

Создание структуры.
Используется оператор CREATE MININGSTRUCTURE. В обобщенном виде его формат представлен ниже:
CREATE [SESSION] MINING STRUCTURE <structure>
(
[(<column definition list>)]
)
[WITH HOLDOUT (<holdout-specifier> [OR <holdout-specifier>])]
[REPEATABLE(<holdout seed>)]
где
<holdout-specifier>::=<holdout-maxpercent> PERCENT |
<holdout-maxcases> CASES
Приведённые в описании атрибуты имеют следующие значения:
Structure - уникальное имя структуры;
column definition list - cписок определений столбцов с разделителями-запятыми;
holdout-maxpercent - целое число от 1 до 100, которое показывает процентную долю данных, выделяемых для проверки;
holdout-maxcases - целое число, показывающее максимальное число вариантов, используемых для проверки. Если указанное значение больше числа входных вариантов, для проверки будут использованы все варианты и отобразится соответствующее предупреждение. В случае, если указаны как процентная доля, так и число вариантов, применяется меньшее из ограничений;
holdoutseed - целое число, которое используется как начальное значение при начале секционирования данных. Если оно равно 0, в качестве начального значения используется хэш идентификатора структуры интеллектуального анализа данных. Если надо гарантировать возможность повторного создания такого же разбиения (при условии, что исходные данные остались прежними), необходимо в скобках указать ненулевое целое значение.
Необязательное ключевое слово SESSION показывает, что структура является временной и ее можно использовать только в течение текущего сеанса работы с SQLServer. После завершения сеанса структура и любые модели на ее основе удаляются. Чтобы создать временные структуры и модели интеллектуального анализа данных, необходимо сначала задать свойство базы данных Allow Session Mining Models.
Надо отметить, что при использовании для анализа инструментов TableAnalysisTools из надстроек интеллектуального анализа данных для MicrosoftExcel создаются именно такие структуры.
Для определения столбца используется следующий формат:
<column name> <data type> [<Distribution>] [<Modeling Flags>] <Content Type> [<column relationship>]
где обязательно указываются <columnname> - имя столбца, <datatype> - тип данных, <ContentType> - тип содержимого. Необязательные параметры, к которым относится <Distribution> - распределение, <Modeling Flags> - список флагов моделирования, <column relationship> - связь со столбцом атрибутов (обязательна, только если применима; определяется предложением RELATED TO), будут рассмотрены ниже.
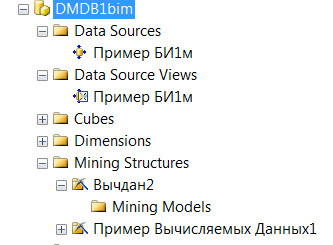
CREATE MINING STRUCTURE [Вычдан2]
(
[Код] LONG KEY,
[Аргумент1] LONG Continuous,
[Аргумент2] LONG Continuous,
[Аргумент3]LONG Continuous
)
WITH HOLDOUT(25 PERCENT) REPEATABLE(5000)

Создание модели интеллектуального анализа данных
Создание модели интеллектуального анализа данных можно осуществить одним из следующих способов:
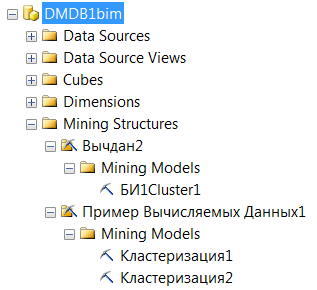
после создания структуры интеллектуального анализа данных можно добавлять в нее модели с помощью инструкции ALTER MINING STRUCTURE;
можно использовать инструкцию CREATE MINING MODEL, в результате выполнения которой создается модель и автоматически формируется лежащая в ее основе структура интеллектуального анализа данных. Имя структуры интеллектуального анализа данных формируется путем добавления строки "_structure" к имени модели.
Первый способ является более предпочтительным, особенно когда планируется создать на основе одной структуры несколько моделей (использующих разные наборы столбцов, алгоритмы и т.д.). Формат оператора представлен ниже.
