

Просмотр данных.
Мастер просмотра данных помогает понять тип и объем данных в таблице данных с помощью построения диаграмм распределения и значений для выбранных столбцов. В зависимости от типа данных в столбце и количества различных значений, мастер группирует несколько значений в сегменты, отображающие количество значений в каждой группе.
Инструмент Просмотр данных предназначен для показа гистограмм для дискретных и непрерывных столбцов, причем он имеет дополнительную функциональную возможность, которая позволяет показывать непрерывные гистограммы в виде столбцов таблиц.
При вызове инструмента нужно указать исследуемую таблицу данных (рисунок 62).
Рисунок 62
Далее выбирается столбец таблицы (рис. 63).
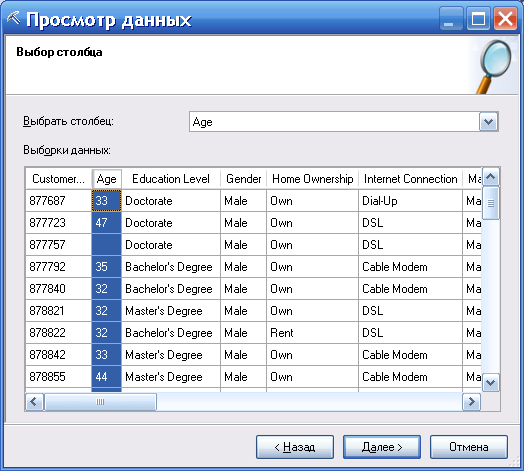
Рисунок 63
Если в столбце содержатся непрерывные числовые значения, то доступны два представления: линейный график и линейчатая диаграмма. На линейном графике значения данных расположены на оси X, а число вариантов — на оси Y. Линейчатая диаграмма упорядочивает все значения.
Данные для выбранного столбца отображаются следующим образом (рисунок 64). На этом рисунке показано отображение данных, как дискретных. В линейчатой диаграмме числовые значения не группируются.
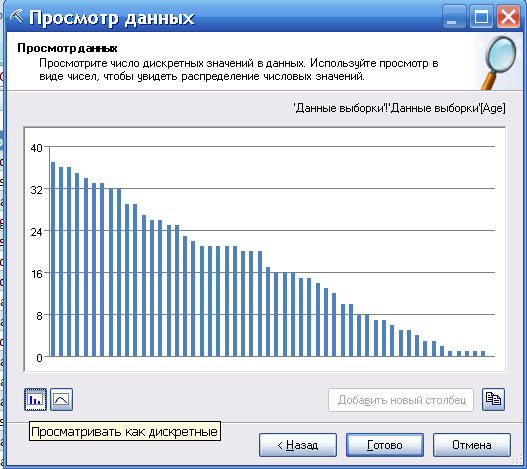
Рисунок 64
При выборе в виде чисел представление данных имеет следующий вид (рисунок 65).
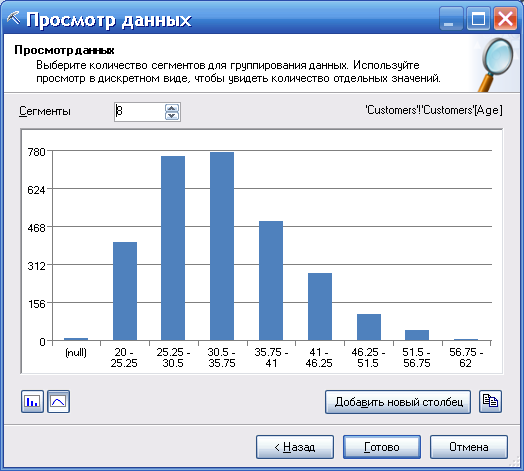
Рисунок 65
В зависимости от типа данных в столбце и количества различных значений, мастер группирует несколько значений в сегменты, отображающие количество значений в каждой группе. Можно изменять число сегментов (рис. 66) или скопировать диаграмму с содержимым в Excel для просмотра (добавить новый столбец, рис. 67).
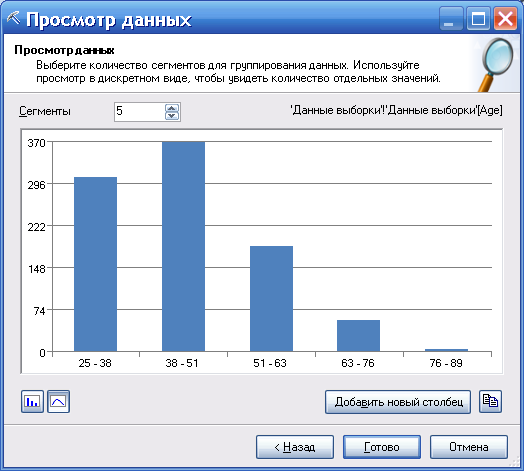
Рисунок 66
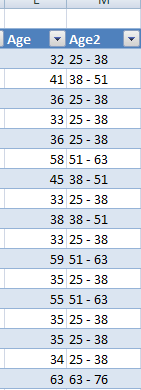
Рисунок 67
Инструмент Очистить данные
Инструмент Очистить данные включает средства для анализа выбросов и переразметки (рис. 68).
