

Работа с системой PolyAnalyst
При запуске PolyAnalyst (в списке «Все программы» PolyAnalyst Pro) появляется основное окно программы, которое представляет собой удобную объектно-ориентированную среду аналитика, называемую Рабочим местом (рис.39).

Рисунок 203
Вся информация здесь представляется пользователю в виде объектов пяти классов: таблицы, графики, правила, отчеты и процессы. Для хранения каждого класса объектов служит отдельный контейнер, которые именуются соответственно классу объекта.
Объекты представляются на Рабочем месте в виде пиктограмм. С объектами можно производить разнообразные действия: создавать и удалять, выбирать, редактировать, открывать для просмотра в виде таблиц, правил и графиков. Некоторые объекты можно применять к другим объектам, что приводит к модификации последних. Так объект “правило” можно применить к объекту “таблица”. В результате этой операции будут рассчитаны значения нового атрибута в таблице данных.
Когда информация изменяется в одном объекте, все логически связанные с ним объекты перестраиваются автоматически.
Что представляют собой объекты:
Таблицы - Объекты, содержащие данные.
Графики - Объекты, содержащие графики. Существует несколько типов графиков: это гистограммы распределения, двумерные “x-y” графики и трехмерные графики, в которых третье измерение кодируется цветовой гаммой. Кроме этих графиков существует возможность создавать графики правил и объединять эти графики с графиками данных.
Правила - Объекты этого класса содержат “фрагменты знаний” автоматически обнаруженных вычислительными процессами программы PolyAnalyst или гипотезы, сформулированные самим пользователем.
Отчеты - Объекты, содержащие промежуточные или окончательные результаты исследования, полученные машинами исследований.
Процессы - Объекты этого класса предназначены для индикации активных процессов и означают, что один или несколько вычислительных процессов запущены и выполняют автоматическую обработку данных.
Объекты могут создаваться автоматически вычислительными процессами или вручную самим пользователем. Каждый объект имеет свое имя и пиктограмму. PolyAnalyst автоматически присваивает имена, которые пользователь может редактировать по собственному усмотрению. Существуют следующие два общих правила именования объектов:
1. Имя может содержать любой ASCII символ, но не может быть пустым.
2. Внутри каждого класса имя объекта должно быть уникальным.
При автоматическом именовании объектов имена содержат префикс, соответствующий имени процесса, создавшего объект. Данное правило иллюстрируется следующей таблицей:
Исследование |
Таблицы |
Правила |
Отчеты |
ЛинейнаяРегрессия |
|
LR_target |
LR_target |
ПоискЗависимостей |
FD_target |
FD_target |
FD_target |
PolyNet Predictor |
PN_target |
PN_target |
PN_target |
Поиск Законов |
|
FL_target |
FL_target |
Дискриминация |
|
DS_target |
DS_target |
Кластеризация |
FC_name_cluster |
|
FC_name |
Классификация |
|
CL_target |
CL_target |
В этой таблице target означает имя целевой переменной, cluster означает номер кластера, а name - имя таблицы.
Процесс FL наряду с основным правилом создает также дополнительное правило - FL_target_EX, которое является более точным по сравнению с основным, но не обязательно значимым.
Объектам, создаваемым вручную, PolyAnalyst автоматически присваивает имена в соответствии с их классом и типом (n - порядковый номер):
Классы объектов |
Имена |
Таблицы |
Табл_n |
Таблицы, создаваемые операцией разбиения |
Атрибут_n |
Графики |
График_n |
Правила |
Правило_n |
Имена объектов можно редактировать. При этом необходимо соблюдать только два основных правила именования объектов, указанных выше.
Корневая таблица всегда по умолчанию именуется World. Этот объект создается при импорте новых данных в PolyAnalyst, и содержит все данные, которые будут анализироваться. Все другие таблицы, создаваемые в процессе работы, являются лишь подмножеством таблицы World. Можно изменить его имя (хотя это не рекомендуется), но нельзя удалить эту таблицу.
Панель управления расположена в верхней части главного окна PolyAnalyst и предоставляет быстрый доступ к различным функциям программы (рис. 40):


Рисунок 204
Наряду с уникальными именами объекты одного класса имеют пиктограммы определенного вида (рис. 41):

