

Методы решения задач Data Mining в Microsoft sql Server.
К настоящему времени сложился достаточно определенный набор задач, которые относятся к Data Mining [2].
Классификация (Classification).
В результате решения задачи классификации обнаруживаются признаки, которые характеризуют группы объектов исследуемого набора данных – классы (классы изначально определены). По этим признакам новый объект можно отнести к тому или иному классу.
Кластеризация (Clustering).
Кластеризация является логическим продолжением идеи классификации. Особенность кластеризации заключается в том, что классы объектов изначально не предопределены. Результатом кластеризации является разбиение объектов на группы и признаки, которые характеризуют это разбиение.
Ассоциация (Associations).
В ходе решения задачи поиска ассоциативных правил отыскиваются закономерности между связанными событиями в наборе данных.
Отличие ассоциации от двух предыдущих задач Data Mining состоит в том, что поиск закономерностей осуществляется не на основе свойств анализируемого объекта, а между несколькими событиями, которые происходят одновременно.
Последовательность (Sequence) или последовательная ассоциация (sequential association)
Последовательность позволяет найти временные закономерности между связанными событиями в наборе данных. Задача последовательности подобна ассоциации, но ее целью является установление закономерностей не между одновременно наступающими событиями, а между событиями, связанными во времени (т.е. происходящими с некоторым определенным интервалом во времени).
Правило последовательности: после события X через определенное время произойдет событие Y. Другими словами, последовательность определяется высокой вероятностью цепочки связанных во времени событий. Фактически, ассоциация является частным случаем последовательности с временным лагом, равным нулю.
Эту задачу Data Mining также называют задачей нахождения последовательных шаблонов (sequential pattern).
Прогнозирование (Forecasting).
В результате решения задачи прогнозирования на основе особенностей исторических данных оцениваются пропущенные или же будущие значения целевых численных показателей.
Определение и анализ отклонений или выбросов (Deviation Detection).
Цель решения данной задачи - обнаружение и анализ данных, наиболее отличающихся от общего множества данных, выявление так называемых нехарактерных шаблонов.
Оценивание (Estimation).
Задача оценивания сводится к предсказанию непрерывных значений признака.
Анализ связей (Link Analysis).
Задача нахождения зависимостей в наборе данных.
Визуализация (Visualization, Graph Mining).
В результате визуализации создается графический образ анализируемых данных. Для решения задачи визуализации используются графические методы, показывающие наличие закономерностей в данных.
Пример методов визуализации - представление данных в 2-D и 3-D измерениях.
Содержание задач рассмотрены в учебном пособии автора [3], а также в [1, 2, 4].
Для решения перечисленных задач разработано большое количество различных методов и алгоритмов [2, 4]. В SQL Server 2008 реализованы следующие [1]:
Метод дерева принятия решений - делает прогноз на основе связей между столбцами в наборе данных и моделирует эти связи в форме древовидной последовательности разбиений для конкретных значений. Поддерживает прогнозы как дискретных, так и непрерывных атрибутов.
Упрощенный Метод Байеса - оценивает вероятность связи между всеми входными данными и прогнозируемым столбцом. Поддерживает только дискретные или дискретизированные атрибуты. Рассматривает все входные атрибуты как независимые.
Метод временных рядов - анализирует данные, относящиеся ко времени, используя линейное дерево принятия решений. Для предсказания будущих значений во временной последовательности используются найденные закономерности.
Метод кластеризации - определяет связи в наборе данных, которые невозможно логически получить с помощью случайного наблюдения. Использует итерационный метод для группирования записей в кластеры с похожими характеристиками.
Метод линейной регрессии - если имеется линейная зависимость между целевой переменной и анализируемыми переменными, алгоритм находит наиболее эффективную связь между целью и входными данными. Поддерживает прогнозы непрерывных атрибутов.
Метод логистической регрессии - анализирует факторы, влияющие на результат, если результат принимает только два значения — обычно это наличие или отсутствие события. Поддерживает прогнозы как дискретных, так и непрерывных атрибутов.
Метод взаимосвязей - строит правила, описывающие элементы, которые, вероятнее всего, появятся вместе в транзакции.
Метод кластеризации последовательностей - определяет в последовательности кластеры событий, упорядоченных похожим образом. Обеспечивает сочетание анализа последовательности и кластеризации.
Метод нейронной сети - анализирует сложные входные данные или бизнес-проблемы, для которых имеется значительный объем обучающих данных, но для которых трудно вывести правила, используя другие алгоритмы. Используется для классификации дискретных атрибутов и регрессии непрерывных атрибутов. Может предсказывать несколько атрибутов.
Каждый из указанных методов интеллектуального анализа данных в SQL Server 2008 представляет собой механизм, создающий модели интеллектуального анализа данных. Чтобы создать модель, алгоритм сначала анализирует набор данных, осуществляя поиск определенных закономерностей и трендов. Затем алгоритм использует результаты этого анализа для определения параметров модели интеллектуального анализа данных.
Мы рассматриваем использование Excel для интеллектуального анализа данных. В Excel анализируемые данные представляются в виде таблиц, в которых столбцы соответствуют определенным атрибутам (параметрам) и определяются заголовком столбца. Строка таблицы содержит, как правило, идентификатор объекта и набор соответствующих значений атрибутов.
