

Инструмент «Оценка»
Инструмент «Оценка» (рис. ) используется для создания и обучения дерева решений для оценки значений непрерывной переменной.
В этом примере используется информация по автомобилям (средний пробег в милях, соответствующий расходу 1 галлона топлива - mpg, количество цилиндров у каждого автомобиля - cyl, объем цилиндра в кубических дюймах -displ, мощность в лошадиных силах - power, вес - weight, время разгона до скорости 100 миль в час - accel, год выпуска -Year, место выпуска - origin и модель - model). mpg - это величина, обратная расходу топлива. Каждая строчка таблицы данных соответствует одному автомобилю. Поля origin и model содержат категориальные (текстовые) значения.
После запуска инструмента нужно задать расположение исходных данных (в примере Лист1, рис. 108).
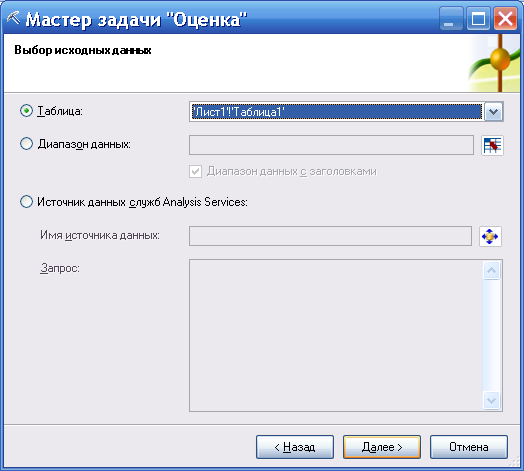
Рисунок 108
Далее задаются Анализируемый и Входные столбцы. В примере задается Анализируемый столбец mpg (пробег автомашины в милях на одном галлоне топлива). В качестве аргументов используются другие параметры автомобилей (рис. 109).
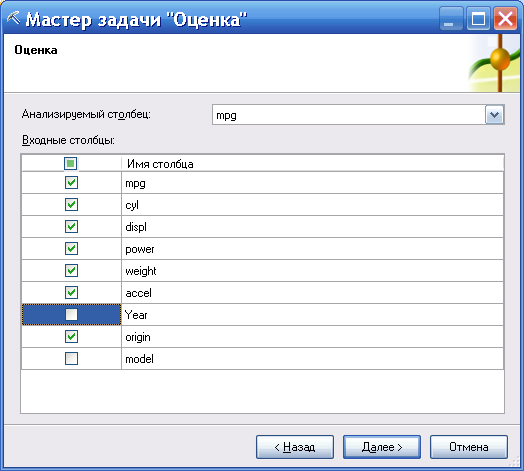
Рисунок 109
Формируется по умолчанию информация по модели, которая сохраняется на сервере и ее можно использовать для дальнейшего тестирования или прогнозирования. Описание модели (формируется по умолчанию) можно редактировать (рисунок 110).
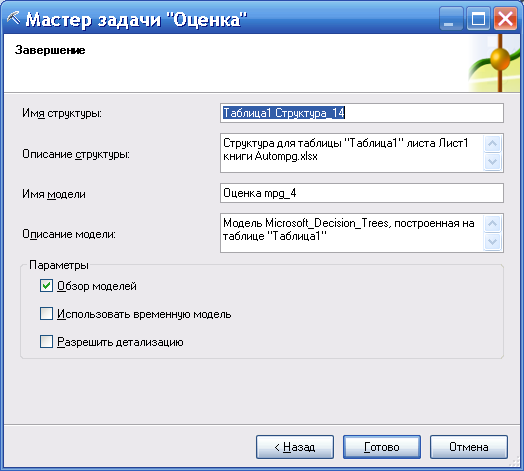
Рисунок 110
Полученный результат показан на рисунке 111. Вкладка «Дерево решений» показывает полученное дерево для наиболее значимых аргументов, которые выявлены алгоритмом анализа (weight, cyl, accel). Можно управлять количеством отображаемых уровней (Показать уровень…).