Инструмент Очистить данные можно использовать для удаления или замены тех значений, которые не достигают определенного порога. Возможности инструмента предлагают множество вариантов выполнения этой задачи. Можно заменить эти значения неким определенным значением или удалить строки, содержащие эти значения.
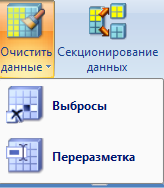
Рисунок 68
Инструмент Выбросы можно использовать для непрерывных столбцов, чтобы обеспечить нахождение всех значений в некотором разумном диапазоне. При дискретных данных имеется несколько вариантов работы с выпадающими значениями.
Термин выбросы относится к значениям данных, которые являются проблематичными по одной из следующих причин:
значения находятся вне допустимого диапазона;
данные были введены неправильно;
данные отсутствуют;
данные представляют собой пробел или пустую строку;
значения настолько отличаются от остальных значений, что могут повлиять на результаты анализа.
Вне зависимости от природы проблемы мастер удаления выбросов позволяет управлять этими значениями таким образом, чтобы можно было продолжить анализ.
При запуске инструмента (рис. 69) указывается положение исходных данных (рис. 70).
Рисунок 69
Рисунок 70
Далее выбирается столбец данных, рисунок 71.
Рисунок 71
В зависимости от типа данных (дискретные или непрерывные) выбросы можно удалить или изменить несколькими различными способами.
Для дискретных значений каждый столбец линейчатой диаграммы представляет определенное значение, причем высота столбца соответствует числу вариантов для каждого значения.
Можно указать минимальное число значений по имеющимся городам, которые будет включаться в последующий анализ (в примере на рисунке, для столбца Сity (город) накладывается ограничение на количество данных в таблице - минимум 65 значений). Значения с малой поддержкой могут не иметь важных шаблонов и могут являться источником шума, который снижает общее качество модели (например, 65 значений - это граница поддержки, для которой будет строиться модель, рис. 72).
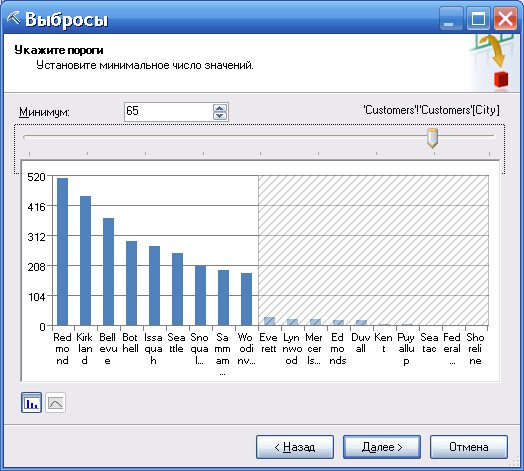
Рисунок 72
Следующий пункт меню определяет, что делать с этими данными (рисунок 73)
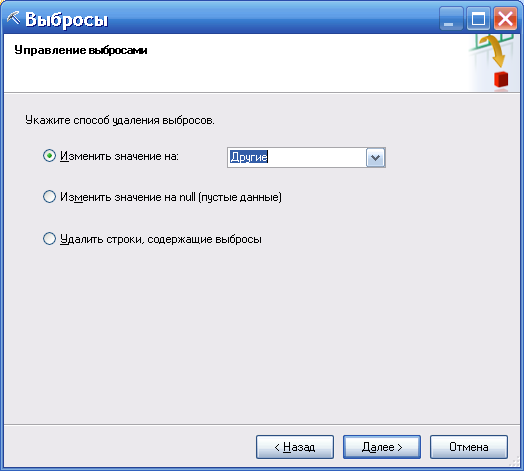
Рисунок 73
и где расположить новую таблицу данных (рисунок 74).
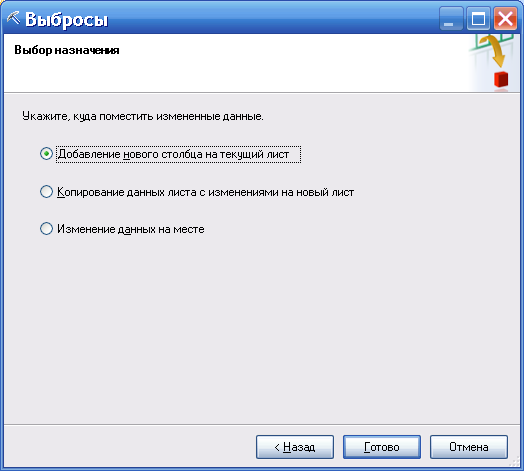
Рисунок 74
Для непрерывных данных меню удаления выбросов имеет следующий вид (рисунок 75). Имеется возможность управлять дискретизацией данных (Решение) и задавать область возможных значений (минимум и максимум).
