

4Данные и взаимосвязи.
Мы начинаем рассмотрение структуры базы данных с построения простой модели взаимосвязи объектов. В самых общих чертах такое моделирование (иногда называемое объектным моделированием) подразумевает определение:
Объектов, информация о которых будет содержаться в базе данных
Свойств этих объектов
Взаимосвязей между ними
4.1Объекты.
Сначала рассмотрим объекты, на основе которых будет построена наша база данных. Без учета финансовой информации список объектов будет выглядеть так:
Клиенты, с которыми мы имеем дело
Документы, в которых числятся данные о клиентах и их товарах
Склады, в которых располагаются товары
Каждый пункт в этом списке описывает объект, существующий независимо от других объектов в мире нашей базы. Каждый такой объект представляется отдельной таблицей. (Ряд других объектов также представлен в этой базе данных отдельными таблицами, но пока не будем забегать вперед).
Каждый из этих объектов обладает собственными свойствами, которые также записаны в базе данных. Среди них:
Название (имя) клиента
Реквизиты клиента
Реквизиты банка
Тип документа
Город, в котором расположен клиент
Название материальной ценности (товара)
Цена товара
Группа, в которую входит материальная ценность.
Каждый пункт этого списка описывает отдельное свойство или атрибут рассматриваемого объекта («клиент», «документ», «город» или «склад») и является потенциальным столбцом в базе данных. Названия столбцов должны быть предельно ясными (назначение столбца должно быть понятно из названия) и кратким (чтобы упростить ввод названий и уменьшить их ширину).
Создание списка объектов и их свойств должно помочь вам решить, какие таблицы и столбцы нужно включить в базу данных.
В результате вы можете получить, например, следующий макет базы:
Т

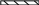

 аблица
Документ
аблица
Документ
Код дата номер Idn_клиента Idn_склада
Таблица Клиент
I dn
Idn_города
название(имя) реквизиты Idn_банка
dn
Idn_города
название(имя) реквизиты Idn_банка
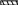
Таблица Склад
I
 dn
Idn_мат.отв
реквизиты название
dn
Idn_мат.отв
реквизиты название
Таблица Перемещение
I dn
порядков№ код_док дата_док номер_док
Idn_группы
Idn_мат.цен
кол-во цена
dn
порядков№ код_док дата_док номер_док
Idn_группы
Idn_мат.цен
кол-во цена
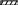
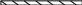
Таблица Остатки
I
 dn
Idn_группы
Idn_мат.цен
кол-во
цена Idn_склада
Idn_перемещения
dn
Idn_группы
Idn_мат.цен
кол-во
цена Idn_склада
Idn_перемещения
Т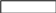 аблица
Города Таблица
Группы Таблица
Банки
аблица
Города Таблица
Группы Таблица
Банки
I
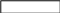
 dn
название Idn
название Idn
реквизиты
dn
название Idn
название Idn
реквизиты
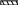
Т
 аблица
Мат.
ценности Таблица
Типы_документо
аблица
Мат.
ценности Таблица
Типы_документо
I dn_группы
Idn_мат.цен
название код название вид
dn_группы
Idn_мат.цен
название код название вид
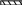
Чтобы избежать повторения столбцов, мы используем ядро базы (главную таблицу) и справочник (вспомогательную таблицу, которая поддерживает информацию по отдельным позициям). (Подробнее см. нормализация данных).
В вышеприведенной базе данных ядром являются таблицы Документ, Перемещение и Остатки. К справочным таблицам относят все остальные (выделенные жирным шрифтом с подчеркиванием).
Одна из задач проектирования базы данных состоит в обеспечении способа идентификации различных объектов. Другими словами, система должна уметь отличать друг от друга отдельные строки и таблицы. Строки можно различать по значению первичного ключа таблицы. Неформально, первичный ключ- это столбец, однозначно определяющий строку.