

Код Шеннона-Фано
Основные этапы
Символы первичного алфавита m1 выписывают в порядке убывания вероятностей.
Символы полученного алфавита делят на две части, суммарные вероятности символов которых максимально близки друг другу.
В префиксном коде для первой части алфавита присваивается двоичная цифра «0», второй части — «1».
Полученные части рекурсивно делятся и их частям назначаются соответствующие двоичные цифры в префиксном коде.
Когда
размер под алфавита становится равен
нулю или единице, то дальнейшего удлинения
префиксного кода для соответствующих
ему символов первичного алфавита не
происходит, таким образом, алгоритм
присваивает различным символам префиксные
коды разной длины. На шаге деления
алфавита существует неоднозначность,
так как разность суммарных
вероятностей ![]() может
быть одинакова для двух вариантов
разделения (учитывая, что все символы
первичного алфавита имеют вероятность
больше нуля).
может
быть одинакова для двух вариантов
разделения (учитывая, что все символы
первичного алфавита имеют вероятность
больше нуля).
Алгоритм вычисления кодов
Код Шеннона — Фано строится с помощью дерева. Построение этого дерева начинается от корня. Всё множество кодируемых элементов соответствует корню дерева (вершине первого уровня). Оно разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Эти подмножества соответствуют двум вершинам второго уровня, которые соединяются с корнем. Далее каждое из этих подмножеств разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Им соответствуют вершины третьего уровня. Если подмножество содержит единственный элемент, то ему соответствует концевая вершина кодового дерева; такое подмножество разбиению не подлежит. Подобным образом поступаем до тех пор, пока не получим все концевые вершины. Ветви кодового дерева размечаем символами 1 и 0, как в случае кода Хаффмана.
При построении кода Шеннона — Фано разбиение множества элементов может быть произведено, вообще говоря, несколькими способами. Выбор разбиения на уровне n может ухудшить варианты разбиения на следующем уровне (n + 1) и привести к неоптимальности кода в целом. Другими словами, оптимальное поведение на каждом шаге пути ещё не гарантирует оптимальности всей совокупности действий. Поэтому код Шеннона — Фано не является оптимальным в общем смысле, хотя и дает оптимальные результаты при некоторых распределениях вероятностей. Для одного и того же распределения вероятностей можно построить, вообще говоря, несколько кодов Шеннона — Фано, и все они могут дать различные результаты. Если построить все возможные коды Шеннона — Фано для данного распределения вероятностей, то среди них будут находиться и все коды Хаффмана, то есть оптимальные коды.
Пример кодового дерева
Исходные символы:
A (частота встречаемости 50)
B (частота встречаемости 39)
C (частота встречаемости 18)
D (частота встречаемости 49)
E (частота встречаемости 35)
F (частота встречаемости 24)
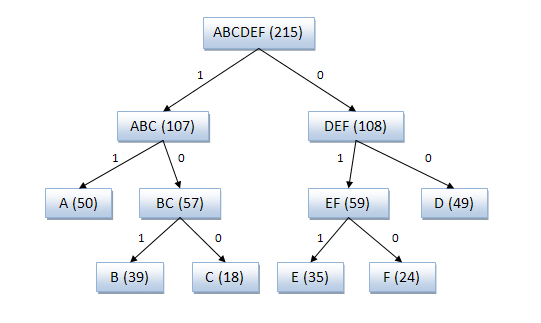
Кодовое дерево
Полученный код: A — 11, B — 101, C — 100, D — 00, E — 011, F — 010.
Код Хаффмана
Определение 1: Пусть A={a1,a2,...,an} - алфавит из n различных символов, W={w1,w2,...,wn} - соответствующий ему набор положительных целых весов. Тогда набор бинарных кодов C={c1,c2,...,cn}, такой что:
(1) ci не является префиксом для cj, при i≠j
(2) ![]() минимальна
(|ci|
длина кода ci)
минимальна
(|ci|
длина кода ci)
Называетсяминимально-избыточным префиксным кодом или иначе кодом Хаффмана.
Замечания:
Свойство (1) называется свойством префиксности. Оно позволяет однозначно декодировать коды переменной длины.
Сумму в свойстве (2) можно трактовать как размер закодированных данных в битах. На практике это очень удобно, т.к. позволяет оценить степень сжатия не прибегая непосредственно к кодированию.
В дальнейшем, чтобы избежать недоразумений, под кодом будем понимать битовую строку определенной длины, а под минимально-избыточным кодом или кодом Хаффмана - множество кодов (битовых строк), соответствующих определенным символам и обладающих определенными свойствами.
