

Инструмент прогнозирования Прогноз
Инструмент прогнозирования Forecasting анализирует ряды чисел, выявляет шаблоны эволюции этих рядов и экстраполирует эти шаблоны для того, чтобы выработать прогнозы на будущую эволюции этих рядов. Например, если данные содержат столбец даты и столбец, показывающий объем продаж по каждому дню месяца, можно прогнозировать объем продаж на будущие дни.
Столбец для прогнозирования должен содержать непрерывные числовые данные, например данные типа денежные или другого числового типа.
По возможности данные должны также включать столбец, содержащий ряд времени или даты. Вместо даты и времени можно использовать числовую последовательность (1,2,3…). Однако значения в столбце последовательности должны быть уникальны. При обнаружении средством Прогноз в этом столбце дублирующихся значений произойдет ошибка.
Этот инструмент анализирует данные на наличие шаблонов следующих категорий.
Тренд - устойчивое направление эволюции для ряда.
Периодичность (известная также как сезонность) — когда событие происходит через определенный интервал времени.
Взаимная корреляция — более сложный шаблон, показывающий зависимость между значениями одного ряда и значениями другого (в один и тот же либо в другой момент времени). Для того чтобы инструмент Прогноз мог обнаруживать взаимные корреляции между рядами, необходимо подключиться к аналитическим службам версии Enterprise Edition.
Инструмент прогнозирования Forecast обнаруживает (или позволяет указать) такие шаблоны и использует их при выработке прогноза.
Инструмент предполагает, что ряды значений будут представлены в виде столбцов таблицы Excel.
Исходные данные - таблица данных по продажам по месяцам на рисунке 37.
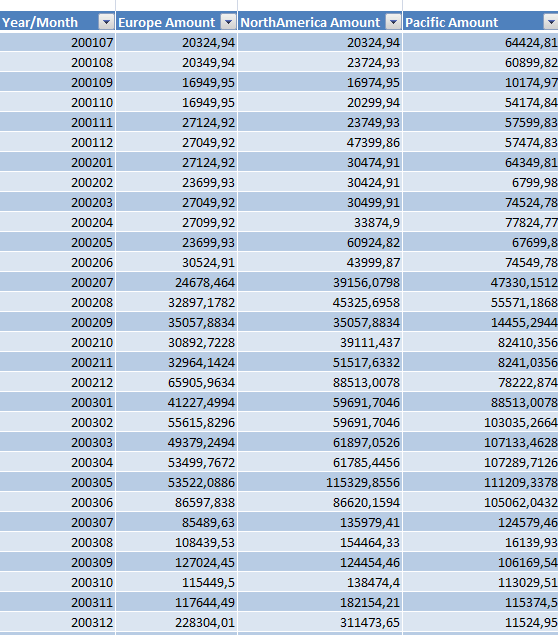
Рисунок 37
При запуске инструмента нужно определить прогнозируемые столбцы (рис. 38).
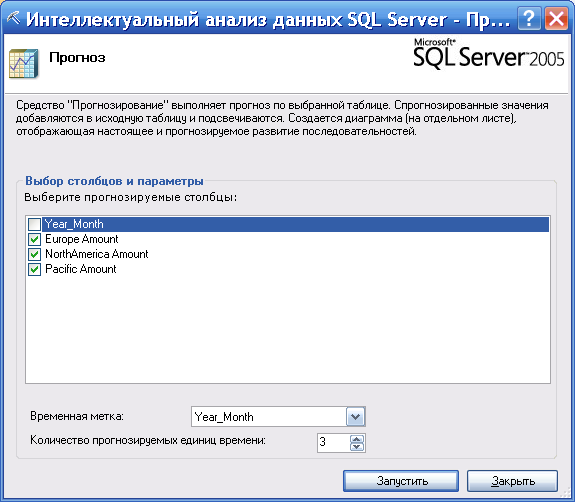
Рисунок 38
Также можно указать количество выполняемых прогнозов. Например, три.
После завершения работы алгоритма выдается график прогноза (рис. 39) и полученные значения прогноза добавятся в конец таблицы источника данных (рис. 40). Новые значения рядов времени не добавлены; это позволяет сначала предварительно просмотреть прогнозы.
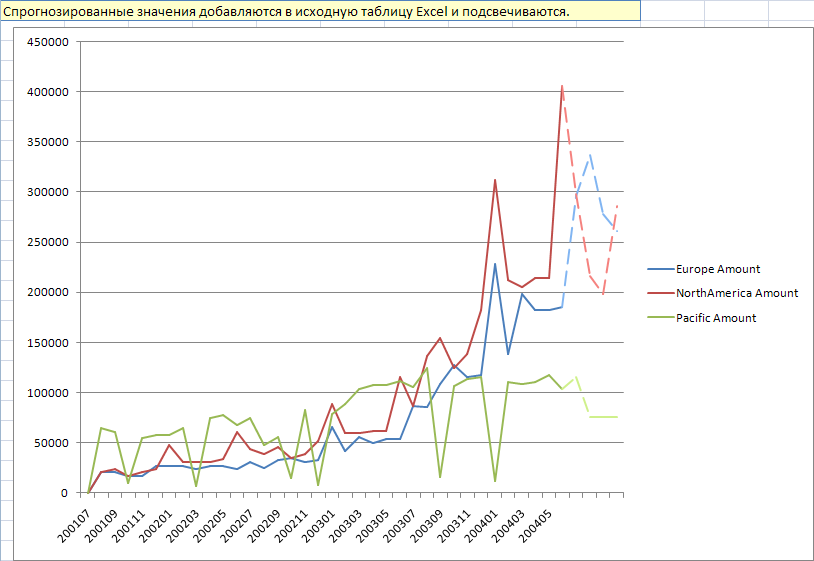
Рисунок 39
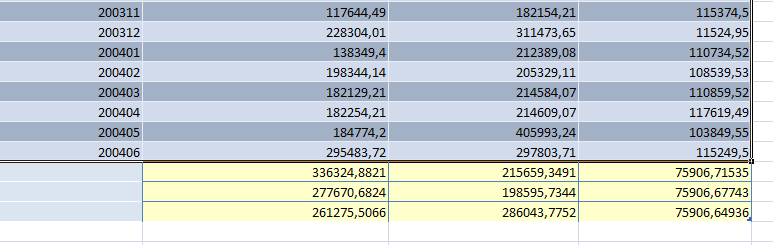
Рисунок 40
Для выполнения прогноза может не хватать необходимого количества временных срезов (минимально необходимое количество данных). Обычно это означает, что алгоритму недостаточно данных для прогноза на более продолжительное время. Средство Прогноз делает только те прогнозы, которые отвечают минимальному порогу вероятности.
Инструмент Выделение исключений