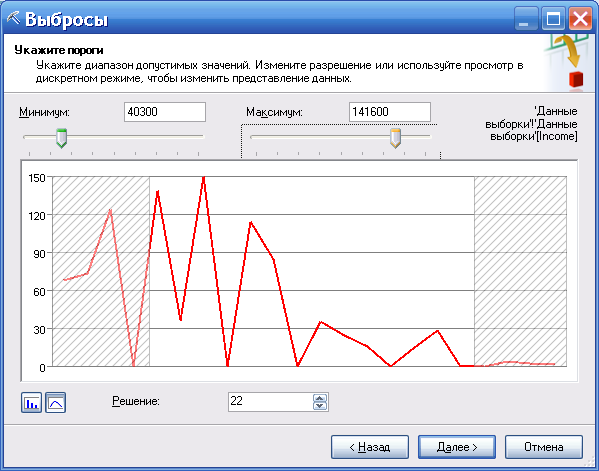
Рисунок 75
В этом случае также добавлен пункт для определения, что делать с этими данными (Изменить значение на среднее, рисунок 76).
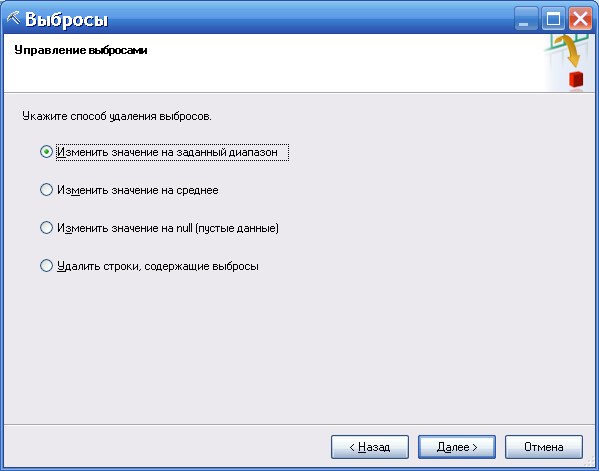
Рисунок 76
Переразметка.
Рисунок 77
Например, используя этот инструмент (рис. 77), можно для таблицы с данными о клиентах заменить все возможные виды образования на два: высшее и не высшее (рисунки 78, 79, 80).
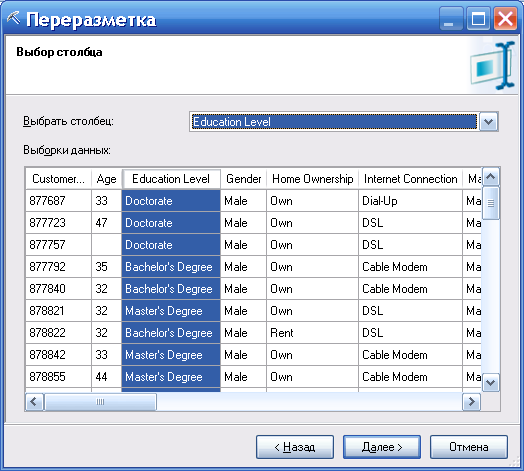
Рисунок 78
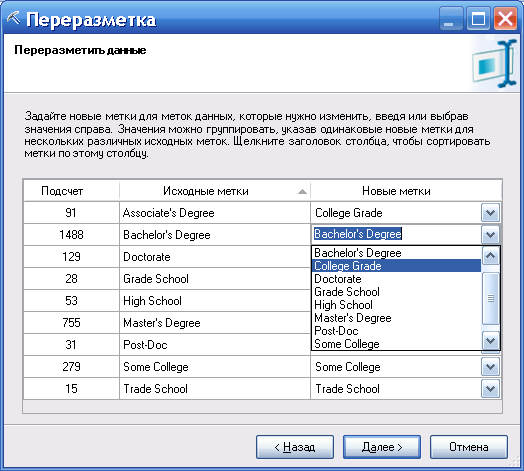
Рисунок 79
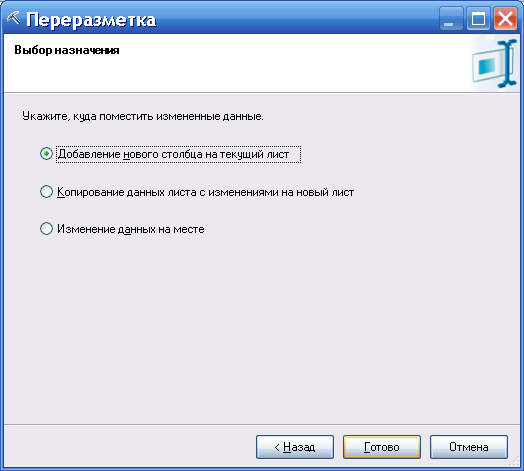
Рисунок 80
Добавленный столбец показан на рисунке 81.
Рисунок 81