Если выделить узел дерева (например, третий элемент снизу третьего уровня), то в правой нижней части экрана отображается полученное правило для этого узла:
«weight >= 3025 and < 3731 and accel < 14,3
Существующие варианты: 20
Отсутствующие варианты: 0
mpg = 16.340»
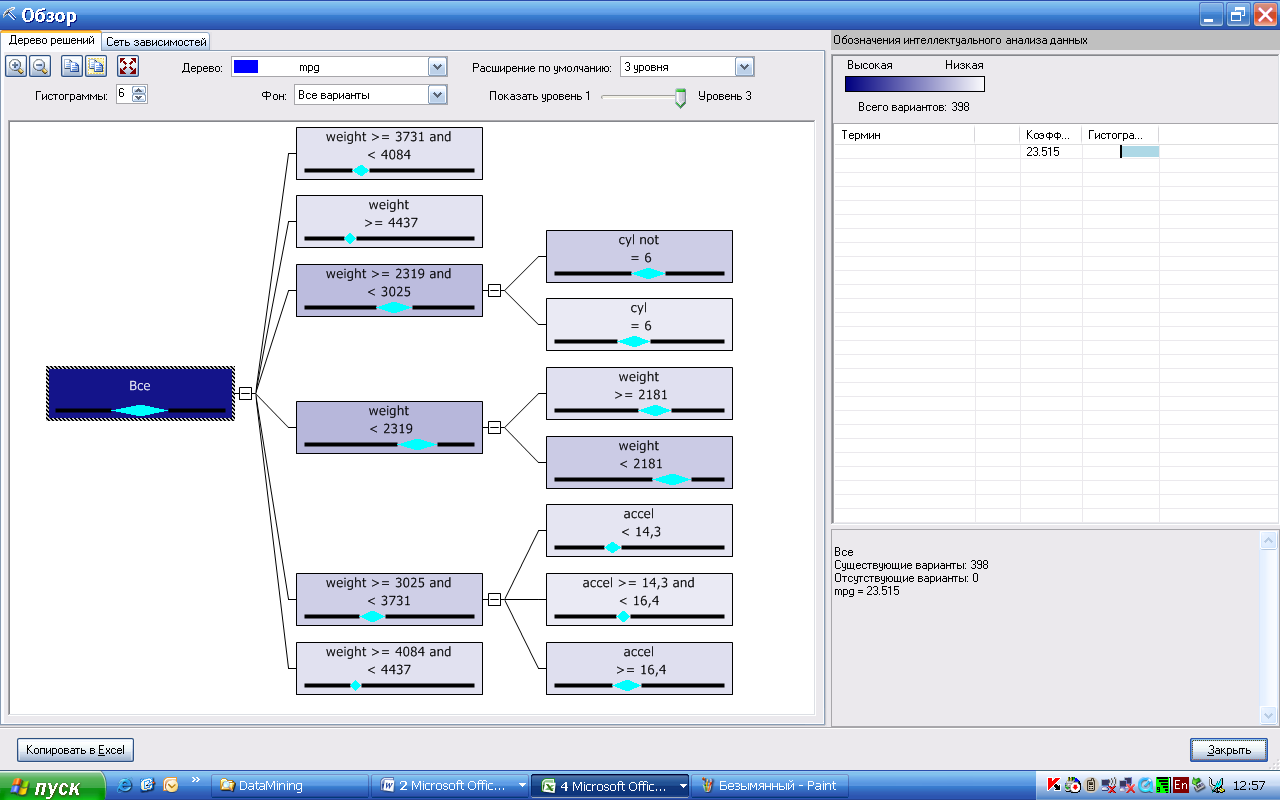
Рисунок 111
Вкладка «Сеть зависимостей» показывает выявленные связи между прогнозируемым параметром и выявленными влияющими атрибутами.
Ребро связи имеет вес, который связан с ползунком слева. Чем больше вес, тем сильнее зависимость прогнозируемого параметра от атрибута. Перемещая ползунок вниз, будут отображаться наиболее сильные связи (на рисунке 112 самая сильная связь между mpg и weight, т.е. weight более влияет на mpg по сравнению с другими аргументами).