Известно, что любому бинарному префиксному коду соответствует определенное бинарное дерево.
Определение 2: Бинарное дерево, соответствующее коду Хаффмана, будем называть деревом Хаффмана.
Задача построения кода Хаффмана равносильна задаче построения соответствующего ему дерева. Приведем общую схему построения дерева Хаффмана:
буквы располагают в порядке убывания их вероятностей. Складывают вероятности двух последних букв, и ряд переписывают снова с учетом новой вероятности (суммы). Далее повторяют операцию, пока не получится 1. Нижнюю букву всегда кодируют нулем, а верхнюю – единицей.
Для составления кодовых комбинаций строится кодовое дерево. Двигаясь по кодовому дереву сверху вниз, можно записать для каждой буквы соответствующую ей кодовую комбинацию.
Код Хаффмана, также как и Шеннона-Фано является префиксным, то есть в таком коде ни одна комбинация не совпадает с началом более длинной комбинации, а это позволяет обеспечить однозначное декодирование без введения разделительных символов.
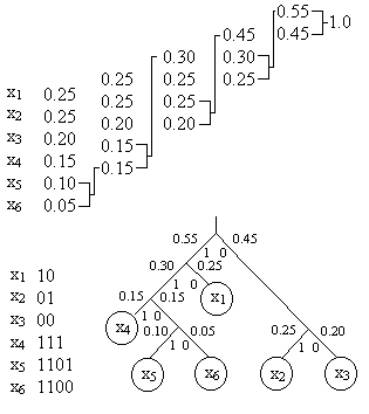
Среднее кол-во разрядов:
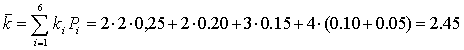
Энтропия
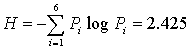
![]()
Как мы видим, величина среднего кол-ва разрядов получилась достаточно близкой к энтропии, следовательно, код можно считать эффективным. При этом для сравнения можно вычислить величину K для равномерного кода:
![]()
ЗАДАЧА.
Пусть имеется случайная величина X(x1,x2,x3,x4,x5,x6,x7,x8), имеющая восемь состояний с распределением вероятностей
Закодировать буквы (x1,x2,x3,x4,x5,x6,x7,x8) в коде Шеннона-Фано.
Все буквы записываются в порядке убывания их вероятностей, затем делятся на равновероятные группы, которые обозначаются 0 и 1, затем вновь делятся на равновероятные группы и т.д.
ЗАДАЧА
построить дерево Хаффмана для сообщения S="AHFBHCEHEHCEAHDCEEHHHCHHHDEGHGGEHCHH".
УКАЗАНИЕ: в нашем случае A={A, B, C, D, E, F, G, H}, W={2, 1, 5, 2, 7, 1, 3, 15}.
ЗАДАЧА
Пусть имеется следующая таблица префиксных кодов:
а |
л |
м |
р |
у |
ы |
10 |
010 |
00 |
11 |
0110 |
0111 |
Требуется декодировать сообщение: 00100010000111010101110000110
УКАЗАНИЕ: Декодирование производится циклическим повторением следующих действий:
отрезать от текущего сообщения крайний левый символ, присоединить к рабочему кодовому слову;
сравнить рабочее кодовое слово с кодовой таблицей; если совпадения нет, перейти к (1);
декодировать рабочее кодовое слово, очистить его;
проверить, имеются ли еще знаки в сообщении; если «да», перейти к (1).
ЗАДАЧА
Пусть имеется первичный алфавит A, состоящий из шести знаков a1 …a6 с вероятностями появления в сообщении, соответственно, 0,3; 0,2; 0,2; 0,15; 0,1; 0,05.
Построить код Хаффмана
ЗАДАЧА
Закодируйте двоичным кодом Шеннона-Фано ансамбль сообщений Х = х1, х2, ..., х8, если все кодируемые сообщения равновероятны. Показать оптимальный характер полученного кода.
ЗАДАЧА
Определите количество элементов в кодовом слове, если известно общее число комбинаций N = 512, а основание кода 2.
ЗАДАЧА
Сколько двоичных чисел может быть представлено 7-разрядным кодом?
ЗАДАЧА
Дана совокупность символов х1, х2, х3, х4 со следующей статистикой соответственно: 0,28; 0,14; 0,48; 0,10. Закодируйте символы по методу Шеннона-Фано и определите эффективность кода.