Пример таблицы исходных данных показан на рисунке 1.
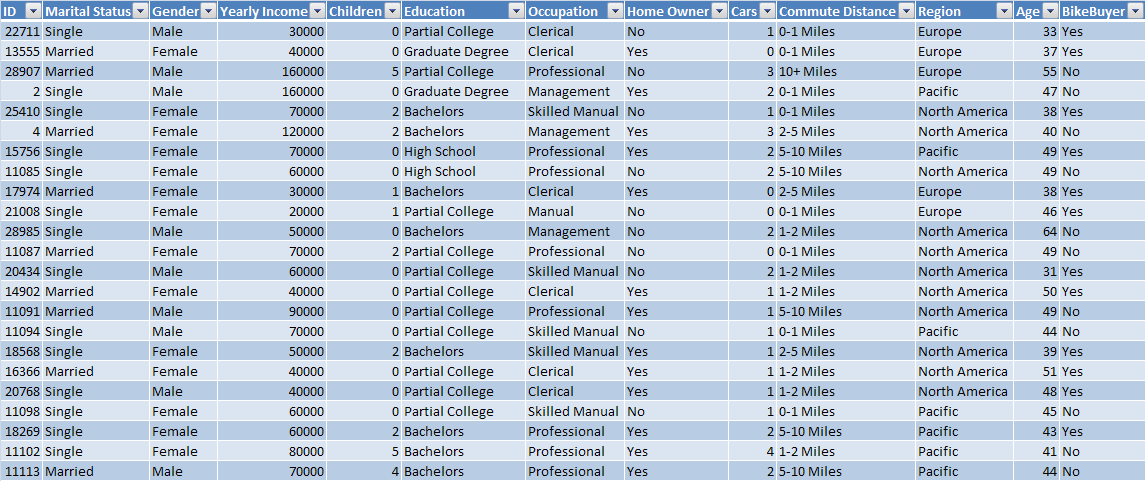
Рисунок 1
Определение типов данных столбцов в структуре интеллектуального анализа влияет на способ обработки данных алгоритмами при создании моделей интеллектуального анализа данных.
В каждом типе данных, например строковом или числовом, можно также определить тип содержимого, описывающий поведение данных в столбцах. Например, если числа в столбце повторяются с некоторой периодичностью, обозначая дни недели, можно указать циклический тип данных столбца.
Некоторые алгоритмы для правильного функционирования требуют определенных типов содержимого. Например, упрощенный алгоритм Байеса (Microsoft) не может использовать непрерывные столбцы на входе или не может прогнозировать непрерывные значения. Кроме того, некоторые столбцы могут содержать так много значений, что алгоритм уже не сможет выявить нужные закономерности в данных, на которых создается модель.
В таблице 1 рассматриваются особенности исходных данных, используемых в интеллектуальном анализе данных и типы данных, которые их поддерживают.
Таблица 1.
Данные |
Описание |
Дискретный
|
Столбец содержит дискретные значения. Например, дискретным может быть столбец «пол», содержащий конечное, счетное количество категорий пола. Значения в дискретном столбце не предполагают сортировку, если только они не являются числовыми; значения четко различаются, а дробные значения использовать нельзя. Хорошим примером дискретных числовых данных являются междугородние телефонные коды. |
Непрерывный
|
Столбец содержит значения, представляющие непрерывный набор числовых данных. В отличие от дискретного столбца, содержащего конечные счетные данные, непрерывный столбец представляет данные измерений и может содержать бесконечное количество дробных значений. Примером непрерывного столбца является столбец доходов. Данный тип содержимого поддерживается следующими типами данных: Date, Double и Long. |
Дискретизированный
|
Столбец содержит значения, представляющие группы или сегменты значений, полученных из непрерывного столбца. Сегменты воспринимаются как упорядоченные дискретные значения. Дискретизация — это процесс размещения значений непрерывного набора данных в сегменты так, чтобы получилось ограниченное число допустимых значений. Можно дискретизировать как численные, так и строковые столбцы (будет рассмотрено далее). Данный тип содержимого поддерживается следующими типами данных: Date, Double, Long и Text. |
Ключ
|
Столбец, уникально определяющий строку. Данный тип содержимого поддерживается следующими типами данных: Date, Double, Long и Text. |
Последовательность ключа
|
Столбец является особым видом ключа, где значения представляют последовательность событий. Значения упорядочены и не должны находиться на одинаковом расстоянии друг от друга. Данный тип содержимого поддерживается следующими типами данных: Double, Long, Text и Date. |
Временной ключ
|
Столбец является особым видом ключа, где данные представляют упорядоченные значения, которые возникают в масштабе времени. Данный тип содержимого поддерживается следующими типами данных: Double, Long и Date. |
Таблица
|
Вложенная таблица представлена в модели интеллектуального анализа данных специальным типом столбца, имеющим табличный тип данных. Для каждой конкретной строки варианта этот тип столбца содержит выбранные строки из «дочерней» таблицы, относящиеся к «родительской» таблице. |
Рассмотрим кратко приведенные методы.