Рисунок 205
Источниками данных для PolyAnalyst являются прямоугольные таблице (строка в таблице соответствует одной записи, а столбцы таблиц содержат значения атрибутов базы данных), представленные в одном их следующих стандартных форматов:
CSV (разделитель запятая) форма
DBF (dBASE II, III, IV ) формат
Файлы Microsoft Excel (начиная с версии 7.0)
Внешние, SQL-совместимые источники данных
Эти форматы поддерживаются абсолютным большинством СУБД и электронных таблиц.
CSV файл - это текстовый файл, в котором записи представлены строками, а значения различных атрибутов - числами, разделенными запятыми.. Первая строка файла может также хранить имена атрибутов. Если строка атрибутов отсутствует, PolyAnalyst именует атрибуты автоматически в соответствии со следующим образцом: имяфайла_n, где n - порядковый номер атрибута.
Пример CSV-файла:
age, sex, ID
68,0,334566
54,1,123456
При открытии файла данных PolyAnalyst создает новый проект, состоящий из одного объекта - таблицы World.
Таблица - это объект данных, с которым работают вычислительные процессы. Таблица состоит из строк (записей) и столбцов (атрибутов). Каждый атрибут имеет свое имя. Первый столбец таблицы называется счетчиком записей. Все записи обладают одним и тем же количеством атрибутов, хотя значения некоторых атрибутов могут быть пропущены.
В проекте всегда присутствует таблица World - объект, хранящий все данные, которые Вы можете исследовать. Эта таблица создается при создании нового проекта из исходных данных.
Атрибут - это уникальное имя поля таблицы данных. Так как PolyAnalyst работает с прямоугольными таблицами, атрибут также является и названием столбца.
Каждый атрибут, правило или константа принадлежит определенному типу. Все значения этого атрибута должны принадлежать к одному типу. Каждая функция (и операция) принимают параметры определенных типов, зависящих от функции (или операции). Тип результата функции (или операции) также строго задан. Таким образом, любое выражение принадлежит к определенному типу, и это тип результата этого выражения.
Значения каждого атрибута принадлежат одному, определенному, типу. В PolyAnalyst определены следующие типы данных целый, число, да/нет и категория (перечислимый). Перечислимый тип используется в случаях, когда необходимо описать элементы множества, несравнимые друг с другом, например: 1 - красный, 2 - зеленый, 3 - синий. Кроме того, поддерживается также тип дата и текстовый категориальный тип, значения которого представляются не числами, а текстом (“красный”, “синий”, “зеленый).
Тип дата поддерживается только при создании проекта, в последствии все значения этого типа переводятся в количество дней, начиная с минимальной даты в исходных данных.
Тип данных может быть назначен атрибуту только при создании или редактировании проекта. PolyAnalyst всегда проверяет, можно ли назначить новый тип выбранному атрибут (нельзя назначить целый тип атрибуту, содержащему дробные числа).
Можно создавать новые таблицы - как из World, так и из других, уже созданных таблиц. PolyAnalyst предоставляет различные функции манипулирования с таблицами: логические операции, такие как объединение, пересечение и дополнение; разбивка по критерию, ручной выбор прямо из графиков. Вычислительный процесс Поиск Зависимостей автоматически создает таблицу как один из результатов своей работы. Во всех случаях, независимо от способа создания новой таблицы она всегда является подмножеством таблицы World.
Новый проект может быть создан также и из нескольких исходных файлов, при помощи установления связей между ними.
Целевой атрибут - это атрибут, в отношении которого PolyAnalyst проводит исследование. Находить зависимости целевого атрибута от остальных и является главной задачей PolyAnalyst. Только один атрибут проекта может быть выделен в исследовании как целевой.
Логические (да/нет) и перечислимые атрибуты не могут быть выбраны в качестве целевых (исключение составляет метод Классификация). Для проведения исследования в отношении логического или перечислимого атрибута необходимо сменить их тип на целый.
Исследования Дискриминация и Кластеризация не требуют целевого атрибута в качестве параметра.
Вычислительные процессы создают во время своей работы правила. Пользователь может также создавать новые правила или изменять существующие. Для этого в PolyAnalyst встроен так называемый Язык Символьных Правил (Symbolic Rule Language, SRL). Правила могут быть применены к таблицам и как результат этого применения у таблиц появляются новые атрибуты - атрибуты-правила. Значения этих новых атрибутов меняются автоматически при изменении правил, которые их создали.
Фрагменты знаний, найденные вычислительными процессами PolyAnalyst или сформулированные самим пользователем, хранятся в виде объектов - правил.
PolyAnalyst различает два, принципиально различных, видов правил - символьные правила, т.е. выраженные на так называемом Языке Символьных Правил (Symbolic Rule Language, SRL), и правила, которые нельзя представить в текстовом виде, созданные вычислительными процессами ARNAVAC (Поиск Зависимостей) и PolyNet Predictor.
