем шире его значением Причем одно и то же слово, употребляемое в качестве термина в научной литературе и в качестве нетермина в художественной литературе, обладает в этом случае достаточно четкими дистрибутивными различиями. Так, на 1000 сочетаний со словом земля в русских поэтических текстах зафиксировано 700 разных слов, тогда как в сочетании с этим же словом в научных текстах (работы по астрономии) зарегистрировано всего 275 разных слов. Дистрибу-
198
ция здесь служит диагностирующим показателем терминологического и нетерминологического использования слова..
Чаще всего посредством дистрибутивного метода исследуются семантические отношения между грамматически однородными словами, однако представляется вполне правомерным, через учет дистрибуции изучать характер и силу семантических связей между словами разных частей речи. Обычно, чем чаще сочетаются данные слова и чем ближе они находятся друг к другу в тексте, тем сильнее между ними семантическая связь. Например, фразеологически связанное слово тришкин, тормашками, зги и т. п.) в тексте всегда сочетается лишь с определенным другим словом, располагающимся рядом с ним, тогда как при свободной сочетаемости выбор слов широк и между уже выбранными сочетающимися лексическими единицами может располагаться целый ряд других слов. Иначе говоря, семантическое единство фразеологизма проявляется такими внешними дистрибутивными показателями, как избирательная сочетаемость и регулярная совместная встречаемость слов, образующих фразеологизм.
Таким образом, с помощью дистрибуции значение слова как бы выводится наружу, за пределы слова, и тем самым поддается наблюдению, исследованию и познанию различными разновидностями рассматриваемого метода.