

Средства анализа таблиц Excel. Инструмент Table Analysis (Анализировать).
Средства анализа таблиц Excel включает следующие средства аналитики:
Анализ ключевых факторов влияния
Поиск категорий
Заполнение по примеру
Прогноз
Выделение исключений
Анализ сценария: поиск решения
Пункт меню Table Analysis «Анализировать» показан на рисунке 11.
Рисунок 11
Для появления этого пункта меню, рабочую область нужно отформатировать как таблицу и активизировать рабочую область (щелчок мыши внутри таблицы), рисунок 12.
Рисунок 12
Лента меню «Анализировать» показана на рисунке 13.
Рисунок 13
Инструмент «Анализ ключевых факторов влияния».
На рисунке 14 приведена таблица исходных данных, содержащая демографическую информацию о клиентах и информацию о покупке ими велосипедов (колонка Purchased Bike, со значениями Yes, No).
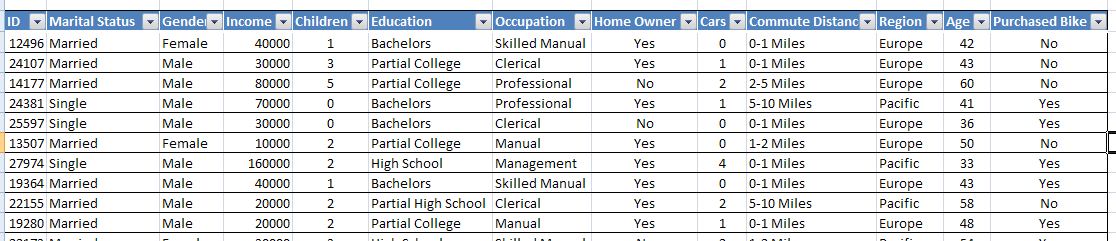
Рисунок 14
Инструмент «Анализ ключевых факторов влияния» позволяет выявить влияние демографических данных клиентов на их решение о покупке.
Задается столбец для анализа влияющих факторов (Purchased Bike) и влияющие столбцы (выбраны все, рисунок 15)
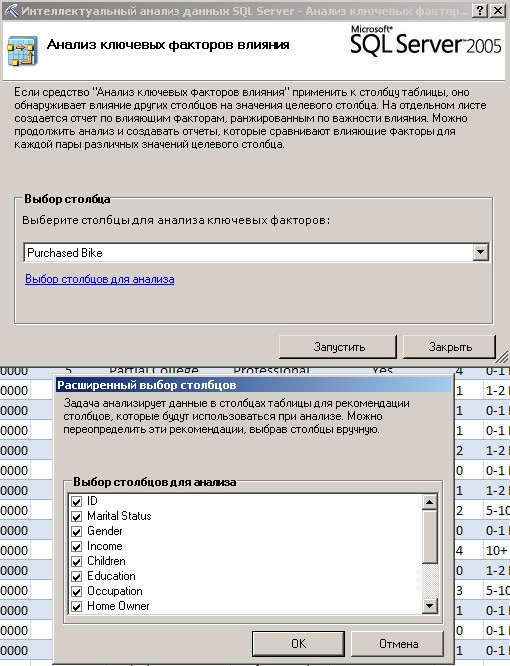
Рисунок 15
Полученный отчет показан на рисунке 16.
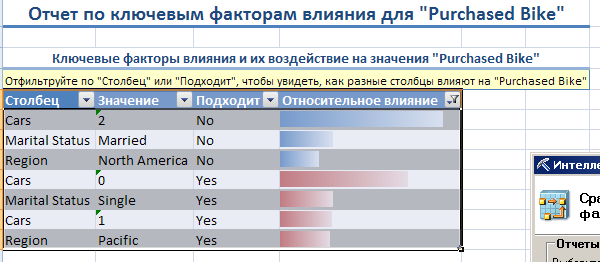
Рисунок 16
Выделены наиболее значимые факторы (влияющие демографические данные клиентов) Cars, Marital Status, Region и показаны значения и степень влияния этих факторов на решение о покупке или нет.
Можно добавить другой формат отчета для анализа (рисунок 17).