Символьное правило на Языке Символьных Правил - это алгебраическое выражение, которое может быть рассмотрено как последовательность элементов 4 типов (имена, константы, функции, операции). Для вещественных и целых типов SRL не делает различия.
Имя (атрибута или правила) может состоять из следующих символов:
Прописные и строчные буквы английского алфавита. Прописные и строчные буквы воспринимаются как различные символы
Цифры от 0 до 9
Специальные символы: @, $, _
Имя не может начинаться с цифры. Любая последовательность символов, заключенных в кавычки, также является корректным именем. Значимая длина имени 40 символов. Это означает, что имена сравниваются только по первым 40 символам.
Примеры правильных имен (Name1, name1, @_field_1, n12$345P, "4segment").
Примеры неправильных имен (4segment, non-crit)
Константы - это числа с плавающей точкой, или записанные в экспоненциальном формате (1, -0.78, +4.0, 123.67e+3). Категориальные константы заключаются в одинарные кавычки и предваряются именем атрибута, к которому они принадлежат, например: ‘origin:USA’. Если категориальная константа не текстовая, а закодирована числом, то она предваряется символом ~, например: ~7.
В SRL можно использовать функции. Вызов функции выглядит следующим образом (общие правила совпадают с использованием функций в Visual Basic, Excel):
<имя функции> ( <параметр 1>, < параметр 2>, ...)
Имена, константы, могут быть использованы в качестве аргументов функции (<параметр 1>, < параметр 2>) если они отвечают соглашениям о типах.
Ниже приведен пример использования функций if (если):
if (p1, p2, p3) p1 -логический; p2 и p3 произвольный, но одинаковый. если значение p1 = ‘Да’, то результат p2; иначе - p3.
Список доступных функций можно найти в справочной системе PolyAnalyst.
Все операции в SRL делятся на три группы: префиксные, бинарные и 'shift' (сдвиг).
Префиксные операции имеют следующий формат: <знак операции> <выражение>. Таких операций три: +, -, not (отрицание). Пример: - p меняет знак p.
Бинарные операции поделены на три группы (Арифметические, Операции отношения и Логические) и имеют следующий формат:
<выражение1> <знак операции> <выражение2>
Арифметические: +, - , *, / , % (остаток от деления).
Операции отношения и логические операции возвращают логические значения "Да" или "Нет".
Операции отношения: <, <= , >, >=, = , != (не равно).
Аргументы операций отношения должны быть числового типа, но для операций "=" и "!=" допускаются и перечислимые. Во всех случаях тип обоих аргументов должен совпадать.
Логические: and, or, xor (Исключающее ИЛИ)
Операция 'shift' (сдвиг) возвращает значение атрибута p1 из записи, номер которой сдвинут на p2 и имеет следующий синтаксис:
<атрибут или правило> [ <выражение> ]
или
<выражение> [ <выражение> ]
p1 [ p2 ], где p1 произвольного типа, а p2 – числовой.
Приоритеты операций аналогичны Visual Basic, Excel.
Правила, созданные процессом Поиск Зависимостей представляют собой многомерную таблицу предсказания, в которой каждой клетке сопоставляется результат правила. Такие правила называется табличными.
Правила, созданные процессом PolyNet Predictor представляют собой сложные нейронные сети и никак не могут быть представлены для пользователя. Тем не менее, небольшие PolyNet - правила могут быть представлены в виде сложного полинома.
Символьные правила создаются вычислительными процессами Линейной Регрессии, Core PolyAnalyst (Поиск Законов), Классификацией и Дискриминацией, также, они могут быть созданы самим пользователем. Символьные правила можно редактировать, в то время как остальные - нельзя.
Сразу после создания правило становится автономным объектом, содержащим частицу знания. Затем правило можно применять к различным таблицам (в результате этого применения у таблицы появляется т.н. атрибут-правило). Кроме этого, каждое созданное правило автоматически применяется к таблице World. Правила могут быть использованы для создания других правил и для последующего исследования. Правила можно визуализировать на двухмерных графиках.
Все правила представляются различными пиктограммами. При создании символьного правила ему нужно дать имя. Вычислительные процессы именуют свои результаты-правила автоматически, приписывая две первые буквы - аббревиатуру процесса - к имени исследуемой таблицы:
LR - Линейная Регрессия
FD - Поиск Зависимостей
FL- Поиск Законов
PN- PolyNet Predictor
CL- Классификация
DS - Дискриминация
Вычислительный процесс Поиск Законов (Core PolyAnalyst) может создавать два правила: наиболее значимое и наиболее точное, к имени которого добавляется окончание “_EX”.
Внимание! При автоматическом создании имен по умолчанию, созданные ранее результаты с таким же именем уничтожаются. Что бы сохранить созданные ранее результаты, задавайте новые имена.
Рассмотрим работу системы PolyAnalyst на конкретном примере. В примерах системы имеется набор файлов данных. Откроем проект из файла (рис. 42) и выберем файл Autompg.csv (рис. 43).