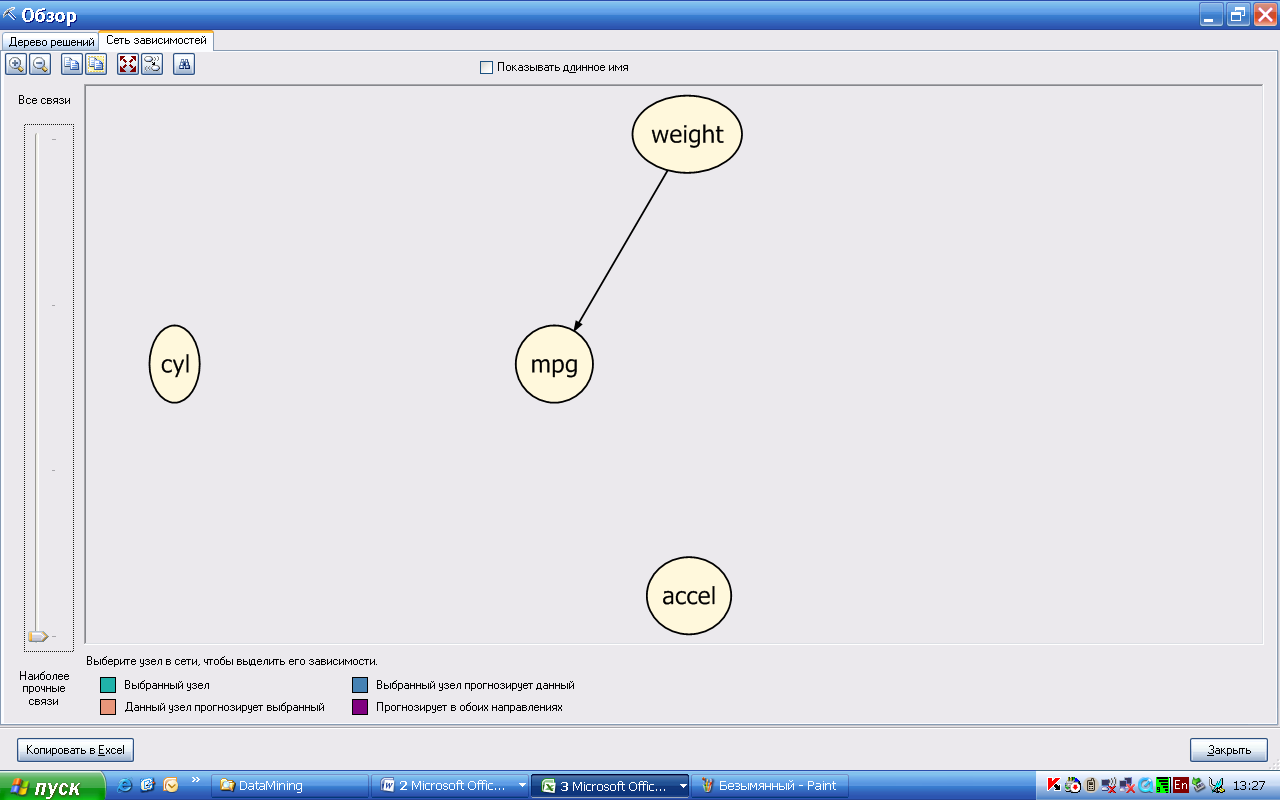
Рисунок 112
Инструмент «Кластеризация»
Инструмент «Кластеризация» позволяет провести кластерный анализ информации.

После запуска инструмента нужно задать расположение исходных данных (в примере Лист1, рис. 113).
Рисунок 113
Далее (рисунок 114) задаются включаемые в анализ параметры. Также можно задать желательное число кластеров или оно будет определяться автоматически (задано Автоматическое определение).
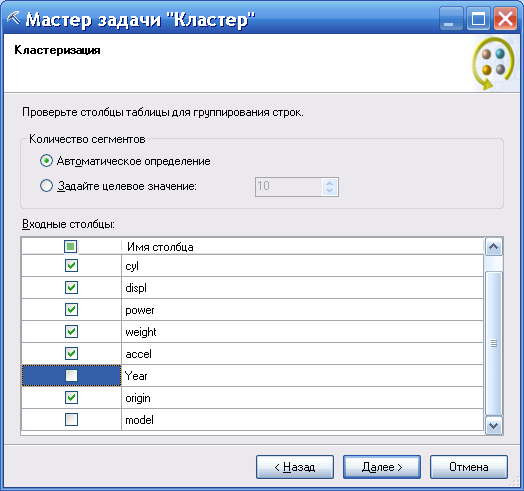
Рисунок 114
Формируется по умолчанию информация по модели, которая сохраняется на сервере и ее можно использовать для дальнейшего тестирования или прогнозирования. Описание модели (формируется по умолчанию) можно редактировать (рисунок 115).