ALTER MINING STRUCTURE <structure>
ADD MINING MODEL <model>
(
<column definition list>
[(<nested column definition list>) [WITH FILTER (<nested filter criteria>)]]
)
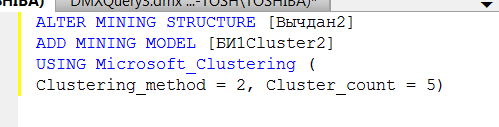
USING <algorithm> [(<parameter list>)]
[WITH DRILLTHROUGH]
[,FILTER(<filter criteria>)]
где
structure |
имя структуры интеллектуального анализа данных, к которой будет добавлена модель; |
model |
уникальное имя модели интеллектуального анализа данных; |
column definition list |
список определений столбцов с разделителями-запятыми; |
nestedcolumn definition list |
cписок с разделителями-запятыми столбцов вложенной таблицы, если применимо; |
nested filter criteria |
определение фильтра, применяющегося к столбцам вложенной таблицы; |
algorithm |
название используемого моделью алгоритма интеллектуального анализа данных; |
parameter list |
cписок параметров алгоритма (через запятую); |
filter criteria |
определение фильтра, применяющегося к столбцам таблицы вариантов. |
Если модели не требуется прогнозируемый столбец (например, при кластеризации), то в инструкцию не нужно включать определение столбца. Все атрибуты в создаваемой модели будут рассматриваться как входы, например, следующее определение модели MyCluster1 для решения задачи кластеризации:
Пример:
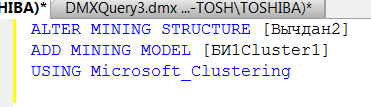
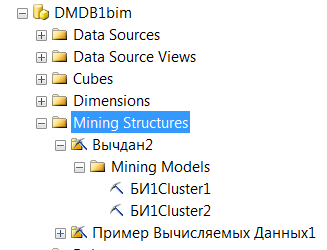
ALTER MINING STRUCTURE [Вычдан2]
ADD MINING MODEL [БИ1Cluster1]
USING Microsoft_Clustering
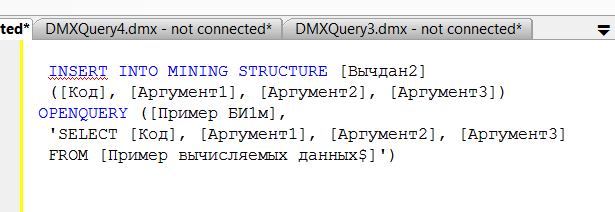
После определения структур и моделей, следующим шагом является обработка, включающая заполнение структуры интеллектуального анализа данными, применение в отношении полученных данных алгоритмов интеллектуального анализа (при обработке модели). Это делается с помощью инструкции INSERT INTO, формат которой приведен ниже:
INSERT INTO [MINING MODEL]|[MINING STRUCTURE] <model>|<structure> (<mapped model columns>) <source data query>
или
INSERT INTO [MINING MODEL]|[MINING STRUCTURE] <model>|<structure>.COLUMN_VALUES (<mapped model columns>) <source data query>
где
model |
название модели; |
structure |
название структуры; |
mapped model columns |
список через запятую с названиями столбцов, в т.ч. вложенных таблиц с их столбцами; |
source data query |
запрос, описывающий загружаемый набор исходных данных. |
Если в операторе указана структура интеллектуального анализа данных, обрабатывается эта структура и все связанные с ней модели. Если задана модель, инструкция обрабатывает только эту модель.
Прогнозирование в языке DMX.
Задача прогнозирования в языке DMX также решается с помощью оператора SELECT. При этом чаще всего используется конструкция прогнозирующего соединения - PREDICTION JOIN. С ее помощью шаблонам модели сопоставляется набор данных из внешнего источника, что позволяет определить значение для прогнозируемого столбца.