Рисунок 42

Рисунок 43
Этот файл содержит информацию по 400 автомобилям (средний пробег в милях, соответствующий расходу 1 галлона топлива - mpg, количество цилиндров у каждого автомобиля - cyl, объем цилиндра в кубических дюймах -displ, мощность в лошадиных силах - power, вес - weight, время разгона до скорости 100 миль в час - accel, год выпуска -Year, место выпуска - origin и модель - model). mpg - это величина, обратная расходу топлива. Каждая строчка соответствует одному автомобилю. Поля origin и model содержат категориальные (текстовые) значения.
В окне (рис. 44) зададим имя проекта и изменим тип данных (рис. 45). Изменим типы некоторых полей (рассматриваются по умолчанию как действительные числа). Например, поле cyl содержит целые числа. Для того чтобы установить его тип щелкните по нему мышью и нажмите кнопку Тип поля. Выберите в появившемся списке тип целое и нажмите OK.

Рисунок 44

Рисунок 45
То же самое задайте для поля Year.
Установите флажок на поле «Включить номер записи» - это нужно для того чтобы идентифицировать различные автомобили по соответствующему номеру записи. После этого нажмите кнопку OK и сохраните проект под именем AUTOMPG1.PRJ.
В списке таблиц появилась таблица World (рис. 46), состоящая из указанных выше полей (рис. 47).

Рисунок 46

Рисунок 47
Перед проведением исследования данных преобразуем таблицу. Вместо поля Year (года производства автомобиля) введем возраст автомобиля (age). Поскольку эти данные начинаются с 1982 году, выражение для нового параметра age будет age = 82 - Year.
В системе PolyAnalyst производные параметры определяются правилами их вычисления. Вызываем диалог создания нового правила или пиктограмму f(x), рис. 48.

Рисунок 48
В открывшемся окне вводим имя нового производного параметра - age. В поле Текст правила вводим выражение 82 - Year. Year вводим двойным щелчком по имени атрибута. Нажимаем ОК (рис.49 ).

Рисунок 49
В контейнере правил появляется новая пиктограмма, обозначающую новый производный параметр (рис. 50).

Рисунок 50
Для того чтобы вычислить его значение для всех записей выберем мышью пиктограмму таблицы World, затем нажав правую кнопку мыши на пиктограмме age вызовем присоединенное к ней меню. Выберем в нем пункт «Применить к выделенным таблицам», рис. 51.

Рисунок 51
На открывшейся таблице видны значения этого параметра (последний столбец, рис. 52).

Рисунок 52
Создадим новую таблицу в которую входил бы только age (для этой таблицы будут далее запускаться разные методы исследования).
Для этого на окне таблицы World в контекстном меню выбрать «Создать новую» (рис. 53).

Рисунок 53
Появился диалог создания новой таблицы (рис. 54).

Рисунок 54
Введем имя новой таблицы в поле Имя (АнализАвтоВозр). Щелкнув правой кнопкой мыши на поле Year, исключим это поле из новой таблицы. Нажмем на ОК .
В списке таблиц появилась новая таблица (рис. 55). Поля таблицы показаны на рис. 56.

Рисунок 2065

Рисунок 56
Первым проведем исследование зависимости расхода топлива (целевой атрибут mpg) от остальных полей с помощью многопараметрической линейной регрессии.
Вызовем контекстное меню пиктограммы таблицы «АнализАвтоВозр» и выберем в нем Исследовать/Линейная Регрессия (рис. 57). В открывшемся диалоге двойным щелчком мыши обозначим целевой параметр - mpg - он выделится красным. Исключим поле RecNo (щелчок правой кнопкой мыши, выделяется белым), рис. 58. Нажимаем ОК.

Рисунок 57

Рисунок 58
В контейнере процессов появляется пиктограмма обозначающая запущенный процесс исследования.
Через некоторое время исследование заканчивается (приходит сообщение об его нормальном завершении, рис. 59).

Рисунок 59
Отчет о полученном результате представляется в разных окнах. Первое окно содержит текстовую информацию о результатах исследования (рис. 60).

Рисунок 60
Это линейная формула, выражающая найденную зависимость mpg (целевой параметр) от других параметров. В формулу входят наиболее влияющие параметры. Два параметра (ускорение и модель автомобиля) не входят (не влияют). Знаки перед соответствующими членами этого выражения говорят о направлении этого влияния.
Обратите внимание, что в полученную линейную формулу входит функция if для оценки влияния страны выпуска.
Кроме того, приводятся статистические характеристики полученной зависимости (стандартное отклонение, стандартная ошибка, число обработанных точек, индекс значимости).
Стандартное отклонение

где pi (1<=i <=N ) значение зависимой переменной для i-ой записи, Pi значение этой же переменной, предсказанное данной регрессионной моделью, N - число исходных данных.
Стандартная ошибка