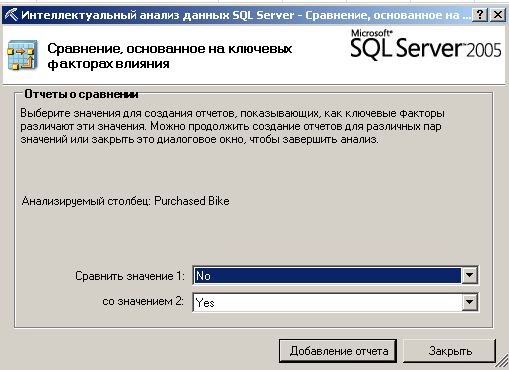
Рисунок 17
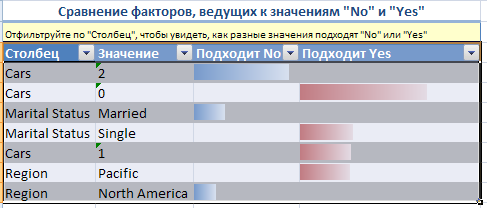
Рисунок 18
Инструмент «Анализ ключевых факторов влияния» позволяет также оценивать влияние одного фактора на другие. Для примера проведем анализ влияния на доходы (Income) покупателей других факторов (запуск анализа показан на рисунке 19).
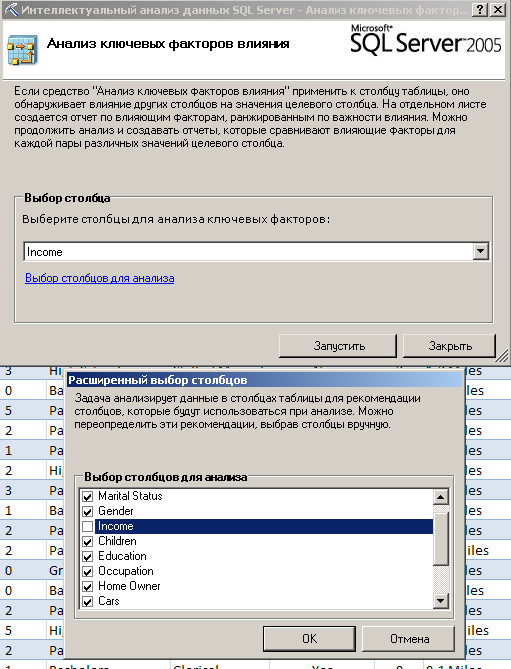
Рисунок 19
Отчет приведен на рисунке 20.
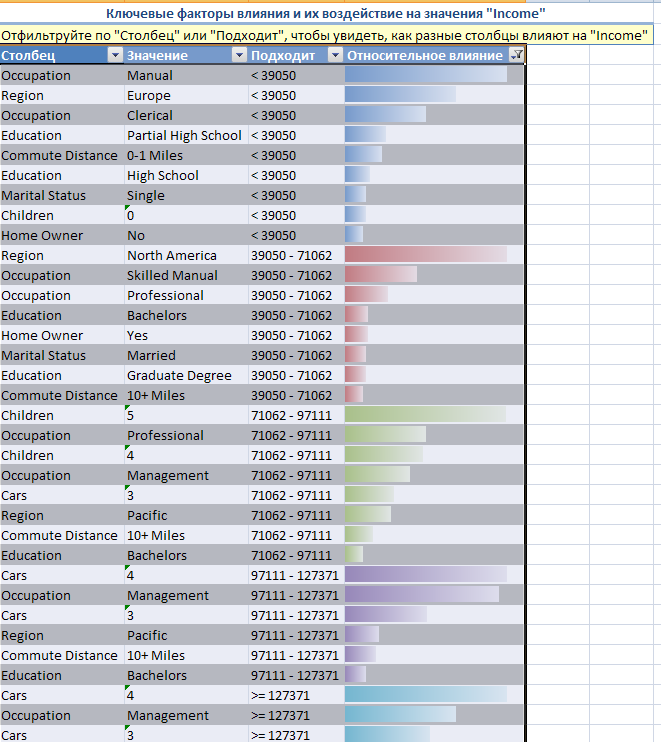
Рисунок 20
В колонке «Относительное влияние» отображается степень влияния каждого из показателей на целевой показатель (Income). Чем длиннее полоса, тем выше степень влияния соответствующего показателя.
Можно управлять видом отчета (рисунок 21). Выбран для анализа диапазон значений Income 39050-71062. Отображается степень влияния каждого из показателей на целевой показатель (Income) для заданного диапазона.