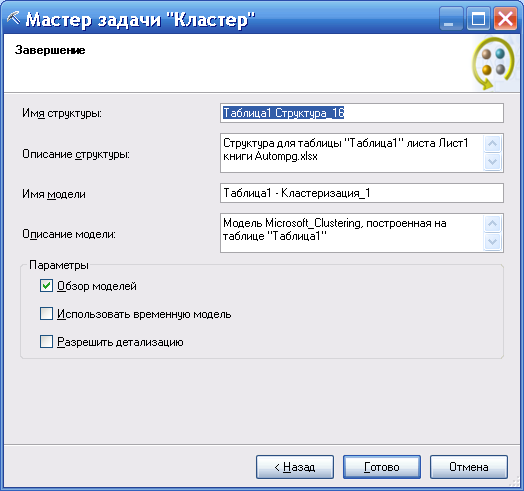
Рисунок 115
Полученный результат показан на рисунке 116. Выделено 6 кластеров.
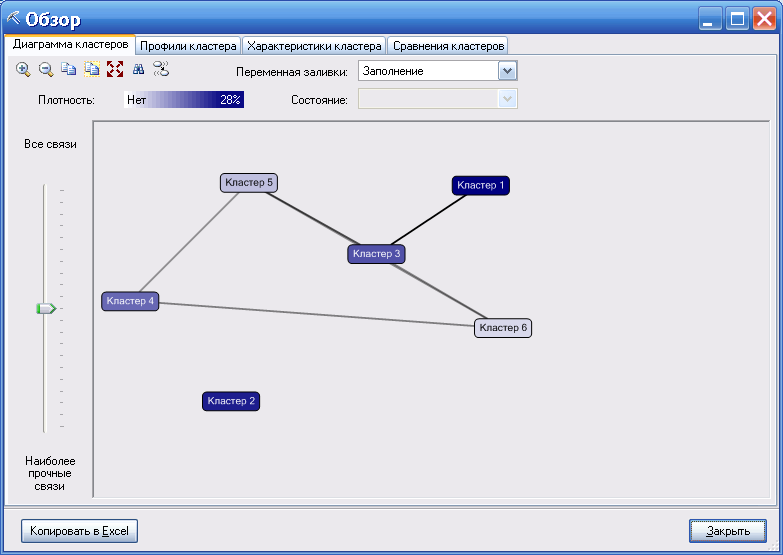
Рисунок 116
Результат включает 4 вкладки: Диаграмма кластеров (показана на рисунке 116), Профили кластера, Характеристики кластера, Сравнение кластеров.
Диаграмма кластеров отображает каждый кластер в виде узла и линий связи. Толщина линий связи отображает силу связей (похожесть кластеров).
Ползунок слева позволяет выбрать отображение наиболее сильных связей.
На Диаграмме кластеров в верхней части имеется список «Переменная заливки» и «Состояние». При выборе в первом значения Заполнение список «Состояние» не доступен. В этом случае яркость фона узлов отображает относительное количество объектов в каждом кластере (чем ярче, тем больше).
При выборе в списке «Переменная заливки» конкретного аргумента, в списке «Состояние» отображаются диапазоны их значений и распределение этих значений по кластерам.
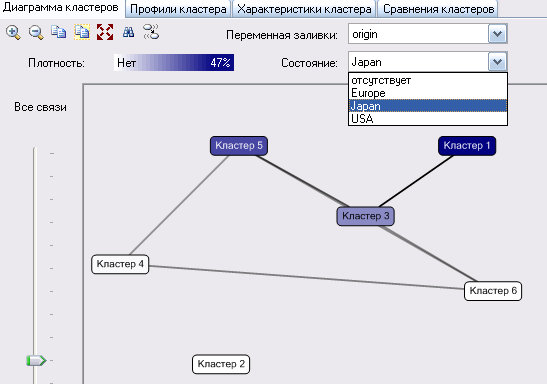
Рисунок 117
В примере на рисунке 117 выбрана переменная origin (страна производитель). В списке возможных значений выбрана Japan. На рисунке видно, что больше всего японских машин находится в Кластере 1, а также в Кластере 5 и Кластере 3 (последовательно уменьшается яркость затенения объекта на диаграмме). Значение плотность в процентах показано в окне Плотность (самая большая яркость в Кластере 1 соответствует 47% от общего количества объектов во всех кластера).
Профили кластера показаны на рисунке 118. Отображается распределение значений переменных по кластерам. Отличается отображение непрерывных и дискретных переменных (непрерывные - в виде ползунка на диапазоне значений, дискретные – цветная диаграмма.)