где pi (1<=i <=N ) значение зависимой переменной для i-ой записи, Pi значение этой же переменной, предсказанное данной регрессионной моделью, N - число исходных данных, δ - квадрат дисперсии значений pi. Или стандартная ошибка - это стандартное отклонение, деленное на дисперсию.
Критическое значение F-Ratio (большее или равное 0). Выполняя процесс линейной регрессии, PolyAnalyst тестирует различные линейно-регрессионные модели, включающие в себя различные комбинации независимых переменных. Для каждой модели определяются значения ее регрессионных коэффициентов и их стандартных отклонений. Величина F-ratio для множителя из регрессионной модели определяется как квадрат частного от деления модуля соответствующего регрессионного коэффициента на величину его стандартного отклонения. Если регрессионная модель содержит F-ratio меньший, чем критическое значение (critical F-ratio value), то эта модель отвергается. Значение critical F-ratio value задается по умолчанию или пользователем при старте процесса.
Минимальный процент предсказанных значений. В случае, когда регрессионная модель включает независимые переменные с частично пропущенными значениями, она может предсказывать значение зависимой переменной только для некоторого подмножества записей из исследуемой таблицы. Если для такой регрессионной модели процент присутствующих в таблице записей меньше, чем заданный минимум, то данная регрессионная модель отвергается.
Индекс значимости характеризует значимость построенной регрессионной модели. Для вычисления индекса значимости сравнивается стандартное отклонение результата, полученного на реальных данных со стандартным отклонением результата, полученного для искусственно созданных данных, в которых значение целевой переменной для разных записей случайным образом перемешано.
Если стандартное отклонение, полученное на реальных данных (Sreal) приблизительно равно стандартному отклонению случайных данных (Srand), то индекс значимости близок к нулю, то есть результат исследования не может рассматриваться как значимый. Если Sreal много меньше, чем Srand для всех случайно сгенерированных таблиц, то индекс значимости намного больше 1.0 . В этом случае результат исследования может быть назван значимым. На практике имеет смысл называть значимыми только те модели, у которых индекс значимости больше 3.0.
Стандартная ошибка построенного эмпирического закона довольно велика - им не объясняется 41.97% вариации параметра mpg. По этому закону может быть посчитано 392 записи таблицы «АнализАвтоВозр». Найденная зависимость является статистически значимой - ее индекс значимости составляет 142 (очень большой).
Относительную силу и значимость параметров, включенных в найденную зависимость, показывает таблица, помещенная на отчете ниже.
Информацию об относительной значимости разных факторов можно сделать более наглядной. Для этого необходимо выбрать «Относительный вклад факторов» из контекстного меню отчета LR_mpg (рис. 61). Появится график (рис. 62).

Рисунок 61

Рисунок 62
На графике видно, что наиболее значимыми параметрами являются количество цилиндров (cyl) и возраст автомобиля (Age).
Выберем также из контекстного меню отчета LR_mpg «Предсказание от реальных». Появится график (рис. 63), показывающий как соотносятся реальные значения mpg и предсказанные по найденной линейной формуле. Видно, что точки на этом графике не равномерно лежат вокруг диагонали, соответствующей абсолютно точному предсказанию - видно, что предсказания с левого и правого краев графика занижены, а в середине - завышены. Это означает, что линейная модель плохо подходит в данном случае и для получения более точных зависимостей нужно использовать более мощные нелинейные методы.

Рисунок 63
Полученные результаты можно сохранить в виде отчета. Выберем пункт меню Создать Объект->Печатную форму (рис. 64)
Рисунок 64
В появившемся окне (рис. 65 ) можно заполнить поля Имя, Заголовок страницы и Подзаголовок и др. Далее OK.

Рисунок 65
Появится пустая печатная форма (рис. 66). Ее можно отодвинуть в сторону.

Рисунок 66
Используя всплывающее меню отчета LR_mpg откроем последовательно окна Текстовый отчет, Предсказанные от реальных, Невязки. В каждом из них нажмем кнопку «На печать». Теперь окно печатной формы имеет вид на рис. 67.

Рисунок 67
При помощи мыши расставим все прямоугольники и изменим их размеры (рис. 68). Нажмем кнопку Просмотр и увидим отчет таким, каким он будет напечатан на принтере (рис. 69).

