

Анализ гипотетических вариантов
Средство Анализ гипотетических вариантов (рис. 54) анализирует шаблоны данных и оценивает влияние изменений.

Рисунок 54
Например, необходимо узнать, как изменится объем продаж, если будут увеличены цены на продукцию. Средство Анализ гипотетических вариантов позволяет указать размер изменения в виде процента или абсолютного значения: например, можно задать вопрос, насколько увеличится полный объем продаж, если снизить цены на 0,05 %. В результате получим прогнозируемые значения в новом столбце таблицы данных.
Аналогично поиску решения можно проводить исследования для одной строки или для всей таблицы.
В первом случае нужно выделить анализируемую строку данных (клиент), рис. 55.
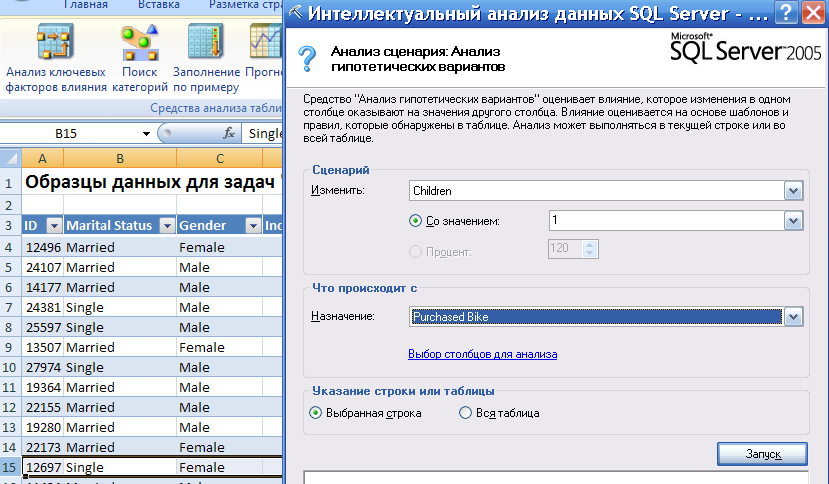
Рисунок 55
Анализируем влияние параметра Children (Количество детей) на целевой параметр (Покупка велосипеда) для конкретного клиента (выбранная строка). Для этой строки исходное значение 'Purchased Bike' = NO. Задаем количество детей -1. Для столбцов с числовыми параметрами можно задавать конкретные значения или процент изменения. Для дискретных параметров или не числовых параметров задание процента недоступно.
Это заданное значение позволяет получить гипотетическое положительное решение (при изменении данного параметра на значение 1 клиент купит велосипед, рисунок 56) с хорошей точностью (точность оценивается алгоритмом анализа).

Рисунок 56
Можно провести исследование для всей таблицы, изменяя значение параметра Education на Bachelors (как изменится значение 'Purchased Bike', если изменить значение Education во всех строках на Bachelors, рис. 57).

Рисунок 57
Процесс решения отображается (рис. 58).

Рисунок 58
Завершение процесса поиска фиксируется (рисунок 59) и выдается результат (рисунок 60).

Рисунок 59

Рисунок 60
На рисунке показано старое и полученное значение 'Purchased Bike', а также достоверность результата для каждой строки таблицы при соответствующем изменении значения Education во всех строках на Bachelors.
Клиент интеллектуального анализа данных для Excel
Панель инструментов Интеллектуального анализа данных показана на рисунке 61.

Рисунок 61
Панель инструментов Интеллектуальный анализ данных имеет следующие области.
Подготовка данных.
Моделирование данных.
Точность и правильность.
Использование модели.
Управление моделью.
Соединения.
Подготовка данных
Панель инструментов Подготовка данных содержит средства для просмотра и очистки данных при подготовке решения задач интеллектуального анализа. Можно также разделить данные на обучающие и проверочные наборы.
Исследование и подготовка исходных данных являются одним из самым важным шагов процесса интеллектуального анализа данных.
Самая часто выполняемая операция с данными — это вычисление значение некоторых значений по известным значениям других столбцов исходных данных.
Например, многие наборы данных имеют столбцы Дата начала и Дата окончания. На основе этих данных можно рассчитать Длительность, по которой можно производить анализ. Такие возможности являются стандартными в Excel.
Клиент Data Mining Client добавляет некоторые дополнительные инструменты исследования и подготовки данных, которые работают со столбцом данных.
Очень часто бывает удобнее работать с диапазонами данных, а не с непрерывными значениями. Например, вместо рассмотрения Возраста как непрерывного числа, можно разбить возраст на отдельные диапазоны, которые легче интерпретируются.
Часто встречаются данные, когда имеется множество значений, но только несколько этих значении имеют значительную поддержку. Например, количество клиентов компании по городам. В подобных ситуациях обычно есть много городов, в которых живет всего несколько человек. Для многих задач интеллектуального анализа значения с малой поддержкой не имеют важных шаблонов и могут даже являться источником шума, который снижает общее качество модели.
Еще одна причина, по которой в данных появляется много различных значений, состоит в том, что одно понятие может быть представлено множеством способов. Типичный пример — образование. Значения могут быть такими: Среднее, Высшее, Бакалавр, Магистр и т.д. Но для бизнес-проблемы единственным интересным может оказаться факт наличия или нет высшего образования. В этом случае значения столбца Образование можно задать двумя значениями.
Возможна также ситуация, когда для числовых данных некоторые значения будут сильно отличаться от остальных значений данных. Несколько тысяч сотрудников компании со средними доходами и несколько топ-менеджеров. Эти несколько значений не являются характерными и могут исказить результаты.
Все эти задачи и решаются с помощью инструментов панели Подготовка данных.