Иногда данные содержат значения, выходящие за пределы ожидаемого диапазона. Такие значения, которые называют выбросами, часто бывают неправильными из-за ошибок ввода или указания неверных трендов. Исключения могут снизить качество анализа. Инструмент Выделение исключений помогает найти эти значения, просмотреть их и предпринять то или иное действие.
Рисунок 41
Алгоритм работает во всем диапазоне данных таблицы Excel или с несколькими выбранными столбцами (рис. 41). Можно также настроить порог, управляющий изменчивостью данных, чтобы обнаруживать больше или меньше исключений.
По завершении работы алгоритм создает несколько листов, которые содержат сводный отчет о количестве выбросов, найденных в каждом проанализированном столбце (рис. 42). Алгоритм также выделяет подсветкой исключения в исходной таблице данных.
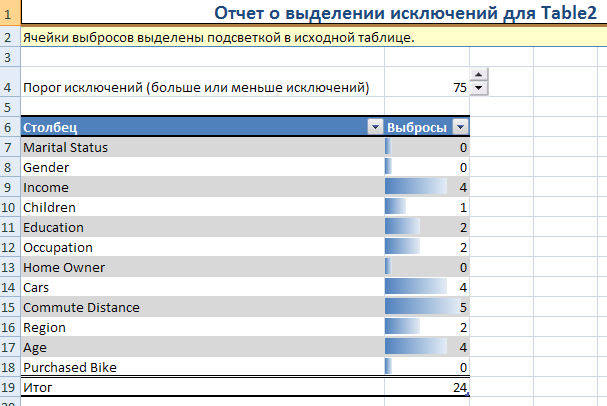
Рисунок 42
Поскольку алгоритм анализирует общие тренды, он может обнаружить, что большая часть значений в строке отвечает условиям, и выделить только одну ячейку в этой строке. В приведенном примере на рисунке подсветкой будет выделен только столбец «Region».

Рисунок 43
После просмотров выделенных ячеек можно вернуться к сводному отчету и изменить значение Порог исключений. Поскольку это значение задает вероятность, с которой конкретная ячейка содержит неверные значения, при повышении порога отфильтровываются значения с меньшей вероятностью. И наоборот, при понижении порога появляется больше выделенных ячеек.