Рисунок 68
Рисунок 69
Продолжим исследование данных примера. Будем использовать «Поиск Зависимостей», внутри которого имеются «мягкий» и «жесткий» алгоритмы. «Мягкий» алгоритм позволяет обнаруживать нечеткие и слабые функциональные зависимости, а «Жесткий» ищет компактные и сильно связанные области в данных.
Реально встречающиеся на практике данные состоят из «хороших» записей, подчиняющихся каким-то четким закономерностям и достоверных, и «плохих» (ошибки, исключения, какие-то аномальные случаи и т.п.). Такие аномальные записи необходимо выделить по двум причинам. Во-первых, они мешают находить точные зависимости и поэтому их необходимо исключить из исследования. Во-вторых, такие записи могут быть интересны сами по себе, поскольку они могут представлять собой какие-то отличительные закономерности.
Для поиска аномалий в данных используется «Поиск Зависимостей», а внутри этого метода выбирается тип алгоритма «Мягкий» (этот тип алгоритма предназначен для поиска аномалий в данных).
Выделяем таблицу «АнализАвтоВозр» и в меню «Исследовать»-> «Поиск Зависимостей» (рис. 70). В диалоге запуска этого исследования (рис. 71) отметим двойным щелчком целевую переменную - mpg и исключим переменные RecNo и model (правая кнопка мыши). Тип алгоритма выберем «Мягкий». Запустим исследование, нажав на ОК.

Рисунок 70

Рисунок 71
После нормального завершения исследования в окне системы появились новые объекты (рис. 72) и отчеты (рис. 73, 74 и 75).

Рисунок 72

Рисунок 73

Рисунок 74

Рисунок 75
В отчете на рис. 73 содержится информация о найденной зависимости целевого атрибута mpg от параметров weight, accel и age (наиболее влияющие параметры) и указано, что «Количество точек, подчиняющихся найденной зависимости = 396».
Это означает, что из 398 записей исследованной таблицы 396 можно рассматривать как "нормальные", а 2 представляют собой сильные отклонения. На графике «Предсказанные от реальных» (рис. 74) можно увидеть, что 2 синие точки соответствуют 2 самым экономичным автомобилям (красные точки все остальные автомобили).
В отчете на рис. 73 также содержится трехмерная таблица (три наиболее влияющих параметра - weight, accel и age). Каждая ячейка таблицы соответствует автомобилям, имеющим то или иное соотношение между параметрами weight, accel и age. Например, все четыре ячейки таблицы соответствуют автомобилям с возрастом менее 7 лет.
Каждая ячейка таблицы содержит четыре числа. Нас будут интересовать второе и четвертое сверху числа. Это соответственно количество всех записей (автомобилей), попадающих в данную ячейку и количество "хороших" - не аномальных записей в этой ячейке. Мы видим, что у всех ячеек эти числа одинаковы, кроме верхней правой ячейки таблицы. Эта ячейка соответствует нестарым (age < 7), тяжелым (weight > = 2807) и быстро разгоняющимся ( accel < 15.5) автомобилям. Определим, какие это отличающиеся автомобили.
В контейнере таблиц появилась пиктограмма новой таблицы с именем FD_mpg. Эта таблица автоматически создалась только что отработавшим методом «Поиск Зависимостей» и содержит все "хорошие" записи. Чтобы выделить все аномальные записи, надо применить к этой таблице операцию дополнения, вызвав ее контекстное меню и выбрав в нем пункт «Создать дополнение» (рис. 76).

Рисунок 76
При этом создастся новая таблица с автоматически генерируемым именем типа Табл_n (рис. 77).

Рисунок 77
Перед тем, как открыть эту таблицу, вызовем пункт ее контекстного меню «Изменить» и правым щелчком мыши включим параметр model (рис. 78).

Рисунок 78
Откроем таблицу и увидим, что эти аномальные данные (рис. 79).

Рисунок 79
Далее можно проводить анализ на очищенных данных, с использованием таблицы FD_mpg (в ней отсутствуют найденные аномалии). Эту таблицу можно переименовать.
Рассмотрим, что дает «Жесткий» алгоритм «Поиска зависимостей» (рис. 80 и 81) для таблицы FD_mpg. При запуске алгоритма выдается предупреждение, что все существующие объекты для этой таблицы FD_mpg будут удалены (рис. 82).

Рисунок 80

Рисунок 81
Рисунок 82
По окончании работы алгоритма получим текстовый отчет (рис. 83) и графики (рис. 84 и 85). Кроме текстовой информации о наиболее влияющем параметре (количество цилиндров – cyl) и оценки точности, приводится таблица со столбцом заголовков строк и 5 столбцами информации (3 выделены красным цветом, 2 – белым).
Как было сказано выше, «Жесткий» алгоритм ищет компактные и сильно связанные области в данных. Алгоритм выделил три подмножества данных, для которых наиболее соответствует полученная зависимость от количества цилиндров. Для количества цилиндров 4-5 полученная зависимость описывает 203 точки из 204 (очень хороший результат). Для двух других областей (6-8 цилиндров и более 8 цилиндров) результат хуже (63 из 82 точек и 78 из 103 соответственно). Это достаточно хорошо иллюстрируется на графике на рис. 84.