Рассмотрим теперь синтаксис SELECT, использующийся для прогнозирующего соединения.
SELECT [FLATTENED] [TOP <n>] <select expression list>
FROM <model> | <sub select> [NATURAL] PREDICTION JOIN
<source data query> [ON <join mapping list>]
[WHERE <condition expression>]
[ORDER BY <expression> [DESC|ASC]]
где
n |
целое число, указывающее количество возвращаемых строк; |
selectexpressionlist |
разделенный запятыми список столбцов и/или выражений; |
model |
название модели; |
subselect |
внедренная (вложенная) инструкция SELECT; |
sourcedataquery |
"исходный" запрос, описывающий набор данных, для которого производится прогнозирующее соединение. Исходный запрос для прогнозируемого соединения может представлять собой таблицу или одноэлементный запрос; |
joinmappinglist |
логическое выражение включающее сравнения столбцов модели со столбцами, возвращаемыми запросом sourcedataquery; определяет условия соединения; |
conditionexpression |
логическое выражение, ограничивающее множество возвращаемых значений, только теми, что соответствуют условию; условие WHERE можно применять только к прогнозируемым столбцам или к связанным столбцам; |
expression |
выражение, определяющее упорядочение возвращаемого результата. ORDER BY может принять в качестве аргумента только один столбец, т. е. нельзя сортировать по нескольким столбцам. |
Предложение ON позволяет сопоставить столбцы исходного запроса со столбцами модели интеллектуального анализа данных (чтобы определить, какие значения рассматривать в качестве входных при прогнозировании). Столбцы в списке <joinmappinglist> соотносятся с помощью знака равенства (=), как показано в следующем примере:
[MiningModel].ColumnA = [source data query].Column1 AND
[MiningModel].ColumnB = [source data query].Column2 AND
...
Инструкция NATURALPREDICTION JOIN автоматически сопоставляет имена столбцов исходного запроса, совпадающих с именами столбцов модели. В случае использования инструкции NATURALPREDICTION предложение ON можно пропустить.
Примеры построения прогнозов.
Одноэлементный запрос (прогноз в реальном времени)
Одноэлементным будем называть запрос, в котором исходные данные для прогнозирования не выбираются из источника, а явно указаны в тексте запроса. Такой запрос может формироваться "налету", например, на основе введенных пользователем данных и тут же выдавать результаты прогноза.
Ниже приведен пример подобного прогнозирующего запроса к модели [TMDecisionTree] для оценки того, станет ли покупателем велосипеда человек в возрасте 35 лет, проживающий в 2-5 милях от места работы, владеющий одним домом, двумя автомобилями, с двумя детьми в семье (значения перечислены в том порядке, как идут в листинге). Запрос возвращает прогнозируемое логическое значение столбца [BikeBuyer] и набор табличных значений, возвращенных функцией PredictHistogram, описывающих, как был сделан прогноз.
SELECT
[TM Decision Tree].[Bike Buyer],
PredictHistogram([Bike Buyer])
FROM
[TM Decision Tree]
NATURAL PREDICTION JOIN
(SELECT 35 AS [Age],
'5-10 Miles' AS [Commute Distance],
'1' AS [House Owner Flag],
2 AS [Number Cars Owned],
2 AS [Total Children]) AS t
Здесь нужно отметить, что за счет использования конструкции NATURALPREDICTION JOIN определять соответствия между столбцами модели и набора входных данных не потребовалось.
Федеральное государственное образовательное
бюджетное учреждение
высшего профессионального образования
Государственный университет
Министерства финансов Российской Федерации
Факультет прикладной информатики и математики
Кафедра «Прикладная информатика»
Кондрашов Ю.Н.
Анализ данных в электронной таблице Excel
Учебное пособие
Москва 2011
Кондрашов Ю.Н.
Анализ данных в электронной таблице Excel. Учебное пособие. - М.: изд. Государственного университета Министерства финансов Российской Федерации, 2011, 144 с.
Государственный университет Министерства финансов Российской Федерации, 2011