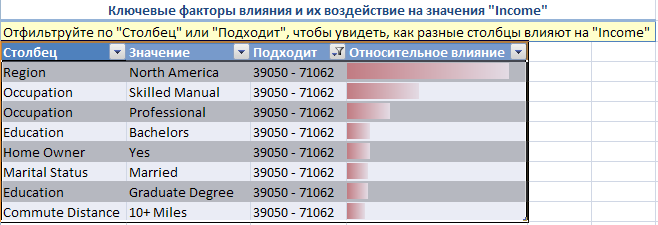
Рисунок 21
Инструмент «Поиск категорий».
Инструмент «Поиск категорий» позволяет провести кластерный анализ информации.
Исходные данные содержат информацию по автомашинам: экономичность (mpg – возможный пробег в милях на одном галлоне топлива, количество цилиндров, страна производитель - origin и др, рисунок 22).
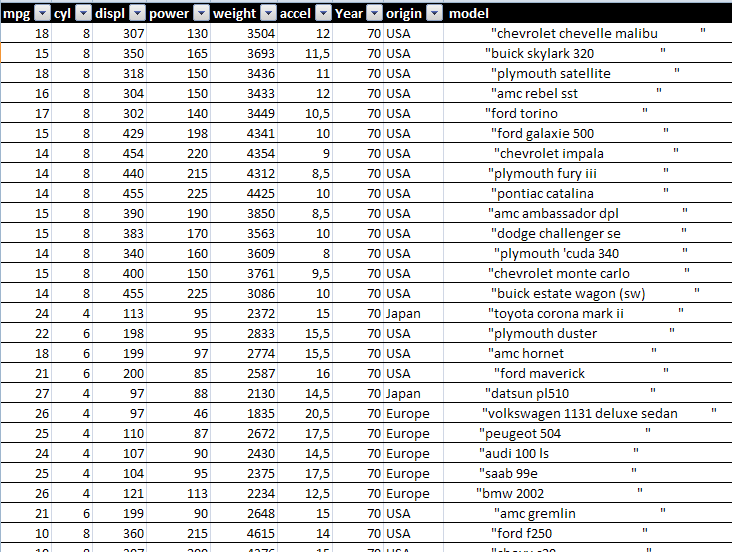
Рисунок 22
При запуске инструмента (рисунок 23) задаются включаемые в анализ параметры (не включаем в анализ год выпуска, название машины, которые не являются влияющими факторами). Также можно задать желательное число кластеров или оно будет определяться автоматически (задано 4).
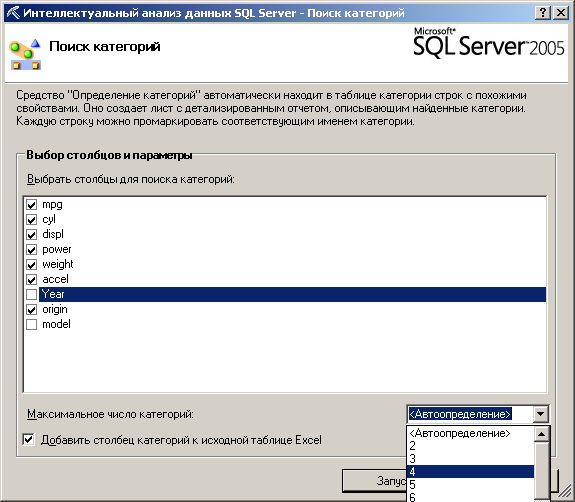
Рисунок 23
В отчете о кластерах содержится две таблицы и диаграмма профилей кластеров.
В первой таблице перечислены новые категории по временным именам по умолчанию «Категория 1», «Категория 2» и так далее. Чтобы упростить работу с категориями, можно просмотреть список характеристик и присвоить категории новое имя. Новое имя категории немедленно распространяется на другую диаграмму, а также на столбец назначения категории исходного листа данных.
Также в первой таблице отображается число строк в исходных данных, отобранных в эту категорию.
Во второй таблице «Характеристики категории» содержатся подробности о совпадениях, найденных в категории. Нажав на кнопку «Фильтр» вверху столбца «Категория», чтобы просмотреть характеристики каждой категории. Характеристики категории включают следующие сведения:
Столбец Имя столбца; как правило, атрибут, например «Cyl».
Значение Значение столбца; например 5 (количество цилиндров).
Относительная важность - Затемненная полоса, отображающая важность пары «атрибут-значение» в качестве определяющего фактора. Чем длиннее полоса, тем выше вероятность, что этот атрибут является типичным для этой категории.
После выполнения поиска принадлежность машин кластерам показывается в новом столбце исходной таблицы (Категория, рисунок 24).