Рисунок 83

Рисунок 84
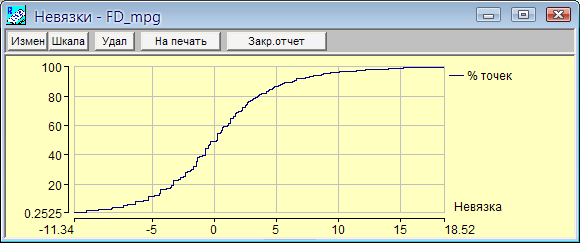
Рисунок 85
Используем метод «Поиск Законов» для получения более точной зависимости mpg от остальных параметров. Запустим метод исследования «Поиск Законов», выбрав в качестве целевого параметра mpg и исключив переменные RecNo и model (рис. 86 и 87).

Рисунок 86

Рисунок 87
Поставим ограничение по времени работы метода (поле Лимит времени), равное 5 минутам (чем больше время, тем лучше будет полученный результат).
В течение своей работы система извещает, что найдена новая, более точная модель, и посылает отчеты. По окончании работы выдается окно завершения.
Окно последнего отчета содержит общую информацию о найденной зависимости. Основная информация - это найденное системой выражение для зависимости параметра mpg от остальных параметров (рис. 88).

Рисунок 88
Система сама нашла это довольно сложное выражение для зависимости mpg от других параметров. Стандартная ошибка 32% - гораздо точнее, чем давала линейная модель.
Следует отметить, что рекомендуется использовать «Лучшее по значимости правило», а не правило «Лучшее по точности», так как последнее хотя и является более точным, может содержать в себе какие-то члены, не достаточно статистически обоснованные.
В принципе, проанализировав структуру этой формулы можно оценить характере совместного влияния всех этих факторов, однако это довольно сложно для полученной многомерной зависимости.
В системе PolyAnalyst имеются средства для графического представления многомерных нелинейных зависимостей. Создадим 2-D график для анализа полученной многомерной нелинейной зависимости (выберем создать 2-D график на панели инструментов). В появившемся окне на рис. 89 выберем для отображения по оси Х вес (weight) и добавим нужное правило (+ правило). Далее в окне (рис. 90) выберем полученное правило FL_mpg. Это правило появится в списке объектов (рис. 91). После ОК увидим график (рис. 92).

Рисунок 89

Рисунок 90

Рисунок 91
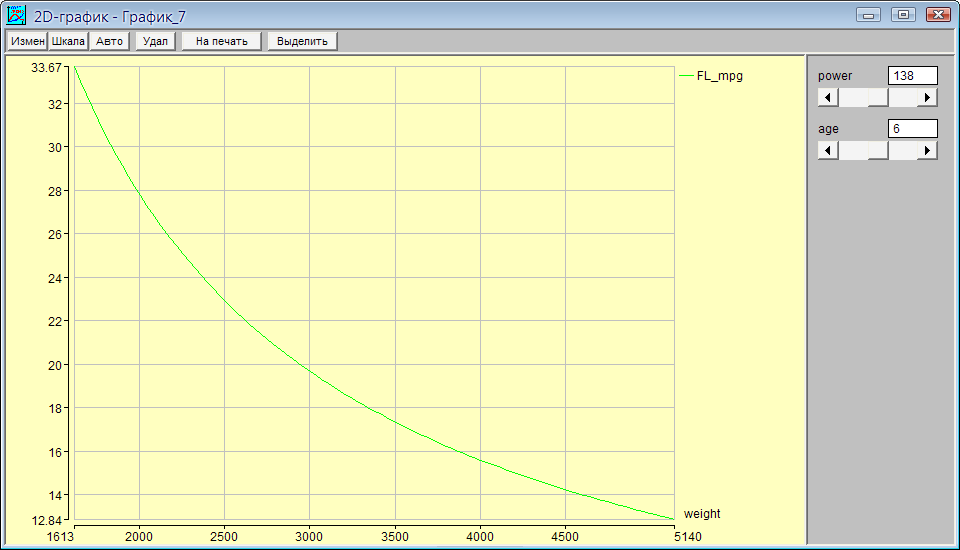
Рисунок 92
Изменяя значения других параметров найденной зависимости (power и age), можно трансформировать график (рис. 93). Построенные графики сохраняются в контейнере.

Рисунок 93
Рассмотрим работу «Кластеризация». Возьмем таблицу FD_mpg и запустим «Кластеризация» (рис. 94). При запуске кластеризации можно выбрать тип алгоритма: или «мягкий». «Жесткий» алгоритм ищет компактные и сильно связанные области в данных. Мягкий алгоритм позволяет обнаруживать нечеткие и слабые функциональные зависимости. Выберем модификацию алгоритма «жесткий» (рис. 95).