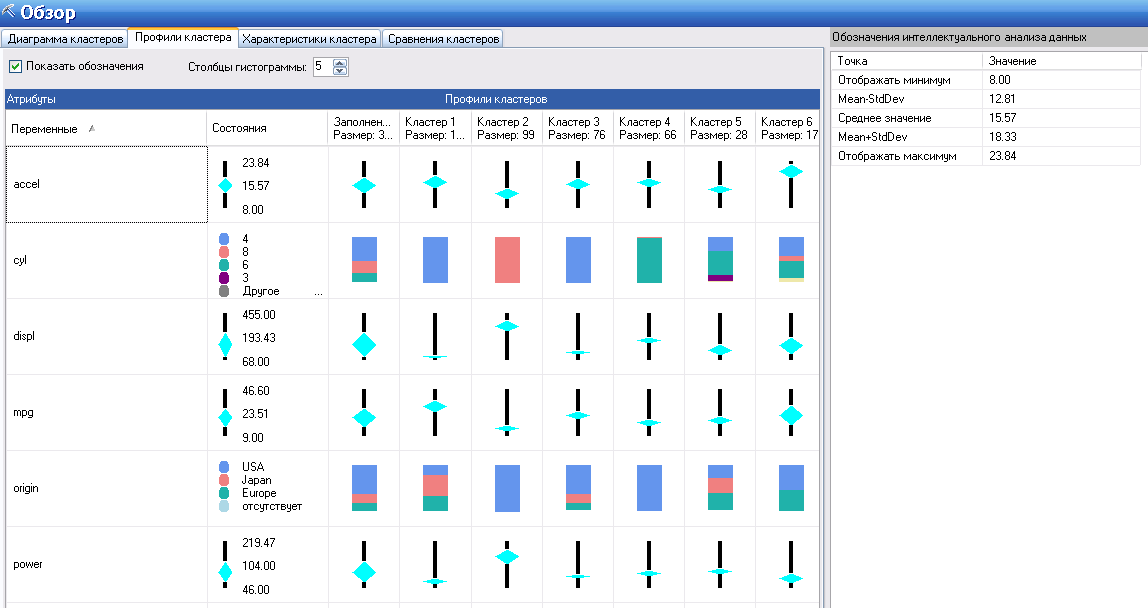
Рисунок 118
Справа от имени переменной показаны характерные значения выбранной переменной (на рисунке непрерывная переменная accel).
При выборе дискретной переменной (cyl), характеристики цветов диаграммы отображаются в правой части (рисунок 119).
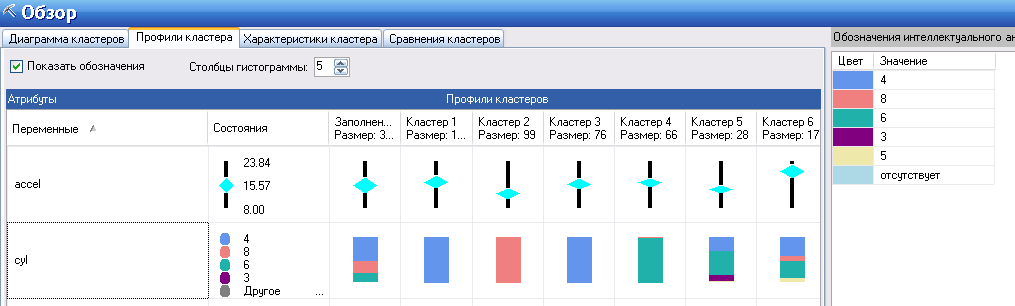
Рисунок 119
Отображение Характеристик кластера показано на рисунке 120. Для выбранного кластера (выбран Кластер 1) показаны переменные, диапазоны их значений и вероятность попадания в кластер).