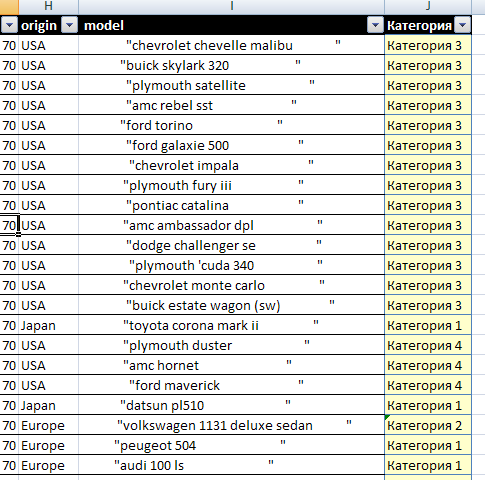
Рисунок 24
Отчет включает в себя распределение количества машин по категориям (рисунок 25), значения факторов в каждой из категорий и их относительную важность (рисунок 26).
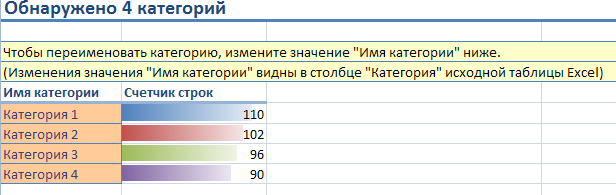
Рисунок 25
Можно применить фильтр для просмотра характеристик разных категорий.
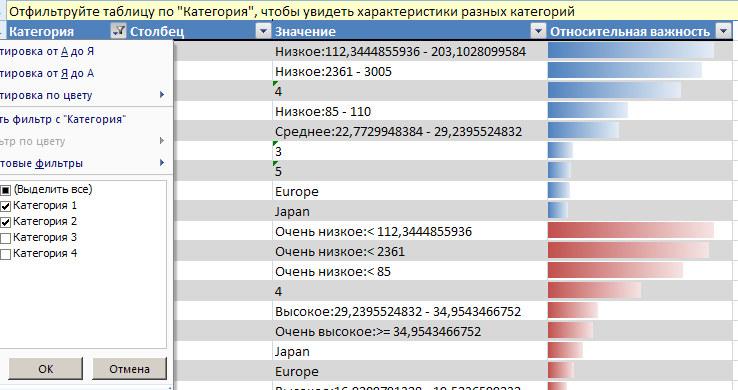
Рисунок 26
Диаграмма профилей категорий (Category Profiles Chart, рисунок 27) показывает распределение (количество строк данных) с определенной характеристикой по всем выявленным категориям. По умолчанию диаграмма отображает по умолчанию только распределение первого атрибута (на рис. 27 это Aссеl).
Каждая вертикальная полоска представляет распределение столбца внутри группы строк (одной категории или всей таблицы). Внутри вертикальной полоски каждый цветной сегмент представляет количество строк с определенным значением этого столбца. Длина сегмента представляет относительное количество (а не абсолютное число) строк текущей группы, имеющих определенное свойство.
На правой стороне диаграммы имеется легенда (в которой показано соответствие цветов различным состояниям столбца). На горизонтальной оси диаграммы указан столбец, распределение которого анализируется, и указана группа строк, которая рассматривается в каждой вертикальной полоске.