Рисунок 94

Рисунок 95
Результатом работы является отчет FC_FD_mpg и три новых таблицы FC_FD_mpg_1, FC_FD_mpg_2 и FC_FD_mpg_3. Открыв отчет (рис. 96), увидим, что система выделила три кластера. Параметры, дающие наилучшую кластеризацию displ и accel. В таблице кластеры выделены цветами (красный, синий и бледно голубой) и показаны параметры кластеров. В таблицах FC_FD_mpg_1, FC_FD_mpg_2 и FC_FD_mpg_3 представлены машины каждого из кластеров.

Рисунок 96
При выборе модификации алгоритма «мягкий» (рис. 97), результат получается другой. Система выделила два кластера (в таблице кластеры выделены красным и синим цветами, рис. 98), с другими параметрами, дающими наилучшую кластеризацию и в которые вошло больше точек.

Рисунок 97

Рисунок 98
Рассмотрим реализацию классификации. В системе PolyAnalyst классификацию реализуют исследования «Классификация» и «Дискриминация». Для использования «Классификации» в таблице данных необходимо наличие переменной, принимающей значение «Да/Нет» (принадлежность записи к классу). «Дискриминация» не требует наличия такой переменной. В таблицах исследуемых данных такой переменной нет и будем сначала использовать метод «Дискриминация».
Запустим метод «Дискриминация» для таблицы FC_FD_mpg_2 (данные этой таблицы принадлежат кластеру, выделенному мягким алгоритмом «Кластеризация»), рис. 99.

Рисунок 99
В окне запуска исследования имеется список для выбора типа процесса (рис. 100). Имеется три возможных типа: «Поиск законов», «Линейная регрессия» и «Polynet Predictor». Первые два реализуют рассмотренные выше методы классификации, а «Polynet Predictor» использует нейронные сети, которые рассматриваются в разделе «Нейронные сети» настоящего пособия.

Рисунок 100
При использовании «Линейная регрессия» нужно задать значения critical F-Ratio и критический процент пропущенных предсказываемых значений.
При использовании «Поиск Законов» нужно задать величину желаемой стандартной ошибки и ограничение по времени на исследование, в минутах. Процесс завершится при достижении такой стандартной ошибки или когда это время истечет.
Выберем «Линейная регрессия». После завершения исследования, в контейнерах появятся новые объекты. Если посмотреть отчет (рис. 101), то в нем приводится линейное предсказывающее выражение и его статистические характеристики. Появилось новое правило (рис. 102), совпадающее с предсказывающим выражением.

Рисунок 101

Рисунок 102
Полученное правило может быть применено к другим таблицам. Создадим новую таблицу с именем FC_FD_mpg_12, объединив таблицы FC_FD_mpg_1 и FC_FD_mpg_2 (рис. 103).

Рисунок 103
Применим к этой новой таблице полученное классификационное правило (рис. 104). Таблица примет вид, показанный на рис. 105.
Рисунок 104

Рисунок 105
Столбец DS_FC_FD_mpg_2 содержит классификационный признак (принимает значения Да/Нет или 1/0). Если для значений параметров автомашины выполняется полученное правило (рис. 105), то значение равно 1 (Да). Т.е. автомашина принадлежит классификационной группе таблицы FC_FD_mpg_2.
Теперь таблица FC_FD_mpg_12 содержит переменную, принимающую значение «Да/Нет», и для нее можно использовать исследование «Классификации». Запустим для этой таблицы исследование «Классификации» (рис. 106). Выбираем также линейную регрессию и в качестве целевой переменной задаем DS_FC_FD_mpg_2 (рис. 107).

Рисунок 106

Рисунок 107
Результатом исследования в отчете (рис. 108) получим предсказывающее выражение и условие принадлежности классу. Добавим новое полученное классификационное правило к таблице FC_FD_mpg_12 (рис. 109). Таблица примет вид, показанный на рис. 110.

Рисунок 108

Рисунок 109

Рисунок 110
Хотя полученное классификационное правило для таблицы FC_FD_mpg_12 несколько отличается от полученного ранее, анализ этой таблицы показывает практическое совпадение принадлежности машин тому или иному классу (значения классификационных признаков в столбцах DS_FC_FD_mpg_2 и CL_DS_FC_FD_mpg_2 практически совпадают).
Рассмотрим классификацию с типом процесса «Поиск законов» с той же целевой переменной. В результате получим предсказывающее выражение на рис. 111.

Рисунок 111
Если добавить полученное правило к таблице, то увидим, что результаты классификации практически совпадают (два правых столбца таблицы, рис. 112).

Рисунок 112
При выборе при классификации типа процесса «PolyNet Predictor» (рис. 113 ) получим отчет (рис. 114).

Рисунок 113

Рисунок 114
Если добавить полученное правило к таблице, то увидим, что результаты классификации также практически совпадают (три правых столбца таблицы, рис. 115).

Рисунок 115