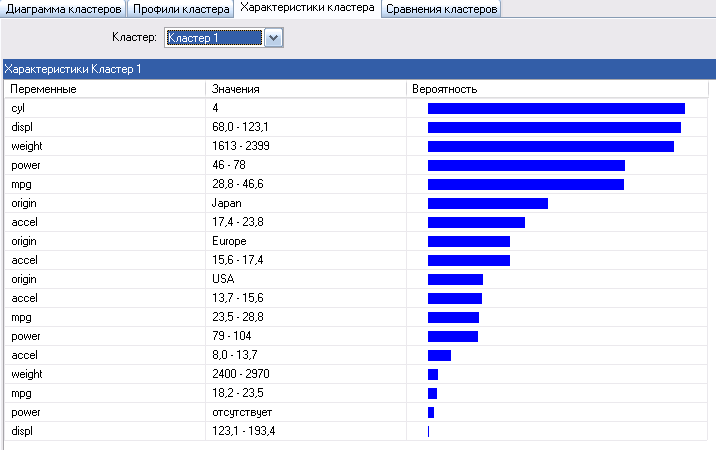
Рисунок 120
По умолчанию строки располагаются в порядке убывания вероятности, но можно управлять видом представления по переменным. Щелчок мыши по области Переменные меняет отображение на алфавитное упорядочение переменных (рисунок 121).
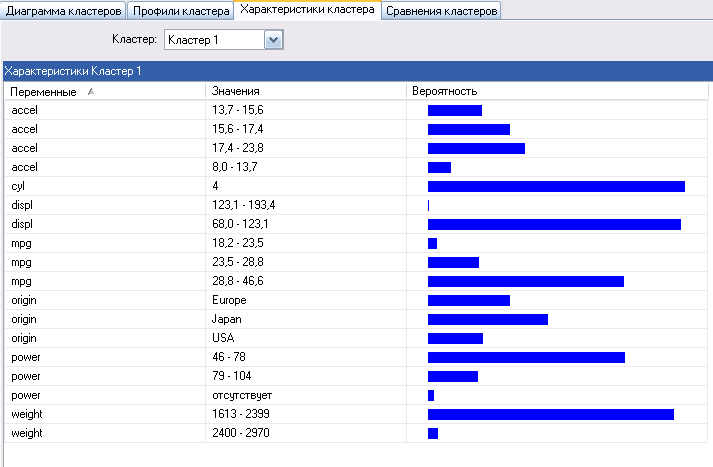
Рисунок 121
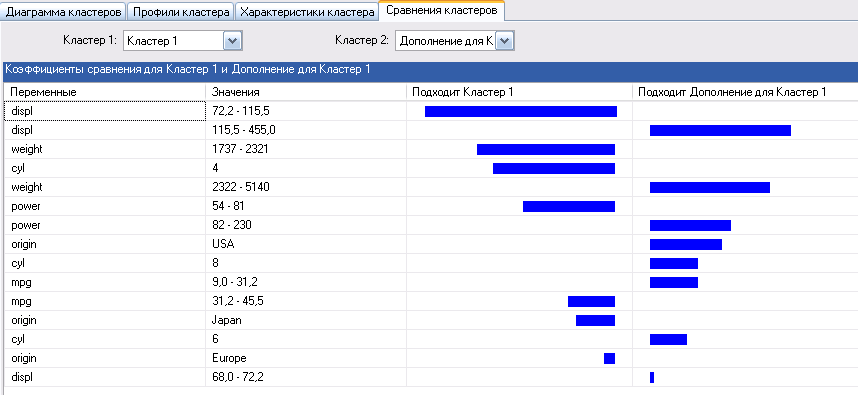
Рисунок 122
Сравнение кластеров показано на рисунке 122. По умолчанию отображается область значений переменных для кластера (на рисунке выбран Кластер 1) и его дополнение (не соответствующая кластеру область значений).
Можно также выбрать сравнение характеристик отдельных кластеров. На рисунке 123 показаны сравнительные характеристики Кластера 3 и Кластера 2.
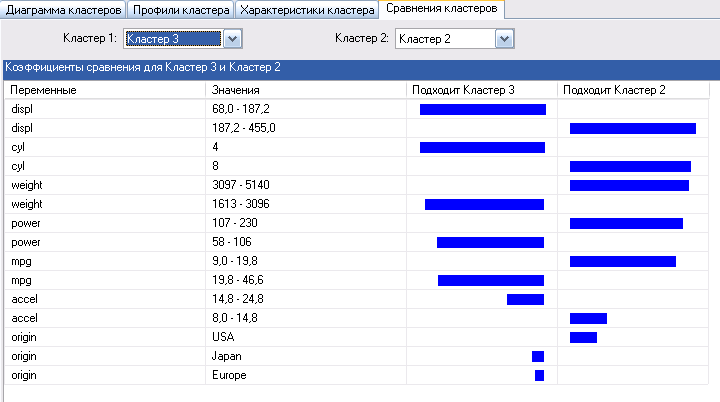
Рисунок 123