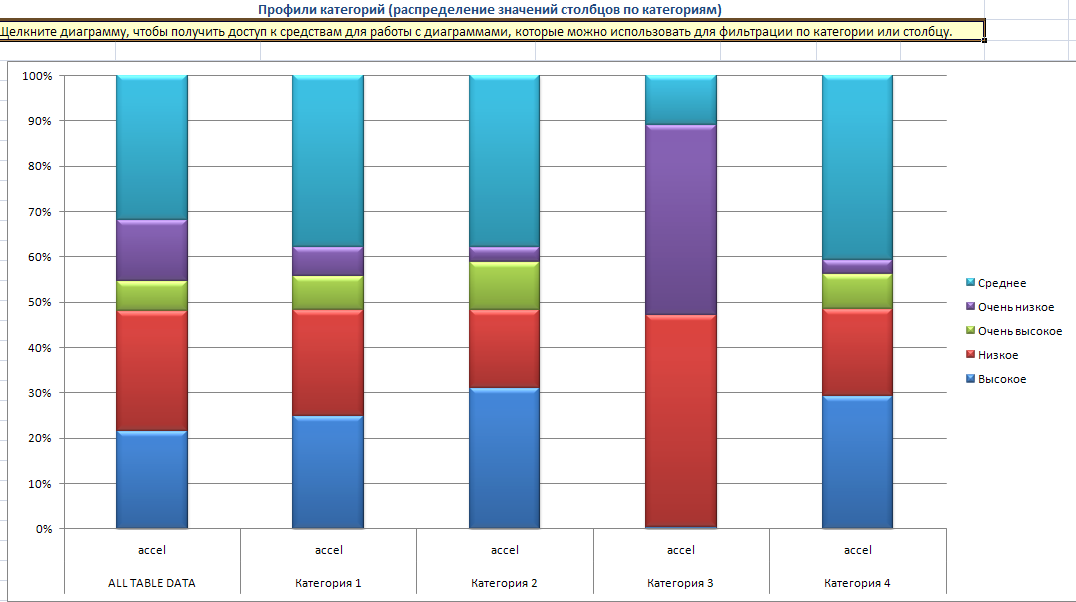
Рисунок 27
Этот тип диаграммы (называемый PivotChart - диаграмма сведения) является очень мощным инструментом, предлагаемым программой Excel. Он позволяет делать срезы данных по категориям и характеристикам и дает четкую картину распределения значений по выявленным категориям (а также и в исходной таблице Excel).
Если щелкнуть по диаграмме, то появляется элемент управления сводной таблицей, позволяющий изменить отображение профиля категорий (рис. 28). В примере выбирается распределение другого атрибута (на рис. 30 это Cyl).
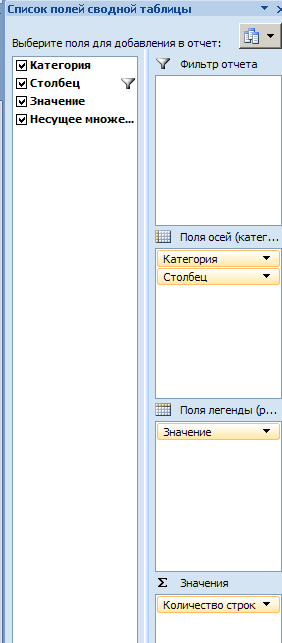
Рисунок 28
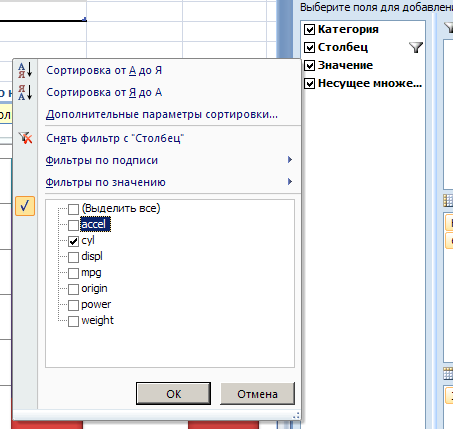
Рисунок 29
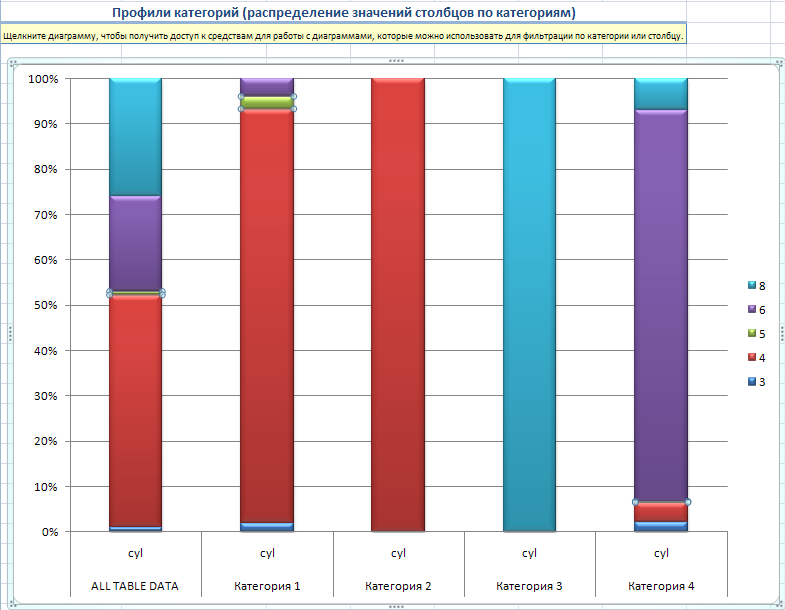
Рисунок 30